口碑好的网站建设网络营销的实现方式有哪些
1. Oracle高可用和ob高可用,和他们的实现方式?
2.ob的三副本了解吗,ob的三副本怎么保障强一致的?
3.三副本能实现强一致吗?
4.了解ob的数据协调协议吗?说说原理
5.聊聊Oracle,讲一些SQL调优的实际案例?
6.刚才聊到了分区表的分区裁剪,假如不调整谓词条件的情况下,有什么方法也能加速SQL?
7.并行了解吗,说一下并行的机制,怎么使用的?
8.为什么生产环境不推荐使用并行?主要对哪些资源有压力
9.redo是用来做什么的?Oracle select会写redo吗?
10.Oracle写入数据,讲一下数据落盘的过程。
11.RAC集群数据落盘的过程。
12.假如两个节点的RAC,比如一节点写了1,二节点会有什么操作?操作的顺序了解吗
13.介绍一下实习经历
14.OB三个节点如果宕机一个影响使用吗?宕机的过程中会有什么样的表现?
15.只有三个机器,一台宕机了,unit能迁移走吗?
16.现在正在往集群里面写入数据,宕机了一台,在业务端看来会有什么样的表现?
答案
1.Oracle高可用和ob高可用,和他们的实现方式?
| 数据库 | 高可用方案 | 实现原理 |
|---|---|---|
| Oracle | RAC | 多节点共享存储,通过Cache Fusion同步内存数据。故障时秒级切换,应用透明。 |
| OceanBase | 分布式Paxos协议 | 数据分片(Partition)+三副本,基于Paxos协议实现多副本强一致,无共享架构。 |
2.ob的三副本了解吗,ob的三副本怎么保障强一致的?
每个数据分片(Partition)包含3个副本(Leader/Follower/Follower)。
写入流程:
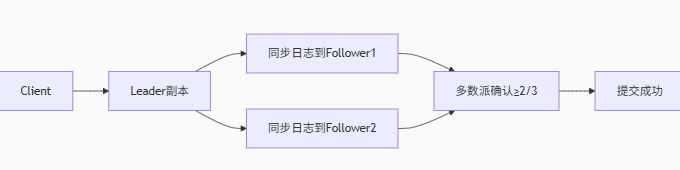
强一致保证:仅当多数副本(≥2)持久化日志后,才向客户端返回成功。
3.三副本能实现强一致吗?
能,通过Paxos协议约束: 任何写入需多数副本确认(如3副本需≥2个确认)。网络分区时,少数派副本自动拒绝写入,避免脑裂。
4.了解ob的数据协调协议吗?说说原理
Multi-Paxos优化:
-
Leader选举: 通过Paxos协议选举唯一Leader处理写入。
-
日志复制:Leader生成Redo日志并广播给Followers。
-
Followers持久化日志后返回ACK。
-
收到多数ACK后,Leader提交并应用日志。
-
日志回放: 所有副本按相同顺序应用日志,保障状态机一致性。
5.聊聊Oracle,讲一些SQL调优的实际案例?
SELECT * FROM sales WHERE TO_CHAR(sale_date,'YYYY-MM') = '2023-10'; -- 函数导致裁剪失效
优化:
SELECT * FROM sales WHERE sale_date BETWEEN DATE'2023-10-01' AND DATE'2023-10-31'; -- 直接范围查询
6.刚才聊到了分区表的分区裁剪,假如不调整谓词条件的情况下,有什么方法也能优化SQL?
-
全局索引: 避免分区键限制。
-
本地索引分区: 每个分区独立索引,加速扫描。
-
统计信息更新: DBMS_STATS.GATHER_TABLE_STATS确保优化器准确选择分区。
-
SQL Profile: 使用SQL Tuning Advisor固定高效执行计划。
7.并行了解吗,说一下并行的机制,怎么使用的?
启用并行:
ALTER SESSION ENABLE PARALLEL DML;
SELECT /*+ PARALLEL(emp, 4) */ * FROM emp; -- 强制4个并行进程
资源控制:
PARALLEL_DEGREE_POLICY: 控制并行度策略(AUTO/MANUAL)。
PARALLEL_SERVERS_TARGET: 限制并行服务器数。
8.生产环境不推荐并行的原因
-
CPU: 并行进程争抢CPU,导致系统负载飙升。
-
I/O: 大量并行扫描引发存储吞吐瓶颈。
主要原因是CPU和IO,内存方面不是主要原因。
-
内存: 每个并行进程消耗PGA内存,可能触发ORA-4030。
-
锁竞争: 并行DML加剧锁冲突(如TX锁)。
9.redo是用来做什么的?Oracle select会写redo吗?
核心功能: 记录所有数据变更(DML/DDL),用于故障恢复。
SELECT语句不会直接生成redo日志,因为它们不修改数据库内容。但在维护读一致性、使用直接路径读取、执行递归SQL以及触发PL/SQL函数或数据库触发器时,可能会间接产生redo日志。
具体原因参考文章: select会写redo吗
10.Oracle写入数据,讲一下数据落盘的过程。
-
用户提交DML。
-
日志写入Log Buffer。
-
LGWR将Log Buffer刷新到Redo Log文件(优先保证日志落盘)。
-
DBWR将脏块从Buffer Cache写入数据文件(异步进行)。
11.RAC集群数据落盘的过程。
| 阶段 | 关键组件 | 工作流程设计目标设计目标 | 设计目标 |
|---|---|---|---|
| 1. 数据块传递 | Cache Fusion | 1. 节点A修改数据块时,通过私网(Interconnect)将块副本传输给请求节点B2. GCS 跟踪块状态(CR/XD 模式)3. 块在内存间直接传递,避免磁盘 I/O | 减少共享存储访问提升并发性能 |
| 2. Redo 日志落盘 | ASM 存储 | 1. 每个节点独立写入本地 Redo 日志线程2. 日志写入共享存储(ASM 磁盘组)3. 提交时强制刷盘(Commit = Log Written) | 确保事务持久性节点故障时恢复 |
| 3. 脏块写入 | DBWR 进程 | 1. GCS 协调脏块刷盘顺序2. 持有最新版本的节点执行写盘3. 写入共享数据文件(ASM) | 保证数据一致性减少写冲突 |
| 4. 全局一致性 | GCS + GES | 1. GES 管理全局锁(如 TX 锁)2. GCS 协调块访问权3. 通过块版本号解决冲突 | 跨节点读一致性 写操作串行化 |
12.假如两个节点的RAC,比如一节点写了1,二节点会有什么操作?操作的顺序了解吗
场景:节点1写入数据块A(值为1)
-
节点1持有A的Exclusive锁。
-
节点2请求修改A:
-
通过GCS向节点1请求块副本。
-
节点1将A的当前版本+锁信息传递给节点2。
-
节点2在本地缓存中修改A,生成Redo日志并落盘。
-
节点2通过GCS广播块变更信息。
13.介绍一下实习经历
省略
14.OB三个节点如果宕机一个影响使用吗?宕机的过程中会有什么样的表现?
-
宕机一个节点:
无影响: 剩余2节点满足多数派(2/3),服务正常。
Leader切换: 宕机节点若含Leader副本,5秒内自动选举新Leader。
-
宕机过程表现:
客户端连接该节点的会话断开(需重试)。 其他节点短暂写入延迟(Paxos重新协商)。
1.如果是三个单zone单observer是一份数据。如果某OBServer挂掉了,且超过 server_permanent_offline_time时间限制会永久下线,需要把这个单zone单observer下掉。重新部署上去。
2.如果是三个单zone多observer,且primary_zone 为 RANDOM 时,ob数据是以分布式存储的(以分区形式来的,按分区的粒度自动均衡到不同的OBServer节点,打散数据)
15.只有三个机器,一台宕机了,unit能迁移走吗?
-
当某个OBServer节点挂掉时:
多副本机制:ob通常会在不同的OBServer上存储数据的多个副本(通常是3个副本)。这意味着即使一个节点失败,其他节点上仍然有数据的副本。
数据同步:在节点恢复后,ob会自动同步该节点上的数据,确保所有节点上的数据副本保持一致。
在官网论坛上找到的,所以结论应该是没有迁移走。。
16.现在正在往集群里面写入数据,宕机了一台,在业务端看来会有什么样的表现?
-
客户端视角:
短时报错(如Connection reset),持续约1-5秒。
自动恢复: OBProxy 自动重试请求到新Leader。
-
数据一致性:
已提交的数据不丢失(多数副本已持久化)。
未提交的事务自动回滚。