asp.net 网站安装包物业网站建设方案
文章目录
- 一、概述
- 1、什么是JSON
- 2、MySQL的JSON
- 3、varchar、text、json类型字段的区别
- 二、JSON类型的创建
- 1、建表指定
- 2、修改字段
- 三、JSON类型的插入
- 1、字符串直接插入
- 2、JSON_ARRAY()函数插入数组
- 3、JSON_OBJECT()函数插入对象
- 4、JSON_ARRAYAGG()和JSON_OBJECTAGG()将查询结果封装成json
- 四、JSON类型的解析
- 1、JSON_EXTRACT()解析json
- 2、-> 箭头函数解析json
- 3、JSON_QUOTE()引用与JSON_UNQUOTE()取消引用
- 4、->>箭头解析json
- 五、JSON类型的查询
- 1、JSON_CONTAINS()判断是否包含
- 2、JSON_CONTAINS_PATH()判断
- 3、JSON_KEYS()获取keys
- 4、JSON_OVERLAPS()比较两个json
- 5、JSON_SEARCH()返回字符串的位置
- 6、JSON_VALUE()提取指定路径的元素
- 7、MEMBER OF()判断是否是json数组中的元素
- 8、JSON_DEPTH()获取JSON最大深度
- 9、JSON_LENGTH()获取文档长度
- 10、JSON_TYPE()获取JSON类型
- 11、JSON_VALID()校验JSON格式
- 六、JSON类型的修改
- 1、全量修改
- 2、JSON_ARRAY_APPEND()向数组追加元素
- 3、JSON_ARRAY_INSERT()向数组指定位置插入元素
- 4、JSON_INSERT()插入新值
- 5、JSON_MERGE()合并json
- 6、JSON_MERGE_PATCH()合并json
- 7、JSON_MERGE_PRESERVE()合并json
- 8、JSON_REMOVE()删除元素
- 9、JSON_REPLACE()替换元素
- 10、JSON_SET()插入并替换
- 七、其他JSON函数
- 1、JSON_TABLE()列转行
- 2、JSON_SCHEMA_VALID()验证json
- 3、JSON_SCHEMA_VALIDATION_REPORT()查看验证报告
- 4、JSON_PRETTY()格式化输出
- 5、JSON_STORAGE_FREE()计算空间
- 6、JSON_STORAGE_SIZE()计算空间
- 八、JSON字段创建索引
- 参考文档
一、概述
1、什么是JSON
略。自行百度。
2、MySQL的JSON
JSON 数据类型是 MySQL 5.7.8 开始支持的。在此之前,只能通过字符类型(CHAR,VARCHAR 或 TEXT )来保存 JSON 文档。
MySQL 8.0版本中增加了对JSON类型的索引支持。可以使用CREATE INDEX语句创建JSON类型的索引,提高JSON类型数据的查询效率。
存储JSON文档所需的空间与存储LONGBLOB或LONGTEXT所需的空间大致相同。
在MySQL 8.0.13之前,JSON列不能有非空的默认值。
JSON 类型比较适合存储一些列不固定、修改较少、相对静态的数据。MySQL支持JSON格式的数据之后,可以减少对非关系型数据库的依赖。
3、varchar、text、json类型字段的区别
这三种类型的字段,都可以存储json格式,查询起来似乎正常的json函数也能用,这三者存储json类型的数据有什么区别吗?
我们接下来测试一下。
二、JSON类型的创建
1、建表指定
CREATE TABLE `users` (`id` int NOT NULL AUTO_INCREMENT COMMENT 'id',`name` varchar(50) DEFAULT NULL COMMENT '名字',`json_data` json DEFAULT NULL COMMENT 'json数据',`info` varchar(2000) DEFAULT NULL COMMENT '普通数据',`text` text COMMENT 'text数据',PRIMARY KEY (`id`)
) ENGINE=InnoDB;
2、修改字段
-- 添加json字段
ALTER TABLE users ADD COLUMN `test_json` JSON DEFAULT NULL COMMENT '测试';
-- 修改字段类型为json
ALTER TABLE users modify test_json JSON DEFAULT NULL COMMENT '测试';
-- 删除json字段
ALTER TABLE users DROP COLUMN test_json;
三、JSON类型的插入
1、字符串直接插入
varchar、text、json格式都支持,也可以插入更复杂的嵌套json:
-- 插入数组
insert into users(json_data) values('[1, "abc", null, true, "08:45:06.000000"]');
insert into users(info) values('[1, "abc", null, true, "08:45:06.000000"]');
insert into users(text) values('[1, "abc", null, true, "08:45:06.000000"]');
-- 插入对象
insert into users(json_data) values('{"id": 87, "name": "carrot"}');
insert into users(info) values('{"id": 87, "name": "carrot"}');
insert into users(text) values('{"id": 87, "name": "carrot"}');
-- 插入嵌套json
insert into users(json_data) values('[{"sex": "M"},{"sex":"F", "city":"nanjing"}]');
insert into users(info) values('[{"sex": "M"},{"sex":"F", "city":"nanjing"}]');
insert into users(text) values('[{"sex": "M"},{"sex":"F", "city":"nanjing"}]');
但是json格式的字段,插入时会自动校验格式,如果格式不是json的,会报错:
insert into users(json_data) values('{"id", "name": "carrot"}');
> 3140 - Invalid JSON text: "Missing a colon after a name of object member." at position 5 in value for column 'users.json_data'.
2、JSON_ARRAY()函数插入数组
-- 格式:
JSON_ARRAY([val[, val] ...])-- 使用JSON_ARRAY()函数创建数组 : [1, "abc", null, true, "08:09:38.000000"]
insert into users(json_data) values(JSON_ARRAY(1, "abc", null, true,curtime()));
insert into users(info) values(JSON_ARRAY(1, "abc", null, true,curtime()));
insert into users(text) values(JSON_ARRAY(1, "abc", null, true,curtime()));
3、JSON_OBJECT()函数插入对象
对于 JSON 文档,KEY 名不能重复。
如果插入的值中存在重复 KEY,在 MySQL 8.0.3 之前,遵循 first duplicate key wins 原则,会保留第一个 KEY,后面的将被丢弃掉。
从 MySQL 8.0.3 开始,遵循的是 last duplicate key wins 原则,只会保留最后一个 KEY。
-- 格式:
JSON_OBJECT([key, val[, key, val] ...])-- 创建对象,一个key对应一个value : {"id": 87, "name": "carrot"}
insert into users(json_data) values(json_object('id', 87, 'name', 'carrot'));
insert into users(info) values(json_object('id', 87, 'name', 'carrot'));
insert into users(text) values(json_object('id', 87, 'name', 'carrot'));
4、JSON_ARRAYAGG()和JSON_OBJECTAGG()将查询结果封装成json
mysql> SELECT o_id, attribute, value FROM t3;
+------+-----------+-------+
| o_id | attribute | value |
+------+-----------+-------+
| 2 | color | red |
| 2 | fabric | silk |
| 3 | color | green |
| 3 | shape | square|
+------+-----------+-------+
4 rows in set (0.00 sec)mysql> SELECT o_id, JSON_ARRAYAGG(attribute) AS attributes-> FROM t3 GROUP BY o_id;
+------+---------------------+
| o_id | attributes |
+------+---------------------+
| 2 | ["color", "fabric"] |
| 3 | ["color", "shape"] |
+------+---------------------+
2 rows in set (0.00 sec)
mysql> SELECT o_id, attribute, value FROM t3;
+------+-----------+-------+
| o_id | attribute | value |
+------+-----------+-------+
| 2 | color | red |
| 2 | fabric | silk |
| 3 | color | green |
| 3 | shape | square|
+------+-----------+-------+
4 rows in set (0.00 sec)mysql> SELECT o_id, JSON_OBJECTAGG(attribute, value)-> FROM t3 GROUP BY o_id;
+------+---------------------------------------+
| o_id | JSON_OBJECTAGG(attribute, value) |
+------+---------------------------------------+
| 2 | {"color": "red", "fabric": "silk"} |
| 3 | {"color": "green", "shape": "square"} |
+------+---------------------------------------+
2 rows in set (0.00 sec)
四、JSON类型的解析
1、JSON_EXTRACT()解析json
格式:JSON_EXTRACT(json_doc, path[, path] …)
其中,json_doc 是 JSON 文档,path 是路径。该函数会从 JSON 文档提取指定路径(path)的元素。如果指定 path 不存在,会返回 NULL。可指定多个 path,匹配到的多个值会以数组形式返回。
-- 解析数组
-- 取下标为1的数组值(数组下标从0开始),结果:20
SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[1]');
-- 取多个,结果返回是一个数组,结果:[20, 10]
SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[1]', '$[0]');
-- 可以使用*获取全部,结果:[30, 40]
SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[2][*]');-- 还可通过 [M to N] 获取数组的子集
-- 结果:[10, 20]
select json_extract('[10, 20, [30, 40]]', '$[0 to 1]');
-- 这里的 last 代表最后一个元素的下标,结果:[20, [30, 40]]
select json_extract('[10, 20, [30, 40]]', '$[last-1 to last]');
-- 解析对象:对象的路径是通过 KEY 来表示的。
set @j='{"a": 1, "b": [2, 3], "a c": 4}';-- 如果 KEY 在路径表达式中不合法(譬如存在空格),则在引用这个 KEY 时,需用双引号括起来。
-- 结果: 1 4 3
select json_extract(@j, '$.a'), json_extract(@j, '$."a c"'), json_extract(@j, '$.b[1]');
-- 使用*获取所有元素,结果:[1, [2, 3], 4]
select json_extract('{"a": 1, "b": [2, 3], "a c": 4}', '$.*');
-- 这里的 $**.b 匹配 $.a.b 和 $.c.b,结果:[1, 2]
select json_extract('{"a": {"b": 1}, "c": {"b": 2}}', '$**.b');
json_extract解析出来的数据,可以灵活用于where、order by等等所有地方。
2、-> 箭头函数解析json
column->path,包括后面讲到的 column->>path,都是语法糖,在实际使用的时候都会在底层自动转化为 JSON_EXTRACT。
column->path 等同于 JSON_EXTRACT(column, path) ,只能指定一个path。
-- 同JSON_EXTRACT
insert into users(json_data) values('{"empno": 1001, "ename": "jack"}');
-- 结果:"jack"
select json_data, json_data -> '$.ename' from users;
3、JSON_QUOTE()引用与JSON_UNQUOTE()取消引用
JSON_QUOTE(string),生成有效的 JSON 字符串,主要是对一些特殊字符(如双引号)进行转义。
-- 结果:"null" "\"null\"" "[1, 2, 3]"
select json_quote('null'), json_quote('"null"'), json_quote('[1, 2, 3]');
JSON_UNQUOTE(json_val),将 JSON 转义成字符串输出。常用于使用JSON_EXTRACT()和->函数解析完之后,去除引号。
JSON_UNQUOTE()特殊字符转义表:
| 转义序列 | 由序列表示的字符 |
|---|---|
| \" | 双引号 |
| \b | 退格字符 |
| \f | 换页字符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \\ | 反斜杠(\)字符 |
| \uXXXX | Unicode XXXX 转UTF-8 |
insert into users(json_data) values('{"empno": 1001, "ename": "jack"}');
-- 字符串类型转换后会去掉引号,结果:"jack" jack 1 0
select json_data->'$.ename',json_unquote(json_data->'$.ename'),json_valid(json_data->'$.ename'),json_valid(json_unquote(json_data->'$.ename')) from users;
-- 数字类型转换并没有额外效果,结果:1001 1001 1 1
select json_data->'$.empno',json_unquote(json_data->'$.empno'),json_valid(json_data->'$.empno'),json_valid(json_unquote(json_data->'$.empno')) from users;
直观地看,没加 JSON_UNQUOTE 字符串会用双引号引起来,加了 JSON_UNQUOTE 就没有。但本质上,前者是 JSON 中的 STRING 类型,后者是 MySQL 中的字符类型,这一点可通过 JSON_VALID 来判断。
4、->>箭头解析json
同 column->path 类似,只不过其返回的是字符串,相当于将字符串的双引号去掉了,是一个语法糖,本质上是执行了JSON_UNQUOTE( JSON_EXTRACT(column, path) )。
以下三者是等价的:
JSON_UNQUOTE( JSON_EXTRACT(column, path) )
JSON_UNQUOTE(column -> path)
column->>path
insert into users(json_data) values('{"empno": 1001, "ename": "jack"}');
-- 结果:"jack" jack jack jack
select json_data->'$.ename',json_unquote(json_data->'$.ename'),json_data->>'$.ename', JSON_UNQUOTE( JSON_EXTRACT(json_data, '$.ename') ) from users;
五、JSON类型的查询
1、JSON_CONTAINS()判断是否包含
格式:JSON_CONTAINS(target, candidate[, path])
判断 target 文档是否包含 candidate 文档,包含的话返回1,不包含的话返回0
如果带了path,就判断path中的数据是否等于candidate,等于的话返回1,不等于的话返回0
函数前加not可取反
SET @j = '{"a": 1, "b": 2, "c": {"d": 4}}';
SET @j2 = '{"a":1}';
-- 判断@j中是否包含@j2,结果:1
SELECT JSON_CONTAINS(@j, @j2);SET @j2 = '1';
-- 判断@j字段中的a是否等于1,结果:1
SELECT JSON_CONTAINS(@j, @j2, '$.a');
-- 结果:0
SELECT JSON_CONTAINS(@j, @j2, '$.b');SET @j2 = '{"d": 4}';
-- 结果:0
SELECT JSON_CONTAINS(@j, @j2, '$.a');
-- 结果:1
SELECT JSON_CONTAINS(@j, @j2, '$.c');SET @j = '[1, "a", 1.02]';
SET @j2 = '"a"';
-- 判断@j数组中是否包含@j2,结果:1
SELECT JSON_CONTAINS(@j, @j2);
2、JSON_CONTAINS_PATH()判断
格式:JSON_CONTAINS_PATH(json_doc, one_or_all, path[, path] …)
判断指定的 path 是否存在,存在,则返回 1,否则是 0。
函数中的 one_or_all 可指定 one 或 all,one 是任意一个路径存在就返回 1,all 是所有路径都存在才返回 1。
函数前加not可取反
SET @j = '{"a": 1, "b": 2, "c": {"d": 4}}';
-- a或者e 存在一个就返回1,结果:1
SELECT JSON_CONTAINS_PATH(@j, 'one', '$.a', '$.e');
-- a和e都存在返回1,结果:0
SELECT JSON_CONTAINS_PATH(@j, 'all', '$.a', '$.e');
-- c中的d存在返回1,结果:1
SELECT JSON_CONTAINS_PATH(@j, 'one', '$.c.d');SET @j = '[1, 4, "a", "c"]';
-- @j是一个数组,$[1]判断第二个数据是否存在,结果为1
select JSON_CONTAINS_PATH(@j, 'one', '$[1]');
-- $[11]判断第11个数据不存在,结果为0
select JSON_CONTAINS_PATH(@j, 'one', '$[11]');
3、JSON_KEYS()获取keys
返回 JSON 文档最外层的 key,如果指定了 path,则返回该 path 对应元素最外层的 key。
-- 结果:["a", "b"]
SELECT JSON_KEYS('{"a": 1, "b": {"c": 30}}');
-- 结果:["c"]
SELECT JSON_KEYS('{"a": 1, "b": {"c": 30}}', '$.b');
4、JSON_OVERLAPS()比较两个json
MySQL 8.0.17 引入的,用来比较两个 JSON 文档是否有相同的键值对或数组元素,如果有,则返回 1,否则是 0。 如果两个参数都是标量,则判断这两个标量是否相等。
函数前加not可取反
-- 结果: 1 0
select json_overlaps('[1,3,5,7]', '[2,5,7]'),json_overlaps('[1,3,5,7]', '[2,6,8]');-- 部分匹配被视为不匹配,结果:0
SELECT JSON_OVERLAPS('[[1,2],[3,4],5]', '[1,[2,3],[4,5]]');-- 比较对象时,如果它们至少有一个共同的键值对,则结果为真。
-- 结果:1
SELECT JSON_OVERLAPS('{"a":1,"b":10,"d":10}', '{"c":1,"e":10,"f":1,"d":10}');
-- 结果:0
SELECT JSON_OVERLAPS('{"a":1,"b":10,"d":10}', '{"a":5,"e":10,"f":1,"d":20}');-- 如果两个标量用作函数的参数,JSON_OVERLAPS()会执行一个简单的相等测试:
-- 结果:1
SELECT JSON_OVERLAPS('5', '5');
-- 结果:0
SELECT JSON_OVERLAPS('5', '6');-- 当比较标量和数组时,JSON_OVERLAPS()试图将标量视为数组元素。在此示例中,第二个参数6被解释为[6],如下所示:结果:1
SELECT JSON_OVERLAPS('[4,5,6,7]', '6');-- 该函数不执行类型转换:
-- 结果:0
SELECT JSON_OVERLAPS('[4,5,"6",7]', '6');
-- 结果:0
SELECT JSON_OVERLAPS('[4,5,6,7]', '"6"');
5、JSON_SEARCH()返回字符串的位置
格式:JSON_SEARCH(json_doc, one_or_all, search_str[, escape_char[, path] …])
返回某个字符串(search_str)在 JSON 文档中的位置,其中,
one_or_all:匹配的次数,one 是只匹配一次,all 是匹配所有。如果匹配到多个,结果会以数组的形式返回。
search_str:子串,支持模糊匹配:% 和 _ 。
escape_char:转义符,如果该参数不填或为 NULL,则取默认转义符\。
path:查找路径。
SET @j = '["abc", [{"k": "10"}, "def"], {"x":"abc"}, {"y":"bcd"}]';
-- 结果:"$[0]"
SELECT JSON_SEARCH(@j, 'one', 'abc');
-- 结果:["$[0]", "$[2].x"]
SELECT JSON_SEARCH(@j, 'all', 'abc');
-- 结果:null
SELECT JSON_SEARCH(@j, 'all', 'ghi');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[*]');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$**.k');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[*][0].k');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[1]');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[1][0]');
-- 结果:"$[2].x"
SELECT JSON_SEARCH(@j, 'all', 'abc', NULL, '$[2]');
-- 结果:["$[0]", "$[2].x"]
SELECT JSON_SEARCH(@j, 'all', '%a%');
-- 结果:["$[0]", "$[2].x", "$[3].y"]
SELECT JSON_SEARCH(@j, 'all', '%b%');
-- 结果:"$[0]"
SELECT JSON_SEARCH(@j, 'all', '%b%', NULL, '$[0]');
-- 结果:"$[2].x"
SELECT JSON_SEARCH(@j, 'all', '%b%', NULL, '$[2]');
-- 结果:null
SELECT JSON_SEARCH(@j, 'all', '%b%', NULL, '$[1]');
-- 结果:null
SELECT JSON_SEARCH(@j, 'all', '%b%', '', '$[1]');
-- 结果:"$[3].y"
SELECT JSON_SEARCH(@j, 'all', '%b%', '', '$[3]');
6、JSON_VALUE()提取指定路径的元素
格式:JSON_VALUE(json_doc, path)
8.0.21 引入的,从 JSON 文档提取指定路径(path)的元素。
完整的语法如下所示:
JSON_VALUE(json_doc, path [RETURNING type] [on_empty] [on_error])on_empty:{NULL | ERROR | DEFAULT value} ON EMPTYon_error:{NULL | ERROR | DEFAULT value} ON ERROR
其中:
RETURNING type:返回值的类型,不指定,则默认是 VARCHAR(512)。不指定字符集,则默认是 utf8mb4,且区分大小写。
on_empty:如果指定路径没有值,会触发 on_empty 子句, 默认是返回 NULL,也可指定 ERROR 抛出错误,或者通过 DEFAULT value 返回默认值。
on_error:三种情况下会触发 on_error 子句:从数组或对象中提取元素时,会解析到多个值;类型转换错误,譬如将 “abc” 转换为 unsigned 类型;值被 truncate 了。默认是返回 NULL。
-- 查找fname的值,结果为:Joe
SELECT JSON_VALUE('{"fname": "Joe", "lname": "Palmer"}', '$.fname');
-- 结果:49.95
SELECT JSON_VALUE('{"item": "shoes", "price": "49.95"}', '$.price' RETURNING DECIMAL(4,2)) AS price;
-- 结果:50.0
SELECT JSON_VALUE('{"item": "shoes", "price": "49.95"}', '$.price' RETURNING DECIMAL(4,1)) AS price;
-- 使用RETURNING定义返回数据类型,等效于以下sql:
SELECT CAST(JSON_UNQUOTE( JSON_EXTRACT(json_doc, path) )AS type
);mysql> select json_value('{"item": "shoes", "price": "49.95"}', '$.price1' error on empty);
ERROR 3966 (22035): No value was found by 'json_value' on the specified path.mysql> select json_value('[1, 2, 3]', '$[1 to 2]' error on error);
ERROR 3967 (22034): More than one value was found by 'json_value' on the specified path.mysql> select json_value('{"item": "shoes", "price": "49.95"}', '$.item' returning unsigned error on error) as price;
ERROR 1690 (22003): UNSIGNED value is out of range in 'json_value'
7、MEMBER OF()判断是否是json数组中的元素
格式:value MEMBER OF(json_array)
在 MySQL 8.0.17引入了MEMBER OF()函数。判断 value 是否是 JSON 数组的一个元素,如果是,则返回 1,否则是 0。
函数前加not可取反
-- 结果:1
SELECT 17 MEMBER OF('[23, "abc", 17, "ab", 10]');
-- 结果:1
SELECT 'ab' MEMBER OF('[23, "abc", 17, "ab", 10]');
-- 部分匹配不代表匹配
-- 结果:0
SELECT 7 MEMBER OF('[23, "abc", 17, "ab", 10]');
-- 结果:0
SELECT 'a' MEMBER OF('[23, "abc", 17, "ab", 10]');
-- 不执行字符串类型之间的相互转换:结果:0·0
SELECT 17 MEMBER OF('[23, "abc", "17", "ab", 10]'), "17" MEMBER OF('[23, "abc", 17, "ab", 10]')
-- 要将该操作符与本身是数组的值一起使用,必须将其显式转换为JSON数组。结果:1
SELECT CAST('[4,5]' AS JSON) MEMBER OF('[[3,4],[4,5]]');
-- 还可以使用JSON_ARRAY()函数执行必要的强制转换,如下所示: 结果:1
SELECT JSON_ARRAY(4,5) MEMBER OF('[[3,4],[4,5]]');--转换,结果:1 1
SET @a = CAST('{"a":1}' AS JSON);
SET @b = JSON_OBJECT("b", 2);
SET @c = JSON_ARRAY(17, @b, "abc", @a, 23);
SELECT @a MEMBER OF(@c), @b MEMBER OF(@c);
8、JSON_DEPTH()获取JSON最大深度
语法:JSON_DEPTH(json_doc)
返回JSON文档的最大深度。如果参数为NULL,则返回NULL。如果参数不是有效的JSON文档,则会出现错误。
对于空数组,空对象,标量值,其深度为 1。
-- 结果:1 1 1
SELECT JSON_DEPTH('{}'), JSON_DEPTH('[]'), JSON_DEPTH('true');
-- 结果:2 2
SELECT JSON_DEPTH('[10, 20]'), JSON_DEPTH('[[], {}]');
-- 结果:3
SELECT JSON_DEPTH('[10, {"a": 20}]');
9、JSON_LENGTH()获取文档长度
语法:JSON_LENGTH(json_doc[, path])
返回 JSON 文档的长度,其计算规则如下:
1、如果是标量值,其长度为 1。
2、如果是数组,其长度为数组元素的个数。
3、如果是对象,其长度为对象元素的个数。
4、不包括嵌套数据和嵌套对象的长度。
-- 结果:3
SELECT JSON_LENGTH('[1, 2, {"a": 3}]');
-- 结果:2
SELECT JSON_LENGTH('{"a": 1, "b": {"c": 30}}');
-- 结果:1
SELECT JSON_LENGTH('{"a": 1, "b": {"c": 30}}', '$.b');
10、JSON_TYPE()获取JSON类型
语法:JSON_TYPE(json_val)
返回 JSON 值的类型。
如果参数不是有效的JSON值,则会出现错误。
SET @j = '{"a": [10, true]}';
-- 结果:OBJECT
SELECT JSON_TYPE(@j);
-- 结果:ARRAY
SELECT JSON_TYPE(JSON_EXTRACT(@j, '$.a'));
-- 结果:INTEGER
SELECT JSON_TYPE(JSON_EXTRACT(@j, '$.a[0]'));
-- 结果:BOOLEAN
SELECT JSON_TYPE(JSON_EXTRACT(@j, '$.a[1]'));
-- 结果:NULL
SELECT JSON_TYPE(NULL);
-- 结果:STRING
select json_type('"abc"');
-- 结果:DATETIME
select json_type(cast(now() as json));
JSON类型:OBJECT(对象)、ARRAY(数组)、BOOLEAN(布尔类型)、NULL
数字类型:INTEGER(TINYINT、SMALLINT、MEDIUMINT以及INT和BIGINT标量)、DOUBLE(DOUBLE、FLOAT)、DECIMAL(MySQL、DECIMAL)
时间类型:DATETIME(DATETIME、TIMESTAMP)、DATE、TIME
字符串类型:STRING(CHAR, VARCHAR, TEXT, ENUM, SET)
二进制类型:BLOB( BINARY, VARBINARY, BLOB, BIT)
其他类型:OPAQUE
11、JSON_VALID()校验JSON格式
语法:JSON_VALID(val)
判断给定值是否是有效的 JSON 文档。
函数前加not可取反
-- 结果:1
SELECT JSON_VALID('{"a": 1}');
-- 结果:0 1
SELECT JSON_VALID('hello'), JSON_VALID('"hello"');
六、JSON类型的修改
1、全量修改
直接使用update语句,将json数据字段全部替换。
update users set json_data = '{"a":1}';
2、JSON_ARRAY_APPEND()向数组追加元素
格式:JSON_ARRAY_APPEND(json_doc, path, val[, path, val] …)
向数组指定位置追加元素。如果指定 path 不存在,则不添加。
在MySQL 5.7中,这个函数被命名为JSON_APPEND()。MySQL 8.0不再支持该名称。
SET @j = '["a", ["b", "c"], "d"]';
-- 在数组第二个元素的数组中追加1,结果:["a", ["b", "c", 1], "d"]
SELECT JSON_ARRAY_APPEND(@j, '$[1]', 1);
-- 结果:[["a", 2], ["b", "c"], "d"]
SELECT JSON_ARRAY_APPEND(@j, '$[0]', 2);
-- 结果:["a", [["b", 3], "c"], "d"]
SELECT JSON_ARRAY_APPEND(@j, '$[1][0]', 3);
-- 多个参数,结果:[["a", 1], [["b", 2], "c"], "d"]
select json_array_append(@j, '$[0]', 1, '$[1][0]', 2, '$[3]', 3);SET @j = '{"a": 1, "b": [2, 3], "c": 4}';
-- 往b中追加,结果:{"a": 1, "b": [2, 3, "x"], "c": 4}
SELECT JSON_ARRAY_APPEND(@j, '$.b', 'x');
-- 结果:{"a": 1, "b": [2, 3], "c": [4, "y"]}
SELECT JSON_ARRAY_APPEND(@j, '$.c', 'y');SET @j = '{"a": 1}';
-- 结果:[{"a": 1}, "z"]
SELECT JSON_ARRAY_APPEND(@j, '$', 'z');
3、JSON_ARRAY_INSERT()向数组指定位置插入元素
格式:JSON_ARRAY_INSERT(json_doc, path, val[, path, val] …)
向数组指定位置插入元素。
SET @j = '["a", {"b": [1, 2]}, [3, 4]]';
-- 在下标1处添加元素x,结果:["a", "x", {"b": [1, 2]}, [3, 4]]
SELECT JSON_ARRAY_INSERT(@j, '$[1]', 'x');
-- 没有100个元素,在最后插入,结果: ["a", {"b": [1, 2]}, [3, 4], "x"]
SELECT JSON_ARRAY_INSERT(@j, '$[100]', 'x');
-- 结果:["a", {"b": ["x", 1, 2]}, [3, 4]]
SELECT JSON_ARRAY_INSERT(@j, '$[1].b[0]', 'x');
-- 结果:["a", {"b": [1, 2]}, [3, "y", 4]]
SELECT JSON_ARRAY_INSERT(@j, '$[2][1]', 'y');-- 早期的修改会影响数组中后续元素的位置,因此同一个JSON_ARRAY_INSERT()调用中的后续路径应该考虑这一点。在最后一个示例中,第二个路径没有插入任何内容,因为在第一次插入之后,该路径不再匹配任何内容。
-- 结果:["x", "a", {"b": [1, 2]}, [3, 4]]
SELECT JSON_ARRAY_INSERT(@j, '$[0]', 'x', '$[2][1]', 'y');
4、JSON_INSERT()插入新值
格式:JSON_INSERT(json_doc, path, val[, path, val] …)
插入不存在的key的值,已经存在的不修改。
仅当指定位置或指定 KEY 的值不存在时,才执行插入操作。另外,如果指定的 path 是数组下标,且 json_doc 不是数组,该函数首先会将 json_doc 转化为数组,然后再插入新值。
SET @j = '{ "a": 1, "b": [2, 3]}';
-- a已经存在则忽略,c不存在则添加,结果:{"a": 1, "b": [2, 3], "c": "[true, false]"}
SELECT JSON_INSERT(@j, '$.a', 10, '$.c', '[true, false]');
-- 上面插入的c是一个带引号的字符串,想要插入一个数组,必须进行转换,结果:{"a": 1, "b": [2, 3], "c": [true, false]}
SELECT JSON_INSERT(@j, '$.a', 10, '$.c', CAST('[true, false]' AS JSON));-- 下标0位置已经有值了,不会插入,结果:1
select json_insert('1','$[0]',"10");
-- 结果:[1, "10"]
select json_insert('1','$[1]',"10");
-- 结果:["1", "2", "10"]
select json_insert('["1","2"]','$[2]',"10");
5、JSON_MERGE()合并json
格式:JSON_MERGE(json_doc, json_doc[, json_doc] …)
合并两个或多个JSON文档。JSON_MERGE_PRESERVE()的同义词;在MySQL 8.0.3中已弃用,在未来版本中可能会被删除。
推荐使用JSON_MERGE_PRESERVE()
-- 结果:[1, 2, true, false]
SELECT JSON_MERGE('[1, 2]', '[true, false]');
6、JSON_MERGE_PATCH()合并json
MySQL 8.0.3 引入的,用来合并多个 JSON 文档。其合并规则如下:
1、如果两个文档不全是 JSON 对象,则合并后的结果是第二个文档。
2、如果两个文档都是 JSON 对象,且不存在着同名 KEY,则合并后的文档包括两个文档的所有元素,如果存在着同名 KEY,则第二个文档的值会覆盖第一个。
-- 不是对象,结果:[true, false]
SELECT JSON_MERGE_PATCH('[1, 2]', '[true, false]');
-- 都是对象,结果:{"id": 47, "name": "x"}
SELECT JSON_MERGE_PATCH('{"name": "x"}', '{"id": 47}');
-- 都不是对象,取第二个,结果:true
SELECT JSON_MERGE_PATCH('1', 'true');
-- 第一个不是对象,取第二个 ,结果:{"id": 47}
SELECT JSON_MERGE_PATCH('[1, 2]', '{"id": 47}');
-- 第二个覆盖第一个,结果:{"a": 3, "b": 2, "c": 4}
SELECT JSON_MERGE_PATCH('{ "a": 1, "b":2 }','{ "a": 3, "c":4 }');
-- 结果:{"a": 5, "b": 2, "c": 4, "d": 6}
SELECT JSON_MERGE_PATCH('{ "a": 1, "b":2 }','{ "a": 3, "c":4 }', '{ "a": 5, "d":6 }');
-- 第二个有null,会删除该key,结果:{"a": 1}
SELECT JSON_MERGE_PATCH('{"a":1, "b":2}', '{"b":null}');
-- 嵌套json也可以合并,结果:{"a": {"x": 1, "y": 2}}
SELECT JSON_MERGE_PATCH('{"a":{"x":1}}', '{"a":{"y":2}}');
注意区别于JSON_MERGE_PRESERVE
7、JSON_MERGE_PRESERVE()合并json
MySQL 8.0.3 引入的,用来代替 JSON_MERGE。也是用来合并文档,但合并规则与 JSON_MERGE_PATCH 有所不同。
1、两个文档中,只要有一个文档是数组,则另外一个文档会合并到该数组中。
2、两个文档都是 JSON 对象,若存在着同名 KEY ,第二个文档并不会覆盖第一个,而是会将值 append 到第一个文档中。
-- 数组合并,结果:[1, 2, true, false]
SELECT JSON_MERGE_PRESERVE('[1, 2]', '[true, false]');
-- 对象合并,结果:{"id": 47, "name": "x"}
SELECT JSON_MERGE_PRESERVE('{"name": "x"}', '{"id": 47}');
-- 两个常量,合并为一个数组,结果:[1, true]
SELECT JSON_MERGE_PRESERVE('1', 'true');
-- 对象合并到数组中,结果:[1, 2, {"id": 47}]
SELECT JSON_MERGE_PRESERVE('[1, 2]', '{"id": 47}');
-- 相同的key合并到一个数组,结果:{"a": [1, 3], "b": 2, "c": 4}
SELECT JSON_MERGE_PRESERVE('{ "a": 1, "b": 2 }', '{ "a": 3, "c": 4 }');
-- 结果:{"a": [1, 3, 5], "b": 2, "c": 4, "d": 6}
SELECT JSON_MERGE_PRESERVE('{ "a": 1, "b": 2 }','{ "a": 3, "c": 4 }', '{ "a": 5, "d": 6 }');
注意区别于JSON_MERGE_PATCH()
8、JSON_REMOVE()删除元素
格式:JSON_REMOVE(json_doc, path[, path] …)
删除 JSON 文档指定位置的元素。
SET @j = '["a", ["b", "c"], "d"]';
-- 删除下标为1的元素,结果:["a", "d"]
SELECT JSON_REMOVE(@j, '$[1]');set @j = '{ "a": 1, "b": [2, 3]}';
-- 删除a元素,结果:{"b": [2, 3]}
select json_remove(@j, '$.a');set @j = '["a", ["b", "c"], "d", "e"]';
-- 删除多个元素,删除1下标之后,下标移动结果之后再删除下标2位置,结果:["a", "d"]
select json_remove(@j, '$[1]','$[2]');
-- 结果:["a", "e"]
select json_remove(@j, '$[1]','$[1]');
9、JSON_REPLACE()替换元素
语法:JSON_REPLACE(json_doc, path, val[, path, val] …)
替换已经存在的值。不存在的值不做影响。
SET @j = '{ "a": 1, "b": [2, 3]}';
-- 对象替换,结果:{"a": 10, "b": [2, 3]}
SELECT JSON_REPLACE(@j, '$.a', 10, '$.c', '[true, false]');-- 数组替换,结果:[1, "a", 4, "b"]
select json_replace('[1, "a", 3, "b"]', '$[2]', 4, '$[8]', 8);
10、JSON_SET()插入并替换
格式:JSON_SET(json_doc, path, val[, path, val] …)
插入新值,并替换已经存在的值。
换言之,如果指定位置或指定 KEY 的值不存在,会执行插入操作,如果存在,则执行更新操作。
注意JSON_SET、JSON_INSERT、JSON_REPLACE的区别。
SET @j = '{ "a": 1, "b": [2, 3]}';
-- 结果:{"a": 10, "b": [2, 3], "c": "[true, false]"}
SELECT JSON_SET(@j, '$.a', 10, '$.c', '[true, false]');
-- 结果:{"a": 1, "b": [2, 3], "c": "[true, false]"}
SELECT JSON_INSERT(@j, '$.a', 10, '$.c', '[true, false]');
-- 结果:{"a": 10, "b": [2, 3]}
SELECT JSON_REPLACE(@j, '$.a', 10, '$.c', '[true, false]');
七、其他JSON函数
1、JSON_TABLE()列转行
语法:JSON_TABLE(expr, path COLUMNS (column_list) [AS] alias)
MySQL 8.0支持这样一个函数,JSON_TABLE(),从 JSON 文档中提取数据并以表格的形式返回。
完整语法如下:
JSON_TABLE(expr,path COLUMNS (column_list)
) [AS] aliascolumn_list:column[, column][, ...]column:name FOR ORDINALITY| name type PATH string path [on_empty] [on_error]| name type EXISTS PATH string path| NESTED [PATH] path COLUMNS (column_list)on_empty:{NULL | DEFAULT json_string | ERROR} ON EMPTYon_error:{NULL | DEFAULT json_string | ERROR} ON ERROR
mysql> SELECT *-> FROM-> JSON_TABLE(-> '[ {"c1": null} ]',-> '$[*]' COLUMNS( c1 INT PATH '$.c1' ERROR ON ERROR )-> ) as jt;
+------+
| c1 |
+------+
| NULL |
+------+
1 row in set (0.00 sec)
select *fromjson_table('[{"x":2, "y":"8", "z":9, "b":[1,2,3]}, {"x":"3", "y":"7"}, {"x":"4", "y":6, "z":10}]',"$[*]" columns(id for ordinality,xval varchar(100) path "$.x",yval varchar(100) path "$.y",z_exist int exists path "$.z",nested path '$.b[*]' columns (b INT PATH '$'))) as t;
+------+------+------+---------+------+
| id | xval | yval | z_exist | b |
+------+------+------+---------+------+
| 1 | 2 | 8 | 1 | 1 |
| 1 | 2 | 8 | 1 | 2 |
| 1 | 2 | 8 | 1 | 3 |
| 2 | 3 | 7 | 0 | NULL |
| 3 | 4 | 6 | 1 | NULL |
+------+------+------+---------+------+
5 rows in set (0.00 sec)
mysql> SELECT *-> FROM-> JSON_TABLE(-> '[{"a":"3"},{"a":2},{"b":1},{"a":0},{"a":[1,2]}]',-> "$[*]"-> COLUMNS(-> rowid FOR ORDINALITY,-> ac VARCHAR(100) PATH "$.a" DEFAULT '111' ON EMPTY DEFAULT '999' ON ERROR,-> aj JSON PATH "$.a" DEFAULT '{"x": 333}' ON EMPTY,-> bx INT EXISTS PATH "$.b"-> )-> ) AS tt;+-------+------+------------+------+
| rowid | ac | aj | bx |
+-------+------+------------+------+
| 1 | 3 | "3" | 0 |
| 2 | 2 | 2 | 0 |
| 3 | 111 | {"x": 333} | 1 |
| 4 | 0 | 0 | 0 |
| 5 | 999 | [1, 2] | 0 |
+-------+------+------------+------+
5 rows in set (0.00 sec)
mysql> SELECT *-> FROM-> JSON_TABLE(-> '[{"x":2,"y":"8"},{"x":"3","y":"7"},{"x":"4","y":6}]',-> "$[*]" COLUMNS(-> xval VARCHAR(100) PATH "$.x",-> yval VARCHAR(100) PATH "$.y"-> )-> ) AS jt1;+------+------+
| xval | yval |
+------+------+
| 2 | 8 |
| 3 | 7 |
| 4 | 6 |
+------+------+
-- 指定path
mysql> SELECT *-> FROM-> JSON_TABLE(-> '[{"x":2,"y":"8"},{"x":"3","y":"7"},{"x":"4","y":6}]',-> "$[1]" COLUMNS(-> xval VARCHAR(100) PATH "$.x",-> yval VARCHAR(100) PATH "$.y"-> )-> ) AS jt1;+------+------+
| xval | yval |
+------+------+
| 3 | 7 |
+------+------+
mysql> SELECT *-> FROM-> JSON_TABLE(-> '[ {"a": 1, "b": [11,111]}, {"a": 2, "b": [22,222]}, {"a":3}]',-> '$[*]' COLUMNS(-> a INT PATH '$.a',-> NESTED PATH '$.b[*]' COLUMNS (b INT PATH '$')-> )-> ) AS jt-> WHERE b IS NOT NULL;+------+------+
| a | b |
+------+------+
| 1 | 11 |
| 1 | 111 |
| 2 | 22 |
| 2 | 222 |
+------+------+
mysql> SELECT *-> FROM-> JSON_TABLE(-> '[{"a": 1, "b": [11,111]}, {"a": 2, "b": [22,222]}]',-> '$[*]' COLUMNS(-> a INT PATH '$.a',-> NESTED PATH '$.b[*]' COLUMNS (b1 INT PATH '$'),-> NESTED PATH '$.b[*]' COLUMNS (b2 INT PATH '$')-> )-> ) AS jt;+------+------+------+
| a | b1 | b2 |
+------+------+------+
| 1 | 11 | NULL |
| 1 | 111 | NULL |
| 1 | NULL | 11 |
| 1 | NULL | 111 |
| 2 | 22 | NULL |
| 2 | 222 | NULL |
| 2 | NULL | 22 |
| 2 | NULL | 222 |
+------+------+------+
mysql> SELECT *-> FROM-> JSON_TABLE(-> '[{"a": "a_val",'> "b": [{"c": "c_val", "l": [1,2]}]},'> {"a": "a_val",'> "b": [{"c": "c_val","l": [11]}, {"c": "c_val", "l": [22]}]}]',-> '$[*]' COLUMNS(-> top_ord FOR ORDINALITY,-> apath VARCHAR(10) PATH '$.a',-> NESTED PATH '$.b[*]' COLUMNS (-> bpath VARCHAR(10) PATH '$.c',-> ord FOR ORDINALITY,-> NESTED PATH '$.l[*]' COLUMNS (lpath varchar(10) PATH '$')-> )-> )-> ) as jt;+---------+---------+---------+------+-------+
| top_ord | apath | bpath | ord | lpath |
+---------+---------+---------+------+-------+
| 1 | a_val | c_val | 1 | 1 |
| 1 | a_val | c_val | 1 | 2 |
| 2 | a_val | c_val | 1 | 11 |
| 2 | a_val | c_val | 2 | 22 |
+---------+---------+---------+------+-------+
与表关联查询:
CREATE TABLE t1 (c1 INT, c2 CHAR(1), c3 JSON);INSERT INTO t1 () VALUESROW(1, 'z', JSON_OBJECT('a', 23, 'b', 27, 'c', 1)),ROW(1, 'y', JSON_OBJECT('a', 44, 'b', 22, 'c', 11)),ROW(2, 'x', JSON_OBJECT('b', 1, 'c', 15)),ROW(3, 'w', JSON_OBJECT('a', 5, 'b', 6, 'c', 7)),ROW(5, 'v', JSON_OBJECT('a', 123, 'c', 1111))
;SELECT c1, c2, JSON_EXTRACT(c3, '$.*')
FROM t1 AS m
JOIN
JSON_TABLE(m.c3, '$.*' COLUMNS(at VARCHAR(10) PATH '$.a' DEFAULT '1' ON EMPTY, bt VARCHAR(10) PATH '$.b' DEFAULT '2' ON EMPTY, ct VARCHAR(10) PATH '$.c' DEFAULT '3' ON EMPTY)
) AS tt
ON m.c1 > tt.at;
结果:
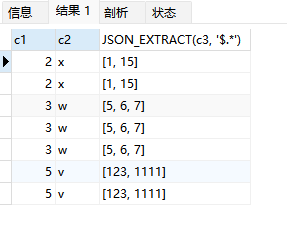
与表关联查询:
CREATE TABLE employees (id INT,details JSON
);INSERT INTO employees VALUES (1, '{"name": "John Doe", "position": "Manager"}');
INSERT INTO employees VALUES (2, '{"name": "Jane Smith", "position": "Developer"}');SELECT name, position
FROM employees,
JSON_TABLE(details, '$' COLUMNS(name VARCHAR(255) PATH '$.name',position VARCHAR(255) PATH '$.position'
)) AS emp;
2、JSON_SCHEMA_VALID()验证json
语法:JSON_SCHEMA_VALID(schema,document)
判断 document ( JSON 文档 )是否满足 schema ( JSON 对象)定义的规范要求。完整的规范要求可参考 Draft 4 of the JSON Schema specification (https://json-schema.org/specification-links.html#draft-4)。如果不满足,可通过 JSON_SCHEMA_VALIDATION_REPORT() 获取具体的原因。
它的要求如下:
1、document 必须是 JSON 对象。
2、JSON 对象必需的两个属性是 latitude 和 longitude。
3、latitude 和 longitude 必须是数值类型,且两者的大小分别在 -90 ~ 90,-180 ~ 180 之间。
mysql> SET @schema = '{'> "id": "http://json-schema.org/geo",'> "$schema": "http://json-schema.org/draft-04/schema#",'> "description": "A geographical coordinate",'> "type": "object",'> "properties": {'> "latitude": {'> "type": "number",'> "minimum": -90,'> "maximum": 90'> },'> "longitude": {'> "type": "number",'> "minimum": -180,'> "maximum": 180'> }'> },'> "required": ["latitude", "longitude"]'>}';
Query OK, 0 rows affected (0.01 sec)mysql> SET @document = '{'> "latitude": 63.444697,'> "longitude": 10.445118'>}';
Query OK, 0 rows affected (0.00 sec)mysql> SELECT JSON_SCHEMA_VALID(@schema, @document);
+---------------------------------------+
| JSON_SCHEMA_VALID(@schema, @document) |
+---------------------------------------+
| 1 |
+---------------------------------------+
1 row in set (0.00 sec)
mysql> SET @document = '{}';
mysql> SET @schema = '{'> "id": "http://json-schema.org/geo",'> "$schema": "http://json-schema.org/draft-04/schema#",'> "description": "A geographical coordinate",'> "type": "object",'> "properties": {'> "latitude": {'> "type": "number",'> "minimum": -90,'> "maximum": 90'> },'> "longitude": {'> "type": "number",'> "minimum": -180,'> "maximum": 180'> }'> }'>}';
Query OK, 0 rows affected (0.00 sec)mysql> SELECT JSON_SCHEMA_VALID(@schema, @document);
+---------------------------------------+
| JSON_SCHEMA_VALID(@schema, @document) |
+---------------------------------------+
| 1 |
+---------------------------------------+
1 row in set (0.00 sec)-- 建表指定check
mysql> CREATE TABLE geo (-> coordinate JSON,-> CHECK(-> JSON_SCHEMA_VALID(-> '{'> "type":"object",'> "properties":{'> "latitude":{"type":"number", "minimum":-90, "maximum":90},'> "longitude":{"type":"number", "minimum":-180, "maximum":180}'> },'> "required": ["latitude", "longitude"]'> }',-> coordinate-> )-> )-> );
Query OK, 0 rows affected (0.45 sec)mysql> SET @point1 = '{"latitude":59, "longitude":18}';
Query OK, 0 rows affected (0.00 sec)mysql> SET @point2 = '{"latitude":91, "longitude":0}';
Query OK, 0 rows affected (0.00 sec)mysql> SET @point3 = '{"longitude":120}';
Query OK, 0 rows affected (0.00 sec)mysql> INSERT INTO geo VALUES(@point1);
Query OK, 1 row affected (0.05 sec)mysql> INSERT INTO geo VALUES(@point2);
ERROR 3819 (HY000): Check constraint 'geo_chk_1' is violated.-- 查看原因
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************Level: ErrorCode: 3934
Message: The JSON document location '#/latitude' failed requirement 'maximum' at
JSON Schema location '#/properties/latitude'.
*************************** 2. row ***************************Level: ErrorCode: 3819
Message: Check constraint 'geo_chk_1' is violated.
2 rows in set (0.00 sec)mysql> INSERT INTO geo VALUES(@point3);
ERROR 3819 (HY000): Check constraint 'geo_chk_1' is violated.
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************Level: ErrorCode: 3934
Message: The JSON document location '#' failed requirement 'required' at JSON
Schema location '#'.
*************************** 2. row ***************************Level: ErrorCode: 3819
Message: Check constraint 'geo_chk_1' is violated.
2 rows in set (0.00 sec)
3、JSON_SCHEMA_VALIDATION_REPORT()查看验证报告
语法:JSON_SCHEMA_VALIDATION_REPORT(schema,document)
该函数会以JSON文档的形式返回一个关于验证结果的报告。如果验证成功,返回{"valid": true}。如果JSON文档验证失败,该函数将返回一个JSON对象,该对象包含下面列出的属性:
valid:false
reason:失败原因
schema-location:校验失败的位置
document-location:失败位置
schema-failed-keyword:关键字或属性名
mysql> SET @schema = '{'> "id": "http://json-schema.org/geo",'> "$schema": "http://json-schema.org/draft-04/schema#",'> "description": "A geographical coordinate",'> "type": "object",'> "properties": {'> "latitude": {'> "type": "number",'> "minimum": -90,'> "maximum": 90'> },'> "longitude": {'> "type": "number",'> "minimum": -180,'> "maximum": 180'> }'> },'> "required": ["latitude", "longitude"]'>}';
Query OK, 0 rows affected (0.01 sec)mysql> SET @document = '{'> "latitude": 63.444697,'> "longitude": 10.445118'>}';
Query OK, 0 rows affected (0.00 sec)mysql> SELECT JSON_SCHEMA_VALIDATION_REPORT(@schema, @document);
+---------------------------------------------------+
| JSON_SCHEMA_VALIDATION_REPORT(@schema, @document) |
+---------------------------------------------------+
| {"valid": true} |
+---------------------------------------------------+
1 row in set (0.00 sec)
mysql> SET @document = '{'> "latitude": 63.444697,'> "longitude": 310.445118'> }';mysql> SELECT JSON_PRETTY(JSON_SCHEMA_VALIDATION_REPORT(@schema, @document))\G
*************************** 1. row ***************************
JSON_PRETTY(JSON_SCHEMA_VALIDATION_REPORT(@schema, @document)): {"valid": false,"reason": "The JSON document location '#/longitude' failed requirement 'maximum' at JSON Schema location '#/properties/longitude'","schema-location": "#/properties/longitude","document-location": "#/longitude","schema-failed-keyword": "maximum"
}
1 row in set (0.00 sec)mysql> SET @document = '{}';
Query OK, 0 rows affected (0.00 sec)mysql> SELECT JSON_PRETTY(JSON_SCHEMA_VALIDATION_REPORT(@schema, @document))\G
*************************** 1. row ***************************
JSON_PRETTY(JSON_SCHEMA_VALIDATION_REPORT(@schema, @document)): {"valid": false,"reason": "The JSON document location '#' failed requirement 'required' at JSON Schema location '#'","schema-location": "#","document-location": "#","schema-failed-keyword": "required"
}
1 row in set (0.00 sec)mysql> SET @schema = '{'> "id": "http://json-schema.org/geo",'> "$schema": "http://json-schema.org/draft-04/schema#",'> "description": "A geographical coordinate",'> "type": "object",'> "properties": {'> "latitude": {'> "type": "number",'> "minimum": -90,'> "maximum": 90'> },'> "longitude": {'> "type": "number",'> "minimum": -180,'> "maximum": 180'> }'> }'>}';
Query OK, 0 rows affected (0.00 sec)mysql> SELECT JSON_SCHEMA_VALIDATION_REPORT(@schema, @document);
+---------------------------------------------------+
| JSON_SCHEMA_VALIDATION_REPORT(@schema, @document) |
+---------------------------------------------------+
| {"valid": true} |
+---------------------------------------------------+
1 row in set (0.00 sec)
4、JSON_PRETTY()格式化输出
语法:JSON_PRETTY(json_val)
将 JSON 格式化输出。
SELECT JSON_PRETTY('123'); # scalar
+--------------------+
| JSON_PRETTY('123') |
+--------------------+
| 123 |
+--------------------+SELECT JSON_PRETTY("[1,3,5]"); # array
+------------------------+
| JSON_PRETTY("[1,3,5]") |
+------------------------+
| [1,3,5
] |
+------------------------+SELECT JSON_PRETTY('{"a":"10","b":"15","x":"25"}'); # object
+---------------------------------------------+
| JSON_PRETTY('{"a":"10","b":"15","x":"25"}') |
+---------------------------------------------+
| {"a": "10","b": "15","x": "25"
} |
+---------------------------------------------+SELECT JSON_PRETTY('["a",1,{"key1":"value1"},"5", "77" ,{"key2":["value3","valueX","valueY"]},"j", "2" ]')\G # nested arrays and objects
*************************** 1. row ***************************
JSON_PRETTY('["a",1,{"key1":"value1"},"5", "77" ,{"key2":["value3","valuex","valuey"]},"j", "2" ]'): ["a",1,{"key1": "value1"},"5","77",{"key2": ["value3","valuex","valuey"]},"j","2"
]
5、JSON_STORAGE_FREE()计算空间
MySQL 8.0 新增的,与 Partial Updates 有关,用于计算 JSON 文档在进行部分更新后的剩余空间。
CREATE TABLE jtable (jcol JSON);
INSERT INTO jtable VALUES ('{"a": 10, "b": "wxyz", "c": "[true, false]"}');
-- 更新,结果:{"a": 10, "b": "wxyz", "c": 1}
UPDATE jtable SET jcol = JSON_SET(jcol, "$.a", 10, "$.b", "wxyz", "$.c", 1);
-- 结果:14
SELECT JSON_STORAGE_FREE(jcol) FROM jtable;-- 连续的部分更新对这个空闲空间的影响是累积的,如下例所示,使用JSON_SET()来减少具有键b的值所占用的空间(并且不做任何其他更改):
UPDATE jtable SET jcol = JSON_SET(jcol, "$.a", 10, "$.b", "wx", "$.c", 1);
-- 结果:16
SELECT JSON_STORAGE_FREE(jcol) FROM jtable;-- 不使用JSON_SET()、JSON_REPLACE()或JSON_REMOVE()更新列意味着优化器不能就地执行更新;在这种情况下,JSON_STORAGE_FREE()返回0,如下所示:
UPDATE jtable SET jcol = '{"a": 10, "b": 1}';
-- 结果:0
SELECT JSON_STORAGE_FREE(jcol) FROM jtable;-- JSON文档的部分更新只能在列值上执行。对于存储JSON值的用户变量,该值总是被完全替换,即使使用JSON_SET()执行更新也是如此:
SET @j = '{"a": 10, "b": "wxyz", "c": "[true, false]"}';
SET @j = JSON_SET(@j, '$.a', 10, '$.b', 'wxyz', '$.c', '1');
SELECT @j, JSON_STORAGE_FREE(@j) AS Free; -- 结果:0-- 对于JSON文本,该函数总是返回0:
SELECT JSON_STORAGE_FREE('{"a": 10, "b": "wxyz", "c": "1"}') AS Free; -- 结果:0
6、JSON_STORAGE_SIZE()计算空间
语法:JSON_STORAGE_SIZE(json_val)
MySQL 5.7.22 引入的,用于计算 JSON 文档的空间使用情况。
CREATE TABLE jtable (jcol JSON);
INSERT INTO jtable VALUES ('{"a": 1000, "b": "wxyz", "c": "[1, 3, 5, 7]"}');
SELECT jcol, JSON_STORAGE_SIZE(jcol) AS Size, JSON_STORAGE_FREE(jcol) AS Free FROM jtable;
+-----------------------------------------------+------+------+
| jcol | Size | Free |
+-----------------------------------------------+------+------+
| {"a": 1000, "b": "wxyz", "c": "[1, 3, 5, 7]"} | 47 | 0 |
+-----------------------------------------------+------+------+
1 row in set (0.00 sec)UPDATE jtable SET jcol = '{"a": 4.55, "b": "wxyz", "c": "[true, false]"}';
SELECT jcol, JSON_STORAGE_SIZE(jcol) AS Size, JSON_STORAGE_FREE(jcol) AS Free FROM jtable;
+------------------------------------------------+------+------+
| jcol | Size | Free |
+------------------------------------------------+------+------+
| {"a": 4.55, "b": "wxyz", "c": "[true, false]"} | 56 | 0 |
+------------------------------------------------+------+------+
1 row in set (0.00 sec)-- json文本显示占用存储空间
SELECT JSON_STORAGE_SIZE('[100, "sakila", [1, 3, 5], 425.05]') AS A,JSON_STORAGE_SIZE('{"a": 1000, "b": "a", "c": "[1, 3, 5, 7]"}') AS B,JSON_STORAGE_SIZE('{"a": 1000, "b": "wxyz", "c": "[1, 3, 5, 7]"}') AS C,JSON_STORAGE_SIZE('[100, "json", [[10, 20, 30], 3, 5], 425.05]') AS D;
+----+----+----+----+
| A | B | C | D |
+----+----+----+----+
| 45 | 44 | 47 | 56 |
+----+----+----+----+
1 row in set (0.00 sec)
八、JSON字段创建索引
同 TEXT,BLOB 字段一样,JSON 字段不允许直接创建索引。
即使支持,实际意义也不大,因为我们一般是基于文档中的元素进行查询,很少会基于整个 JSON 文档。
对文档中的元素进行查询,就需要用到 MySQL 5.7 引入的虚拟列及函数索引。
# C2 即虚拟列
# index (c2) 对虚拟列添加索引。
create table t ( c1 json, c2 varchar(10) as (JSON_UNQUOTE(c1 -> "$.name")), index (c2) );insert into t (c1) values ('{"id": 1, "name": "a"}'), ('{"id": 2, "name": "b"}'), ('{"id": 3, "name": "c"}'), ('{"id": 4, "name": "d"}');mysql> explain select * from t where c2 = 'a';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t | NULL | ref | c2 | c2 | 43 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)mysql> explain select * from t where c1->'$.name' = 'a';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t | NULL | ref | c2 | c2 | 43 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
可以看到,无论是使用虚拟列,还是文档中的元素来查询,都可以利用上索引。
注意,在创建虚拟列时需指定 JSON_UNQUOTE,将 c1 -> “$.name” 的返回值转换为字符串。
参考文档
https://dev.mysql.com/doc/refman/8.0/en/json.html
https://blog.csdn.net/java_faep/article/details/125206014
https://zhuanlan.zhihu.com/p/514819634?utm_id=0
https://blog.csdn.net/sinat_20938225/article/details/129471550
GeoJSON:https://dev.mysql.com/doc/refman/8.0/en/spatial-geojson-functions.html
json方法:https://dev.mysql.com/doc/refman/8.0/en/json-functions.html
json索引:https://dev.mysql.com/doc/refman/8.0/en/create-table-secondary-indexes.html#json-column-indirect-index
json多值索引:https://dev.mysql.com/doc/refman/8.0/en/create-index.html#create-index-multi-valued