wap网站开发自适应手机屏幕开源包小程序推广方式
老板键工具来唤去: 它可以为常用程序自定义快捷键,实现一键唤起、一键隐藏的 Windows 工具,并且支持窗口动态绑定快捷键(无需设置自动实现)。
卸载工具 HiBitUninstaller: Windows上的软件卸载工具
《乐高地平线大冒险》为何不登陆Xbox:目前没有消息要宣布
在今年的夏日游戏节上,索尼正式公布了《乐高地平线大冒险》,这是游骑兵工作室旗下游戏《地平线》系列的衍生作品,与荷兰开发商Studio Gobo合作打造,将登陆PS5、PC和Switch,考虑到《地平线》是索尼第一方IP,登陆PS5、PC很符合索尼当前的策略,而Switch确实是一个惊喜,但还有玩家好奇为什么《乐高地平线大冒险》唯独不登陆Xbox。

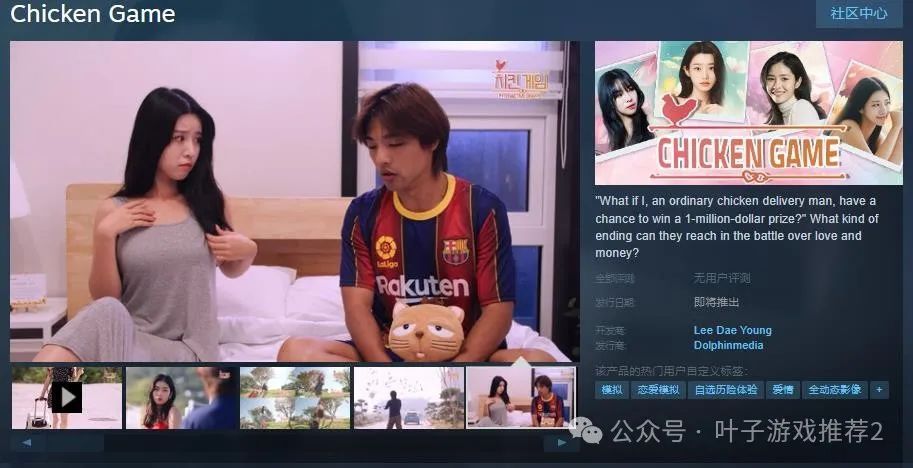
韩国真人互动影游《Chicken Game》Steam页面 发售日期待定
今日(7月5日),韩国真人互动影游《Chicken Game》Steam页面上线,发售日期待定,支持简体中文,感兴趣的玩家点击此处进入商店页面。
开发商D3 Publisher注册新商标 或是未公开新作
根据外媒Gematsu的报道,开发商D3 Publisher在日本注册了一个新商标“デビュープロジェクト クッキングカフェ”,直译过来就是“出道计划:咖啡烹饪”,该商标于6月27日提出申请,7月5日正式公开,这有可能是D3 Publisher正在开发一款新作。

《腐蚀》7月更新预告 添加新载具摩托车和自行车
7月5日,开发商Facepunch Studios发布了《腐蚀》7月更新“ROAD RENEGADES”的预告视频,在本次更新中将添加全新载具:摩托车和自行车,并新增物品手铐和囚犯头巾。

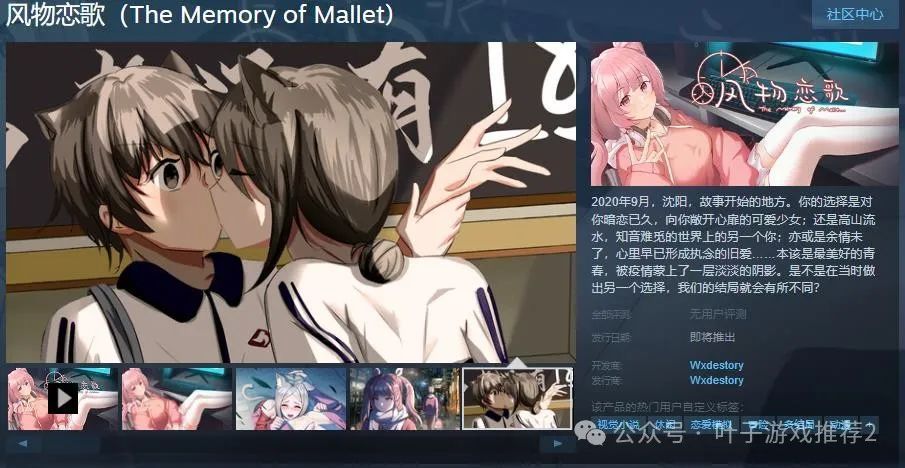
恋爱游戏《风物恋歌》Steam页面上线 支持简体中文
今日(7月5日),恋爱模拟游戏《风物恋歌》Steam页面上线,游戏支持简体中文,感兴趣的玩家可以点击此处进入商店页面。
玩家吐槽《七龙珠 电光炸裂!ZERO》人物定制界面与《堡垒之夜》完全一致
《龙珠》改编游戏系列新作《七龙珠电光炸裂!ZERO》即将在10月11日于PC、PS5和Xbox Series X|S上发售,近日万代南梦宫发布的游戏“新手指南”中,展示了游戏里人物的定制界面,但却受到了不少玩家的吐槽。

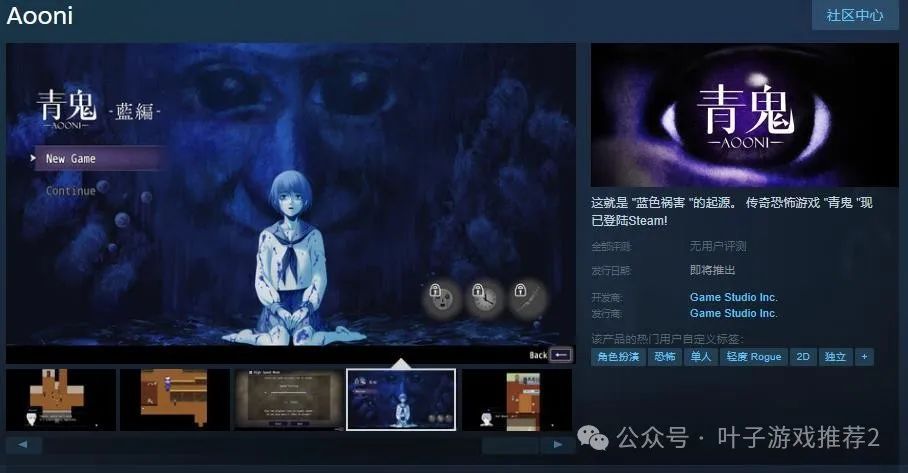
传统恐怖游戏《青鬼》Steam页面上线 支持中文
今日(7月5日),传统恐怖游戏《青鬼》Steam页面上线,游戏支持简繁体中文,7月26日发售,感兴趣的玩家可以点击此处进入商店页面。
《虹吸战士》开发者:《合金装备》的发布让我很绝望
《合金装备》在 1997 年 E3 上的亮相产生了巨大的影响,尤其是对于同样正在制作间谍主题动作游戏的索尼开发者。

这才8岁?自闭症儿童初见就击败《艾尔登法环》BOSS“碎星拉塔恩”
“黄金树幽影”发售后的难度问题引起了不小的争议,而《艾尔登法环》游戏的本体也有着较高的难度,不少玩家都在游戏中受过苦。

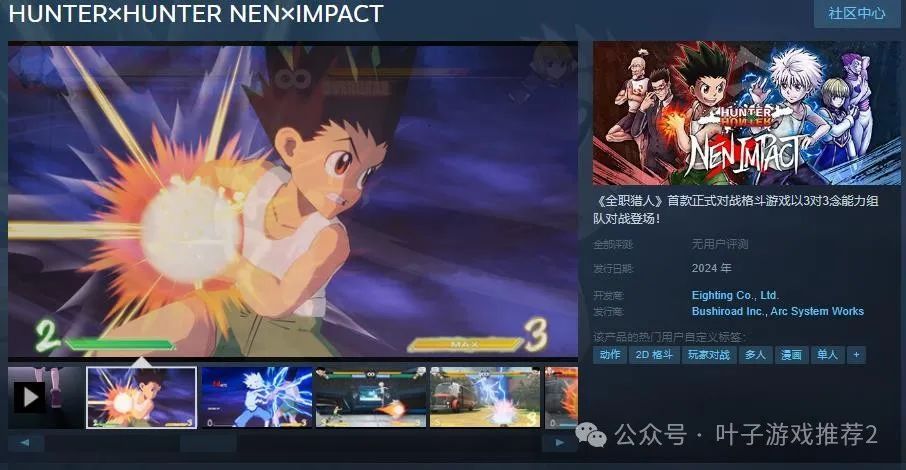
《HUNTER×HUNTER NEN×IMPACT》Steam页面上线 年内推出
今日(7月5日),《全职猎人》首款正式对战格斗游戏《HUNTER×HUNTER NEN×IMPACT》Steam页面上线,游戏支持简繁体中文,2024年正式上线,感兴趣的玩家可以点击此处进入商店页面。
《电锯甜心RePOP》主角新配音为田村由香里 支持更换旧版配音
根据《电锯甜心RePOP》制作人安田善已的消息,在本次的复刻版中主角朱丽叶的日版配音将由声优田村由香里担任,不过玩家也可以选择切换到旧版本:PS3版配音日笠阳子和Xbox 360版配音喜多村英梨。另外,朱丽叶的英配Tara Strong也是可选配音之一。

坂口博信沉迷FF14:同事需要上线提醒他开会
在 2004 年离开 SE 并创立了 Mistwalker 工作室后,系列创始人坂口博信并没有打算再回归《最终幻想》的开发,但他非常喜欢系列的 MMO《最终幻想14》,每天会玩 12 个小时,并且还会和游戏总监吉田直树一起在游戏舞台上现身。

日本老牌外包工作室东星软件面临财务困境 受大厂项目取消影响
近年来游戏行业不断裁员和取消项目,不少工作室都受到影响,虽然日本方面由于当地劳动法的效力,使得大规模裁员情况相对较少,但近日老牌外包工作室东星(Tose)软件却陷入了财务困境。

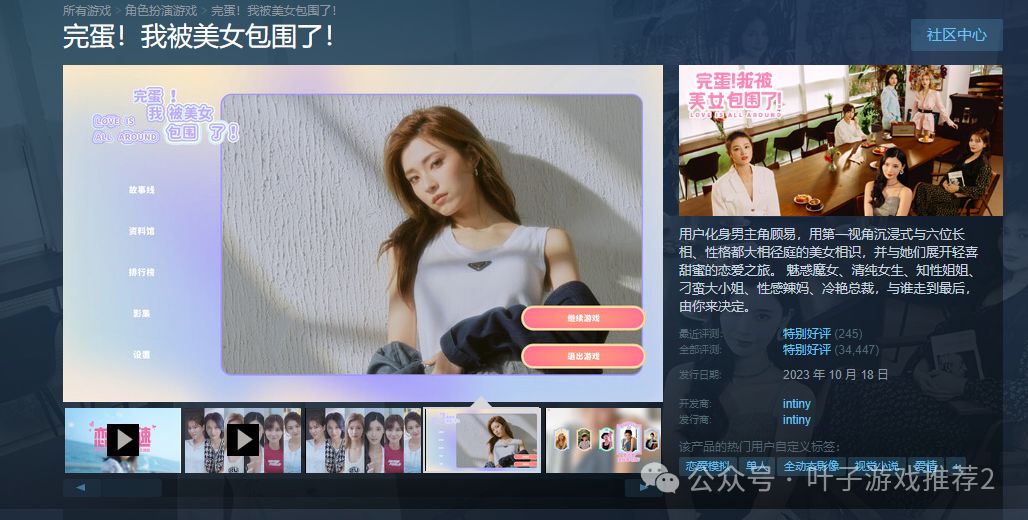
真正的真人互动影像“游戏”?国产新游《失业了,我获得了亿万游戏财产!》值得各位绅士细品~
如果提到近两年爆火的游戏类型,真人互动影像游戏一定是个绕不过去的名字。仅仅是去年10月的《完蛋!我被美女包围了!》,就以一己之力创造了国产电子史上的奇迹,2023年12月,该游戏获得2023年Steam大奖“杰出剧情游戏奖”的提名。销量更是排到了2023国产游戏第二名,取得了190万销量的好成绩。
为了规避索尼监管 PS5开发机被以“披萨套件”的名义售出
近日,有网友发现一位PS5开发机的持有者在eBay上将该机器以“披萨套件”的名义出售了,PS5开发机上有一个独特的V形冷却凹槽,看起来类似罗马数字5,但玩家更想将其比作一个非常适合放置披萨片的地方。

免费肉鸽射击游戏《披萨英雄》已在Steam平台正式推出 已获好评
由Astro Hound打造的免费肉鸽射击游戏《披萨英雄(Pizza Hero)》,现已在Steam平台正式推出并收获好评。需要注意的是,游戏目前仅支持英文界面、完全音频和字幕。

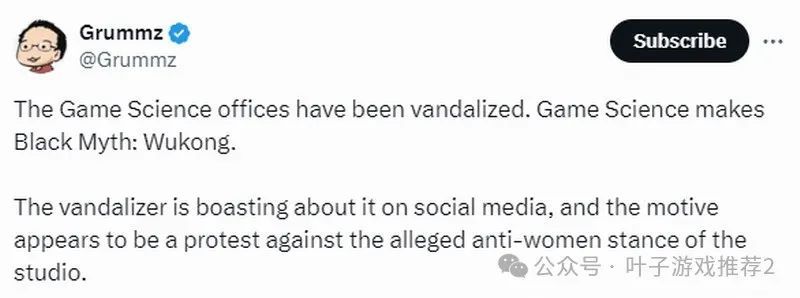
游戏科学公司门口被人恶意涂鸦 抗议歧视女性?
近日推特主Grummz在推特上发文称:“近日,《黑神话:悟空》开发商游戏科学深圳公司门口被人恶意涂鸦。此人在推特上大肆宣扬这件事情,其动机似乎是抗议该工作室‘歧视女性’立场。”
《第一后裔》再次遇到服务器问题:由于网络压力
由 Nexon Games 开发的新作《第一后裔》已经发布就获得了大量玩家,但也因此遭遇了服务器问题。日前游戏遇到了服务器问题,据报道玩家在尝试加载游戏时会收到“停机维护”的通知。

成本决定一切?谁说高投入的游戏不会成为“粪作”!
2024已经过半,上半年的游戏阵容是十分强大,诞生了不少的佳作。可以发现,在今年有很多小型团队开发的如《幻兽帕鲁》、《绝地潜兵2》、《星刃》等作品,却可以碾压众多高成本的3A。

第一人称射击游戏《灵魂射手:死亡使者》重大更新!
《灵魂射手:死亡使者》(Soulslinger: Envoy of Death)是一款第一人称射击类的Roguelike游戏,该游戏深受《荒野大镖客》系列启发。在游戏中玩家将扮演一个困在地狱中的神枪手。

为何我对肉鸽游戏如此上头,甚至无法自拔?
再来一把,反正时间还早……什么!我才玩了一会怎么天就亮了!

《喷射战士3》全新夏夜祭典活动开启投票!下周举办
《喷射战士3》新一轮分区祭典活动现已开启投票,准备祭正式开启,想参加的小伙伴们不要错过。

《Bodycam》紧急更新:移除新纳粹符号 作者迅速调整
由虚幻5引擎开发的超现实多人第一人称射击游戏——《Bodycam》近日进行了一波更新,更新内容包括了一张新地图。但是,新地图中包含的许多“1488”符号涂鸦引起了广大网友的热议。

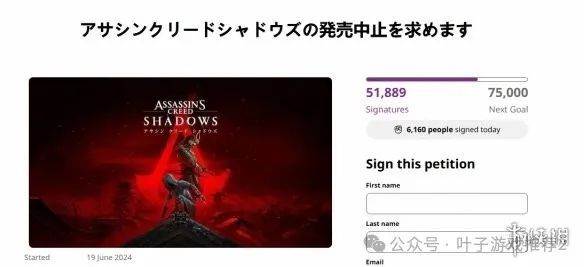
请尊重历史!日本玩家群情激愤 呼吁取消《刺客:影》
此前游侠网曾报道,有日本玩家在请愿网站change.org上发起了一项请愿活动,截止今日发稿时,请愿书上的数字再次增长了一倍多:目前请愿人数为51889人,已超5万人大关,下一个阶段目标为75000人。
《绝区零》公布艾莲宣传片:鲨鱼就是会咬人的哦!
《绝区零》已经于昨日正式公测,今日(7月5日),官方发布“艾莲特辑”宣传视频,大家一起看一下吧!

跑团游戏《人格解体》将于8月加入大型新模组「卡森德拉」
由喵法自然工作室开发,Gamera Games发行的跑团游戏《人格解体》于今日发布了一支全新宣传,预告了即将于8月推出的大型模组「卡森德拉的黑色嘉年华」(下简称「卡森德拉」),并确认届时本作也将结束抢先体验,转为1.0正式版。

MOD制作人想将《上古卷轴》带入《星空》 却无奈放弃
上周,Reedit的用户“New-Star-340”宣布了一个雄心勃勃的项目,将把整个Tamriel带到Starfield,换句话说,就是将上古卷轴《天际》、《晨风》和《湮灭》带到《星空》。但是却在不到一周的时间里,模组制作者宣布取消这个项目。

异世界探险新游《异世界边境》正式开启免费试玩Demo版
就在近日一款全新的异世界冒险游戏《异世界边境》正式的开启了游戏的试玩Demo下载。

《恐怖惊魂夜×3》加长版宣传片赏!系列30周年纪念作
Spike Chunsoft公布了《恐怖惊魂夜×3》加长版宣传片,让我们一起来看看吧!

《燕云十六声》公测延期 官方表示:延期1天送1克黄金
今日,国产开放世界RPG武侠游戏《燕云十六声》发布公告,原定于7月26日开启的公测决定延期。

人气生存模拟经营游戏《汉尘:腐草为萤》开启Demo试玩
就在最新一款超人气的生存模拟经营游戏《汉尘:腐草为萤》正式的开启了Demo试玩。

基建人基建魂!模拟游戏《宇宙矿工》Steam页面上线
近日,由Dotsoft Games开发、发行的星际基建游戏《宇宙矿工》上线Steam页面,预计于明年推出。游戏中,玩家独自在星球上开采资源,为了谋求自己的生路,你需要竭尽全力。

以上内容来源: 游侠, 3DM