网站建设siteserver织梦图片自适应网站源码
一、 组别
Web应用开发分为:大学组和职业院校组。
每位选手只能申请参加其中一个组别的竞赛。各个组别单独评奖。
研究生和本科生只能报大学组。
其它高职高专院校可自行选择报任意组别。
二. 竞赛赛程
省赛时长:4小时。
决赛时长:4小时。
详细赛程安排以组委会公布信息为准。
三、竞赛形式
个人赛,省赛、决赛均采用封闭、限时方式进行。
选手机器通过局域网连接到各个考场的比赛服务器。
选手答题过程中不允许访问互联网,也不允许使用本机以外的资源(如USB连接)。
比赛系统以“服务器-浏览器”方式发放试题、回收选手答案。
选手将答案提交到比赛系统中,超过比赛时间将无法提交。
四、 参赛选手机器环境
选手机器配置:
X86兼容机器,内存不小于4G,硬盘不小于60G
操作系统:Windows7、Windows8、Windows10或Windows11
显示器:分辨率1024*768像素或以上
Web****前端开发环境:
(1)Google Chrome浏览器(正式版,v90以上版本),
官方下载:https://www.google.cn/chrome
(2)Visual Studio Code代码编辑器(正式版,v1.36以上版本),
官方下载:https://code.visualstudio.com
在Visual Studio Code安装Live Server插件,
官方下载:https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer
(3)Node.js环境(正式版,v12.x 以上版本),
官方下载:https://nodejs.org/zh-cn/download/
(4)支持压缩.zip压缩包的压缩软件(7-Zip 16.04及以上版本),
推荐使用免费开源软件:https://www.7-zip.org
五、试题形式
试题均为场景实战题(编程实操),选手根据需求说明,通过完善程序代码、配置和管理项目的形式排除程序错误或完成预期需求。
场景实战题
场景实战题目均包含完整的题面PDF文档(Google Chrome支持浏览PDF)和基础源代码压缩包。题面文档中会详细说明题目的背景、需求、目标。选手需认真读题,结合题目给出的基础源代码,通过修改、新增代码来实现题目给出的最终目标。
部分题目可能包含前序准备步骤。例如,解压缩相应的资源文件,在浏览器中预览网页效果等。大部分情况下,我们默认选手已经掌握了前端开发过程中可能涉及的基础知识和方法,不会给予单独的提示。同时,题目不会给予IDE开发工具的使用方法提示。
特别说明:基础源代码在无明确说明的情况下,请勿随意修改文件名称、文件夹名称、文件存放结构。务必严格规范根据题意操作,否则可能会影响最终阅卷的准确性。
六、试题考查范围
试题考查选手解决实际问题的能力,侧重考查选手阅读、分析、理解需求,实现功能性需求(静态、动态页面效果,API开发与调用),实现非功能性需求(如兼容性、安全性、性能),产品交付(打包、部署)等方面的能力。知识范围包括但不限于:
| 参赛组别 | 考察知识范围 |
|---|---|
| 职业院校组 | HTML5、CSS3、JavaScript、ES6、Axios、Vue.js(v3.0+)、ElementPlus(v2.3.6+)、ECharts(v5+) |
| 大学组 | HTML5、CSS3、JavaScript、ES6、Axios、Vue.js(v3.0+)、ElementPlus(v2.3.6+)、ECharts(v5+)、Node.js(v12.x) |
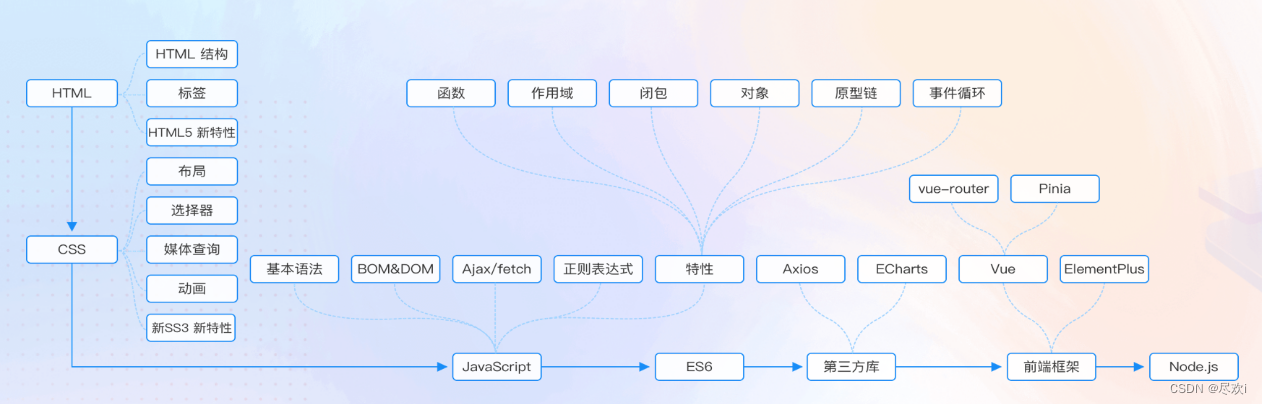
| 考察点 | 知识点 |
|---|---|
| HTML5、CSS3 | 1.HTML 基础标签2.HTML5 新特性3.HTML5本地存储4.CSS 基础语法5.盒子模型6.浮动与定位7.CSS3 新特性8.弹性盒子9.媒体查询 |
| JavaScript | 1.JavaScript 基础语法2.DOM 与 BOM3.JavaScript 内置对象4.JavaScript 事件5.JavaScript AJAX6.正则表达式 |
| ES6 | 1.let 和 const 命令2.class3.set和map4.Proxy5.字符串、函数、数组和对象的扩展6.异步编程与模块化 |
| Axios | 1. Axios API2. Axios 实例3. 请求配置4. 默认配置5. 拦截器 |
| Vue.js | 1.Vue 核心(常用指令、常用模板语法、生命周期、数据渲染、事件绑定、自定义指令、组合式函数、插件等)2.Vue 组件(组件定义及使用、父子组件、兄弟组件、异步组件、组件插槽、依赖注入等)3.vue-router(v4.x)使用4.pinia 使用 |
| ElementPlus | 1.基础组件的使用2.表单和表格组件3.反馈组件4.导航组件 |
| ECharts | 1.ECharts 基础语法2.ECharts 绘制图表3.ECharts 异步数据加载和更新4.ECharts 交互组件5.ECharts 事件处理 |
| Node.js | 1. Node.js 基础2.内置模块使用(fs、http等) |
七、 答案提交
选手只有在比赛时间内提交的答案内容是可以用来评测的,比赛之后的任何提交均无效。选手应使用考试指定的网页来提交代码,任何其他方式的提交(如邮件、U盘)都不作为评测依据。
选手可在比赛中的任何时间查看自己之前提交的代码,也可以重新提交任何题目的答案,对于每个试题,以最后一次提交作为评测的依据。在比赛中,评测结果不会显示给选手,选手应当在没有反馈的情况下自行调试。
最后,由于题目考察内容的差异,每道题目最终需提交的资料和步骤均会在题面PDF文档中详细说明,请严格按照相应要求进行操作。
八、评分
全部题目将使用前端自动化测试技术完成机器自动评分。
对于功能实现类型的题目,我们会基于单独的测评数据来测试功能实现的完整性。
对于页面布局类型的题目,我们会基于最终效果和目标效果的相似度进行评分。
九、其它注意事项
(1)选手必须符合参赛资格,不得弄虚作假。资格审查中一旦发现问题,则取消其报名资格;竞赛过程中发现问题,则取消竞赛资格;竞赛后发现问题,则取消竞赛成绩,收回获奖证书及奖品等,并在大赛官网上公示。
(2)参赛选手应遵守竞赛规则,赛场纪律,服从大赛组委会的指挥和安排,爱护竞赛赛场地的设备。
(3)竞赛采用机器阅卷加少量人工辅助的方式。选手需要特别注意提交答案的形式。必须仔细阅读题目的要求和示例,不要随意添加不需要的内容。
十、样题 A:用户名片
介绍
CSS 样式是前端开发的必备技能之一,下面请用你丰富的经验帮小蓝完成一个漂亮的用户名片制作吧。
准备
开始答题前,需要先打开本题的项目代码文件夹,目录结构如下:
├── css
│ └── style.css
├── images
└── index.html
其中:
· css/style.css 是样式文件。
· images 是页面布局需要用到的图片素材。
· index.html 是主页面。
在浏览器中预览 index.html 页面效果如下:
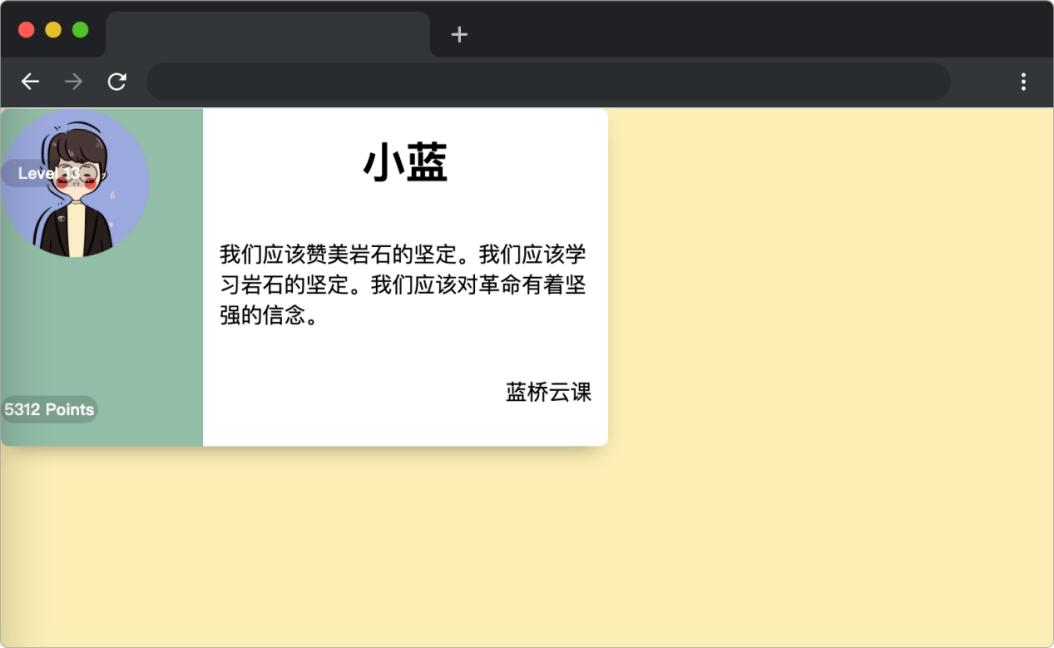
目标
请通过补充或者修改 css/style.css 中的样式(注意:不要修改元素大小),达到以下效果:
\1. 实现卡片(class = card) 和用户头像(class = avatar) 元素水平垂直居中。
\2. 左侧文字(class = level 和 class = points)水平居中。
完成后,最终页面效果如下:
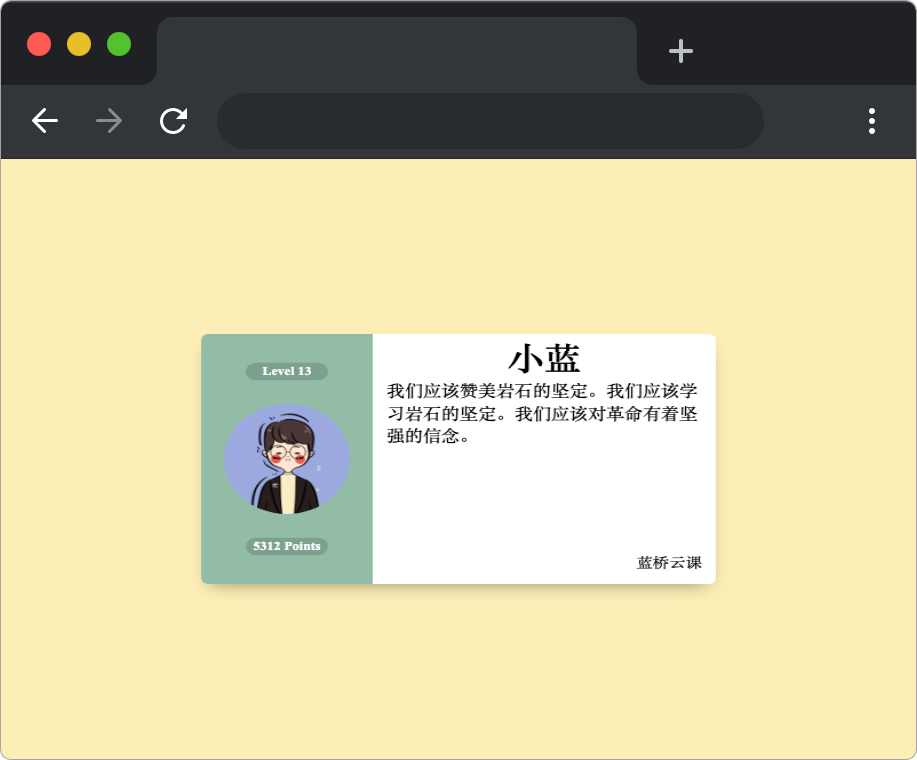
规定
请勿修改已经提供的代码,以免造成判题无法通过。
请严格按照考试步骤操作,切勿修改考试默认提供项目中的文件名称、文件夹路径等。
判分标准
· 本题完全实现题目目标得满分,否则得 0 分。
答案提交
e-49ff-a100-0d5635d15246.png" alt=“img” style=“zoom:33%;” />
规定
请勿修改已经提供的代码,以免造成判题无法通过。
请严格按照考试步骤操作,切勿修改考试默认提供项目中的文件名称、文件夹路径等。
判分标准
· 本题完全实现题目目标得满分,否则得 0 分。
答案提交
本题请勿新增、修改基础源代码中的文件名称、文件夹名称、文件存放层级结构。最后将答题后的01文件夹压缩成 01.zip 压缩包(请务必使用.zip格式,其他压缩包格式无法正常判卷)后提交。