邢台网站建设费用免费手机网站建设
前言:
我们在进行web开发时,基本上一个接口对应一个实现类,比如IOrderService接口对应一个OrderServiceImpl实现类,给OrderServiceImpl标注@Service注解后,Spring在启动时就会将其注册成bean进行统一管理。在Controller层需要使用到Service层的服务组件时,就通过@Autowired或@Resource等注解标注接口,Spring会自动为我们注入接口的实现类。
OrderController:
@RestController
@RequestMapping("/order")
public class OrderController{@AutowiredIOrderService orderService;@GetMapping("{id}")public Order getOrder(@PathVariable("id") Integer id){return orderService.getOrderById(id);}}OrderServiceImpl:
@Service
public class OrderServiceImpl implements IOrderServiceImpl{@AutowiredOrderDao orderDao;@Overridepublic Order getOrderById(Integer id){if(id != null)orderDao.getById(id);}}在IOrderService接口只有一个实现类:OrderServiceImpl时,这么写当然没有问题。如果我们编写了多个IOrderService接口的实现类,在不同场景需要使用不同实现类,这么写还能行吗?肯定不能!
原因:@Autowired注解注入的方式是by type按类型注入,一个接口如果存在多个实现类,Spring将不知道应该注入哪个实现类,在启动阶段就会报错。
@Autowired:
@Target({ElementType.CONSTRUCTOR, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Autowired {boolean required() default true;
}其中还有一个required属性,默认为true,表示强制要求Bean实例的注入,如果IOC容器不存在对应类型的Bean,Spring启动时就会报错。
解决方案:
(1)在使用@Service注解配置实现类时,声明bean的名称,并使用@Qualifier注解注入对应的实现类。
OrderServiceImpl1:
//指定名称
@Service("orderServiceImpl1")
public class OrderServiceImpl implements OrderService {@Overridepublic String sayHello() {return "实现类1 say Hello";}}OrderServiceImpl2:
//指定名称
@Service("orderServiceImpl2")
public class OrderServiceImpl2 implements OrderService {@Overridepublic String sayHello() {return "实现类2 say Hello";}
}OrderController:
@RestController
@RequestMapping("/order")
public class OrderController {@Autowired@Qualifier("orderServiceImpl1")//使用指定名称的bean示例作为实现类OrderService orderService;@GetMapping("/test")public String test(){return orderService.sayHello();}}启动Spring,并使用Postman测试接口,测试结果:
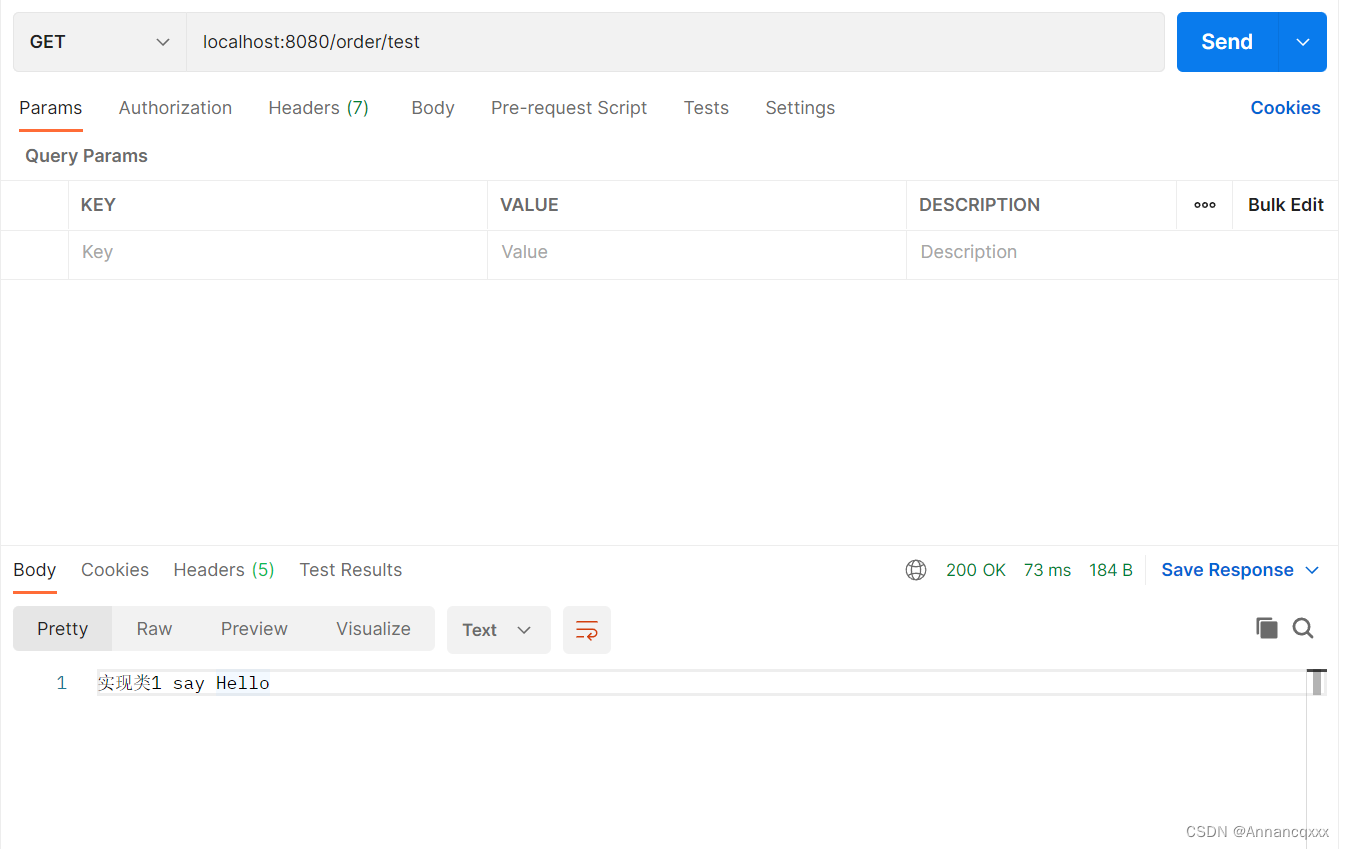
修改Qualifier注解为:@Qualifier("orderServiceImpl2"),重启Spring,再次测试接口,测试结果:
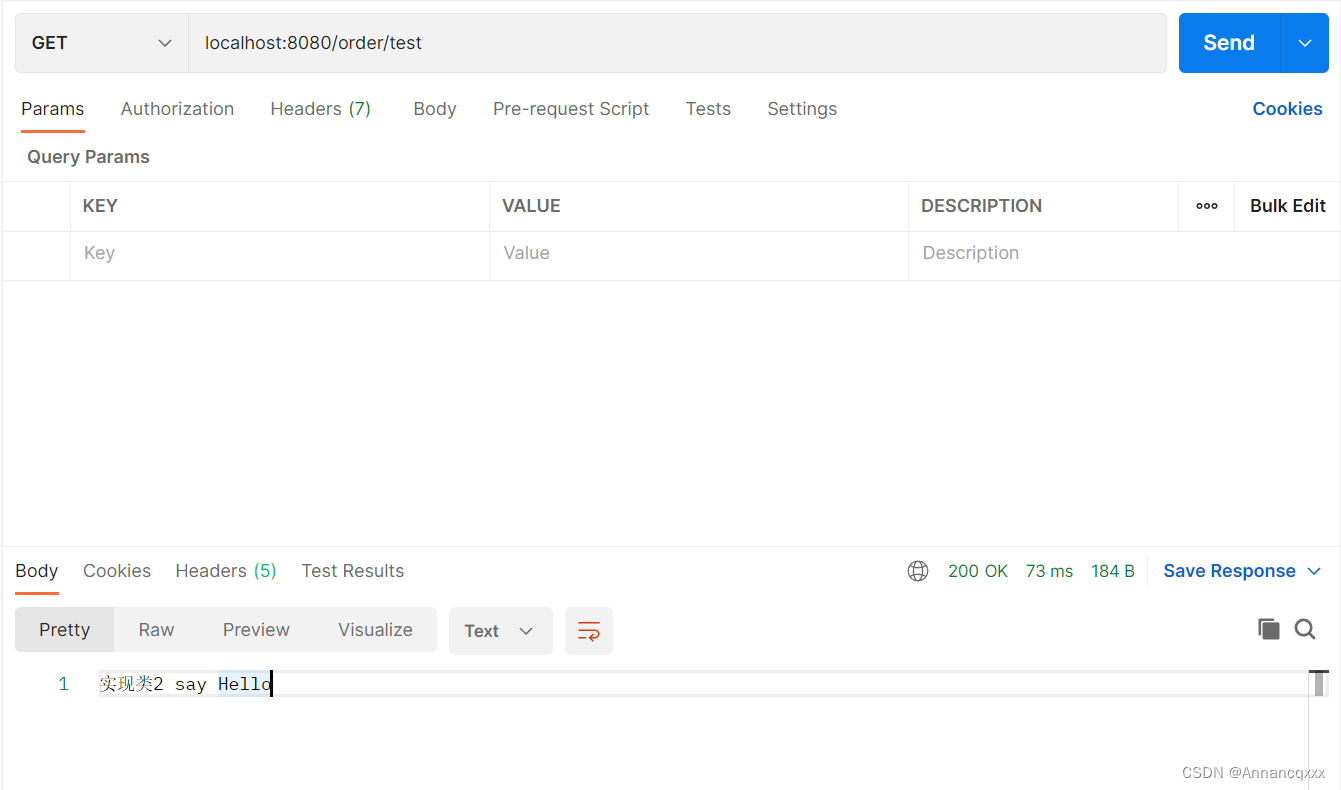
可以看到Spring容器为OrderService接口注入了不同的实现类。
(2)使用@Resource注解。
OrderController:
@RestController
@RequestMapping("/order")
public class OrderController {@Resource(name = "orderServiceImpl2") //指定使用哪一个bean作为实现类OrderService orderService;@GetMapping("/test")public String test(){return orderService.sayHello();}}测试结果:
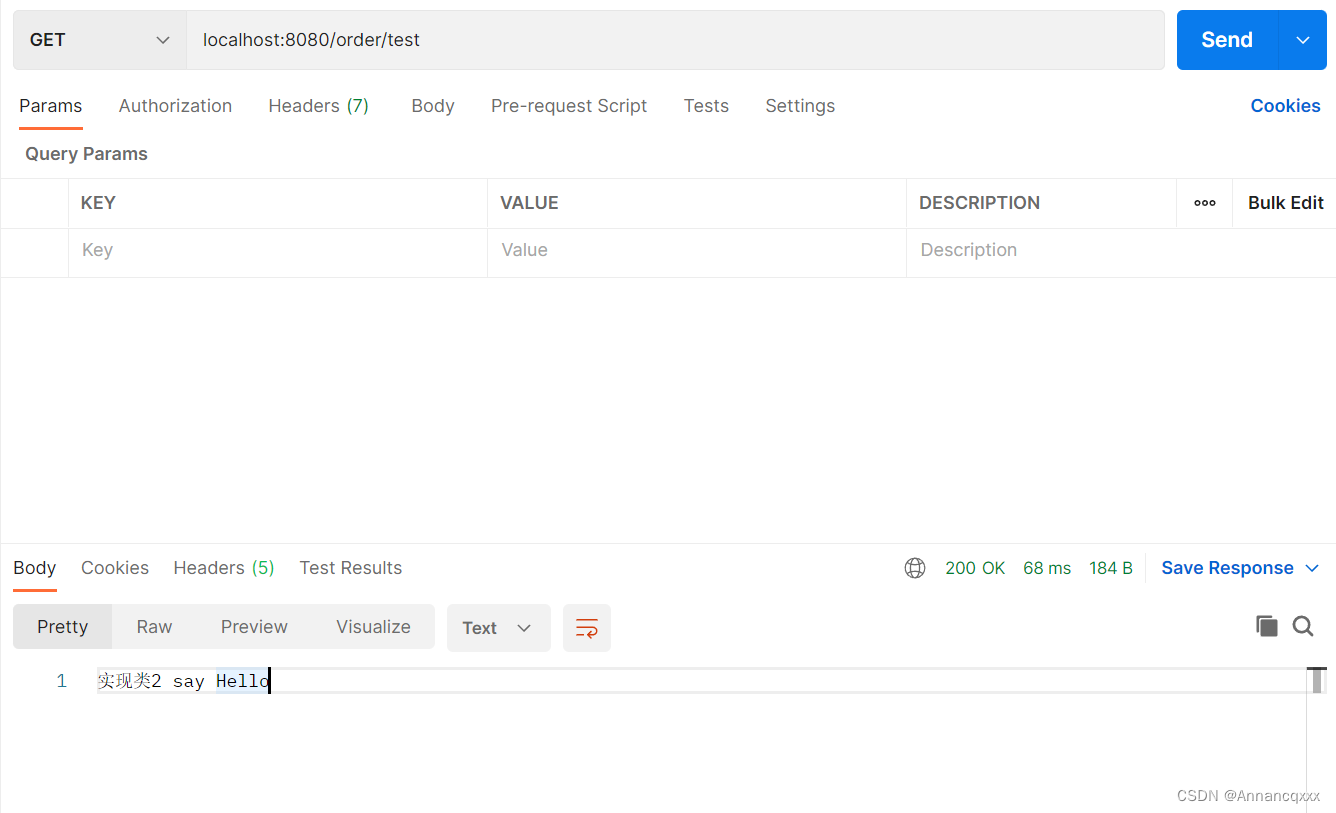
原理:@Resource注解默认的注入方式是by name按名称注入,如果你只是单纯使用@Resource注解,而不指定其属性,那么它默认会匹配字段名。如下
@RestController
@RequestMapping("/order")
public class OrderController {//默认匹配bean名称为orderService的bean示例@ResourceOrderService orderService;/*默认匹配bean名称为service的bean示例@ResourceOrderService service;*/@GetMapping("/test")public String test(){return orderService.sayHello();}}补充:如果by name注入失败,那么它会通过by type继续尝试注入。当然,如果此时存在多个实现类,Spring会在启动阶段报错。
报错:No qualifying bean of type 'com.hammajang.springbootdemo.service.OrderService' available: expected single matching bean but found 2: orderServiceImpl,orderServiceImpl2
这里意指通过by name没有匹配到bean实例,尝试通过by type时匹配到了两个bean实例,Spring不知道注入哪个bean实例。
以上就是本文的全部内容,如果你有所收获,不妨点个赞!