如何建设旅游网站东莞品牌网站制作
一、前言篇
1.
1. AI 绘图是什么?
AI 绘画,顾名思义就是利用人工智能进行绘画,是人工智能生成内容(AIGC)的一个应用场景。其主要原理简单来说就是收集大量已有作品数据,通过算法对它们进行解析,最后再生成新作品,而算法也便是 AI 绘画的核心,是它得以爆火的基础。

1)Midjourney 是什么?
Midjourney 是一个由 Midjourney 研究实验室开发的人工智能程序,可根据文本生成图像,目前架设在 Discord 频道上。于 2022 年 7 月 12 日进入公开测试阶段,使用者可通过 Discord 的机器人指令进行操作,可以创作出很多的图像作品。

2)Discord 频道是什么?
Discord 是前几年诞生的非常火的一种新型聊天工具,类似 QQ、微信群。
Midjourney 的使用方式是:通过给 Discord 频道内的聊天机器人发送对应文本,聊天机器人返回对应的图片。
所以想用 Midjourney,需要先注册一个 discord 账号,然后进入 Midjourney 的 Discord 频道。我们注册了账号之后,可以用浏览器使用 discord,也可以下载他们的客户端。

3)AI 绘图前景如何?
AI 绘图在未来有很大的前景,因为它具有以下几个方面的优势:

① 自动化程度高
AI 绘图可以通过算法和数据自动化生成绘图,减少人工操作和错误,提高效率和准确性。
② 精度高
AI 绘图可以利用深度学习和神经网络等技术对大量的图像进行学习和训练,从而提高绘图的精度和质量。
③ 可扩展性强
AI 绘图可以通过不断地学习和训练来不断提高其绘图的能力和品质,随着技术的不断发展,其绘图的应用范围也会不断扩大。
④ 可定制化
AI 绘图可以根据用户的需求进行定制,根据不同的绘图场景和目的,生成不同的绘图结果。
⑤ 应用广泛
AI 绘图可以应用于多个领域,例如设计、建筑、艺术、医疗、教育等,为人们提供更加便捷和高效的绘图解决方案。
然而,AI 绘画本身存在着一个非常大的争议——版权问题。AI 绘画的核心是模型,而训练它则需要使用大量数据,其中不可避免的会出现未经授权的图片。另外,经过运算之后所生成的图像版权究竟归属于谁在目前也尚未有定论,使得部分艺术家对 AI 绘画表示反对。因此,要实现市场的良性发展,版权或许是 AI 绘画行业首先需要解决的问题。

随着时代向 Web3.0、元宇宙、虚拟人等等这些代表着未来的概念迈进,AI 技术现如今正在以一个令大众应接不暇的速度发展,绘画领域出现 AI 的身影是发展的必然,而 AI 绘画近月来的爆火也只是在技术不断积累之下的爆发。作为下一代互联网中图像领域的未来最大生产力,在版权问题得到规范之后,AI 未来的市场潜力是超乎想象的。

4)设计师怎么把握这个趋势?
首先,AI 绘画可以为设计师提供更多的设计灵感和创作元素。AI 绘画可以模仿人类绘画的艺术风格和风格元素,为设计师提供更多的参考和灵感,使得设计师可以更加轻松地完成作品。
其次,AI 绘画可以提高设计效率和质量。与传统的绘画方式相比,AI 绘画可以通过自动化和算法优化,快速生成高质量的设计作品,节省设计师的时间和精力。
但是,AI 绘画也可能对设计师造成威胁。一方面,AI 绘画可能会取代一些设计师的工作。特别是一些简单的设计任务,如图标设计、平面设计等,可能会被 AI 绘画完全取代,使得这些设计师的就业机会受到影响。

作为设计师,我们可以将 AI 绘图作为辅助工具,来帮助我们快速的实现设计想法,提供更多的灵感和创意。我们需要不断地学习和更新自己的技能,以保持与时俱进。了解最新的技术和工具,研究和探索 AI 绘图的潜力和应用,探索如何将 AI 绘图应用到更广泛的设计领域中,这样才能更好地适应未来的设计趋势。
二、注册篇:
注册使用需要魔法,我们不提供任何帮助,可以使用国内大神开发的免魔法版本:https://www.bijianxiezuo.com/
三、操作篇
1.
1. 如何用 Midjourney 创作你的第一幅 AI 作品
1)关键词生成图片
回到我们的服务器,然后在下面的输入框输入“/”,它会弹出一系列的命令(如果没弹窗,退出重新登录即可),我们先点击“/imagine”(这个参数我后面再做详细解释),然后会出现如下画面:
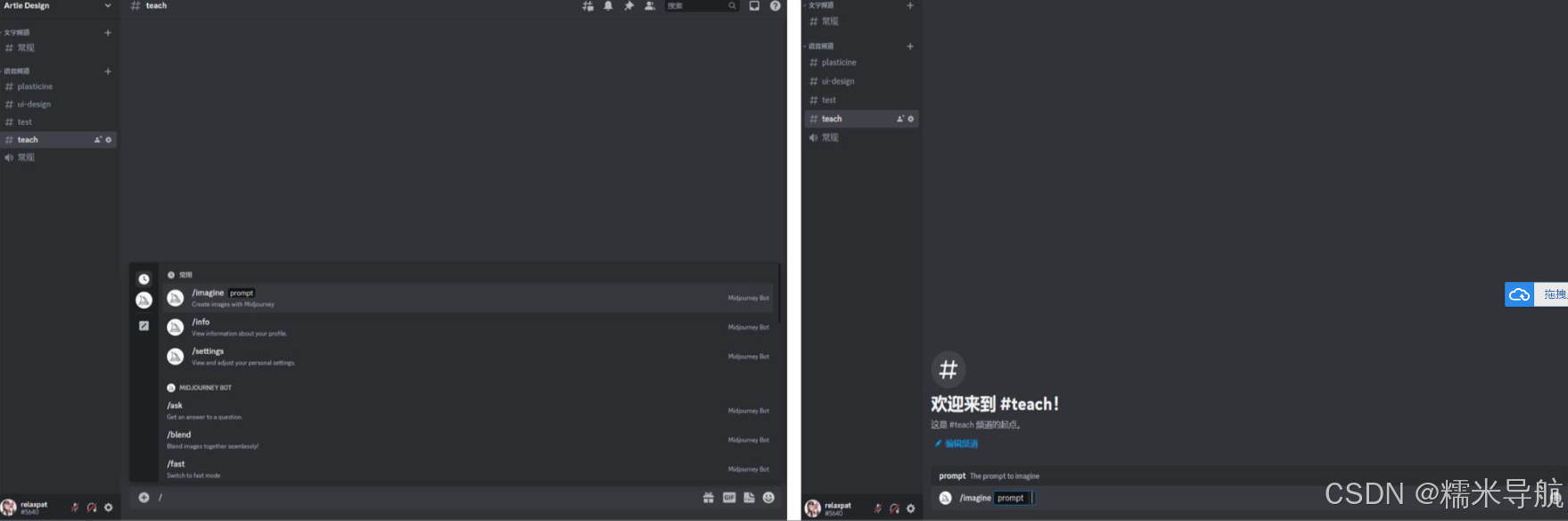
输入一组关键词,切记:一组关键词的后面需要加上英文的逗号“,”然后按空格键,空一格就行,看我下面这组关键词:
An mascot robot, smiling, modern robot, round robot, cartoon, flying, fist up, crypto coins background
(吉祥物机器人,微笑,现代机器人,圆形机器人,卡通,飞行,拳头,加密币背景)
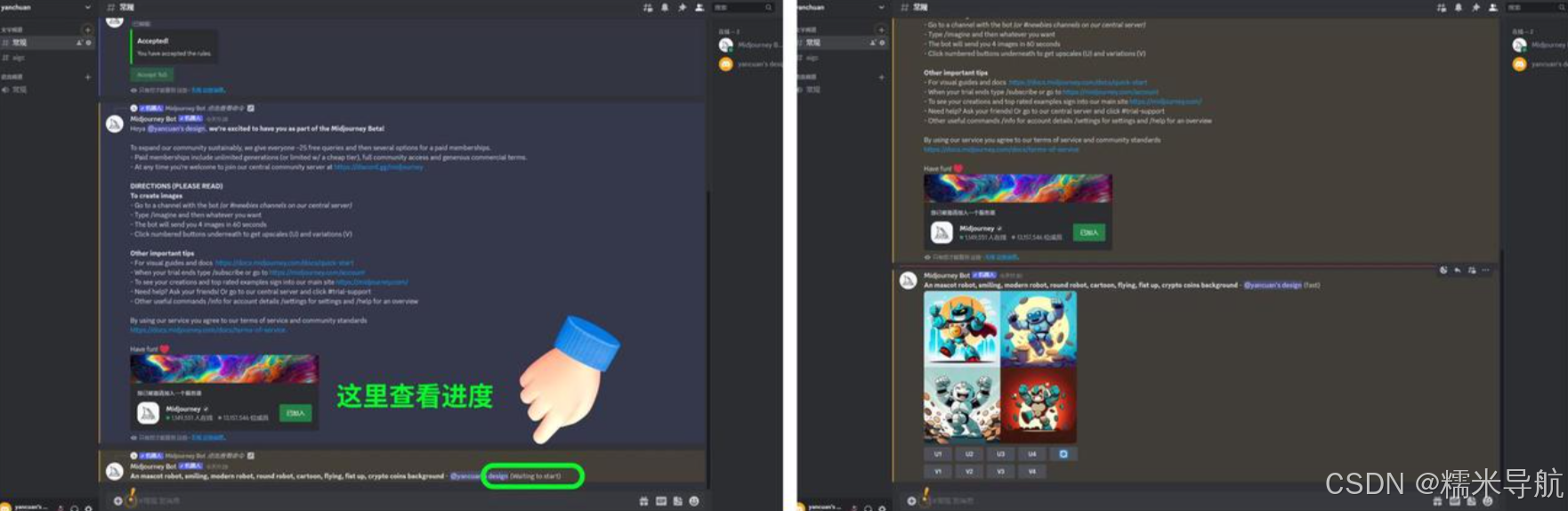
然后我们接着上一步,在对话框内输入这组关键词,我建议大家不要直接复制,先用键盘敲,体验下这个操作。
点击回车发送,然后它会让我们进行授权,我们点击“Accept tos”授权就行了。

然后等待机器人的出图,在发送的关键词后面可以看到图片生成的进度,等一会就会出来图片了:
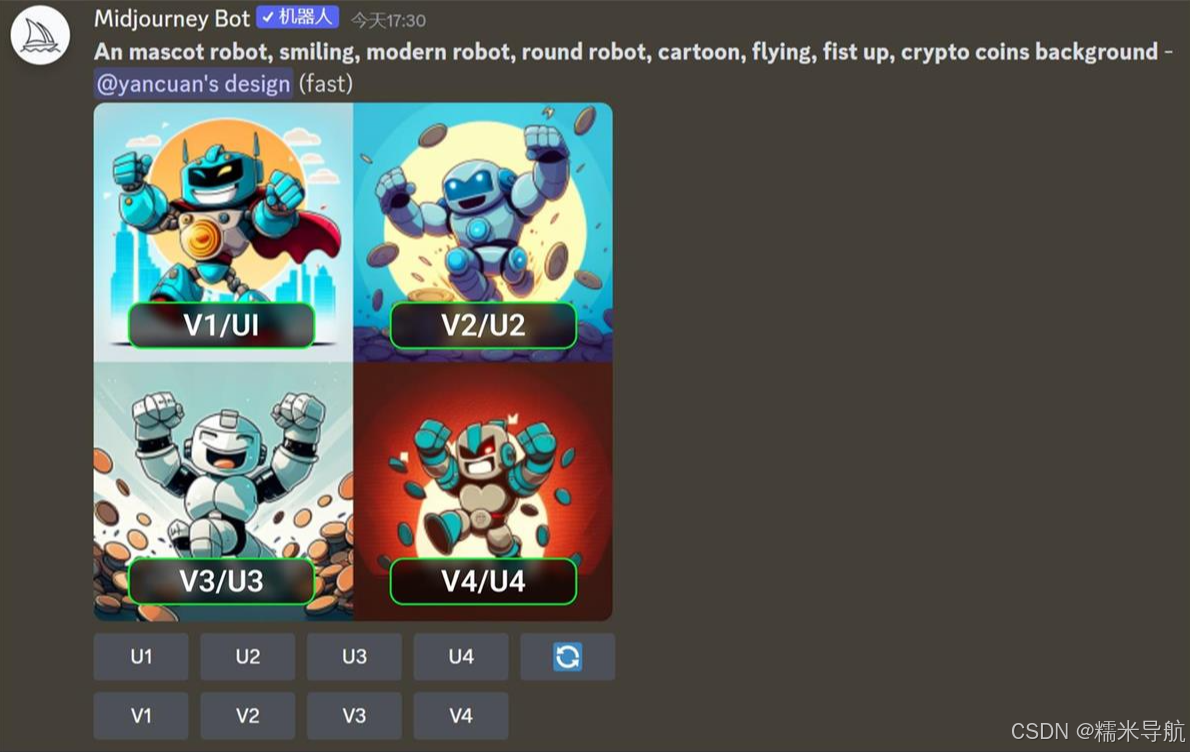
2)图片指令及导出图片
生成完成后,会出现两排按钮
U 的意思放大图片,U1/U2/U3/U4 分别指的是放大四张图片中的某一张
V 的意思采用图片的构图形式,重新生成一组类似的图片,V1/V2/V3/V4 的顺序与 U 的顺序一样,如图
举个栗子,比如我想要导出第一张图片,那么我们点击 U1 就好了(等待机器出图):
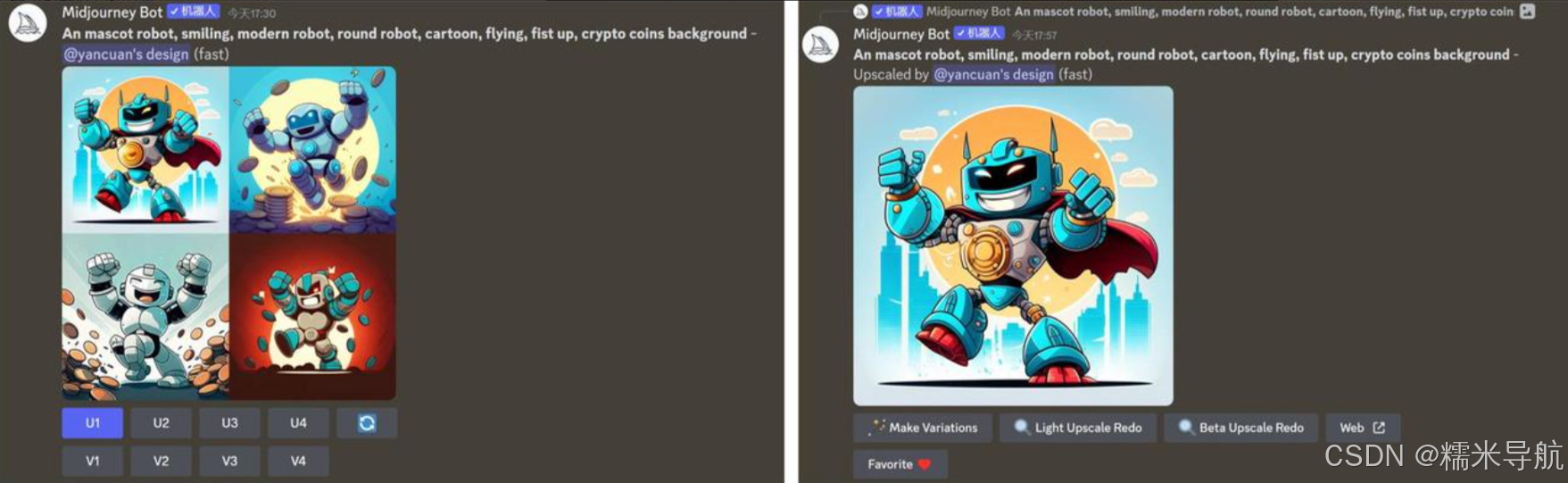
然后咱们点击图片,点击在浏览器中打开,然后保存图片,这张图片就被下载了(一定要用浏览器打开再保存图片,不然图片的尺寸会很小,会模糊的)
换个栗子,我觉得第一张图片还行,构图风格还不错,就是差点细节,想要再优化下,那我们就点击 V1,接下来的操作就与上面一样啦,是不是很简单。
一般情况下,我们可以把同一组关键词多生成几组图片,这里可以点击“重复”按钮,然后你就会看见多条生成图片的消息,等待机器人作图,然后找到你喜欢的几张图片进行挑选即可。
3)Midjourney 的尺寸和分辨率
所有尺寸均为正方形 1:1 的长宽比。
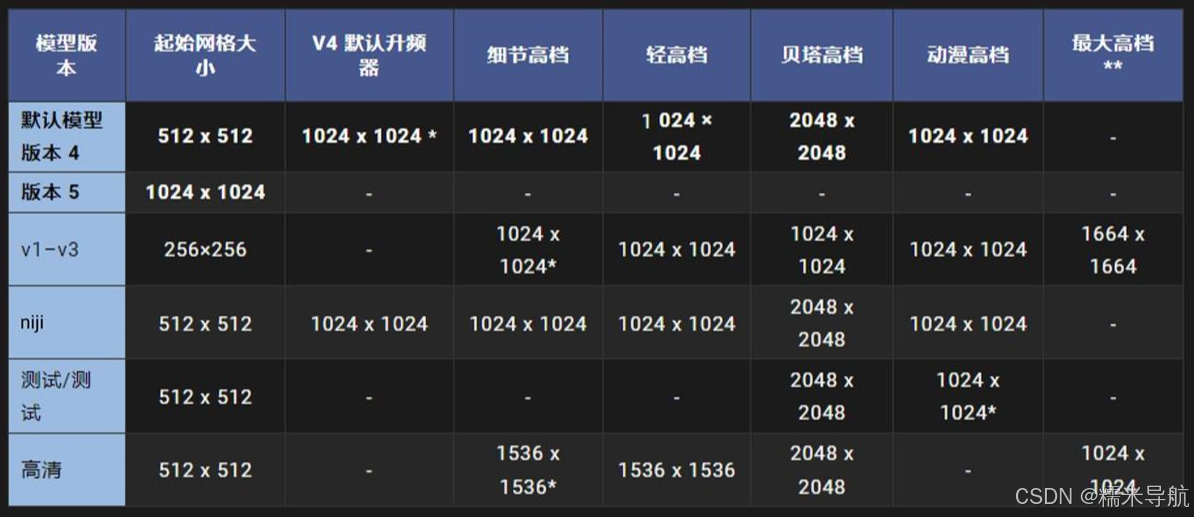
每个 Midjourney 版本模型的默认升频器。
4)使用高档重做按钮
升级图像(U1、U2、U3、U4)后,你会在图像下方看到一行按钮,可让您使用不同的升级器模型重新进行升级。
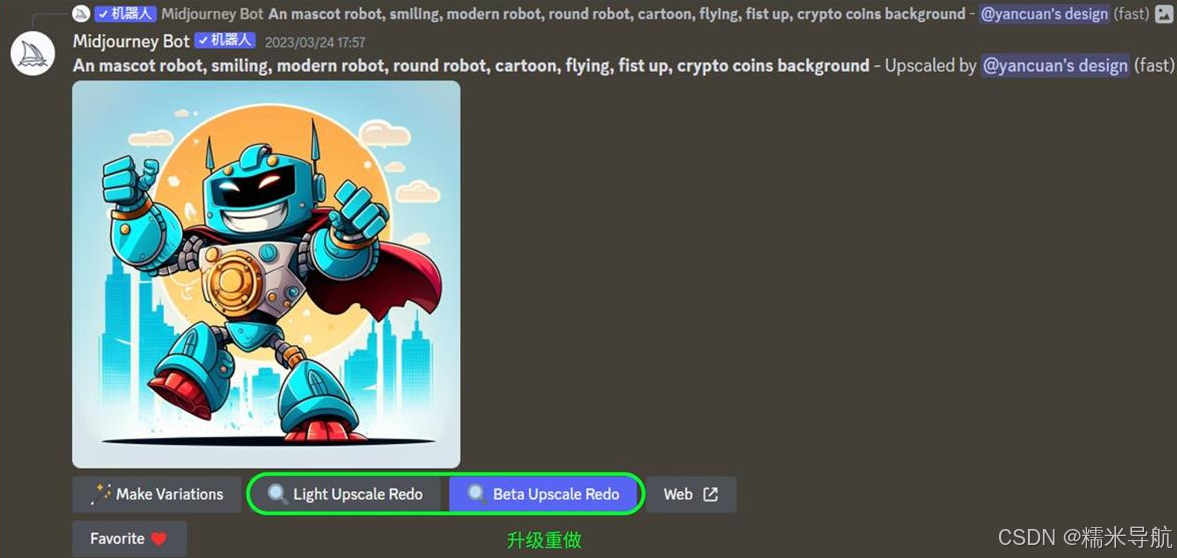
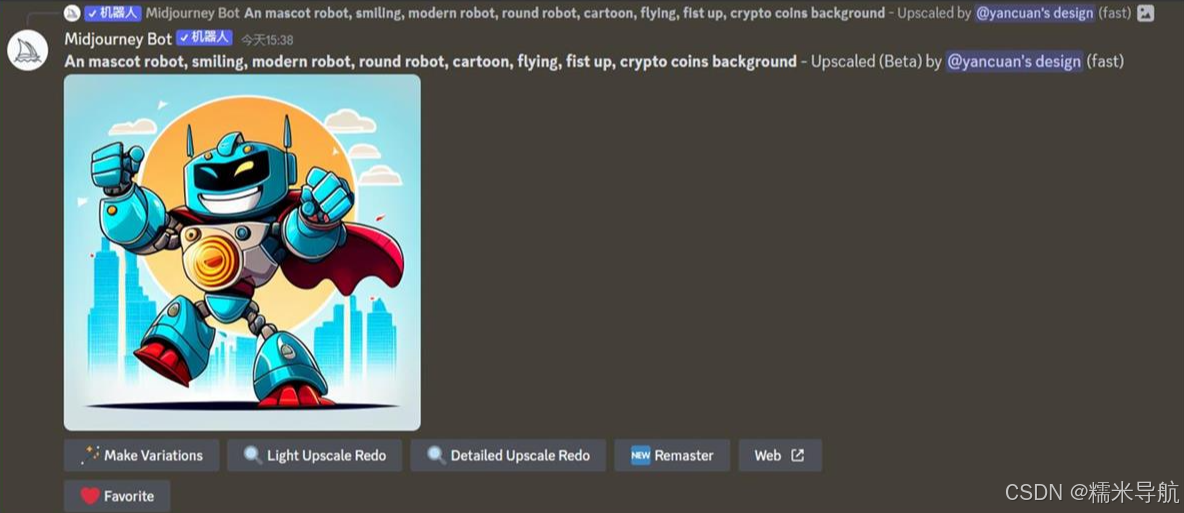
点击重做,Midjourney 会在原图的基础上优化和调整细节,有些情况重做的效果不如原效果,根据情况调整。
2.
2. AI 绘画描述词分享
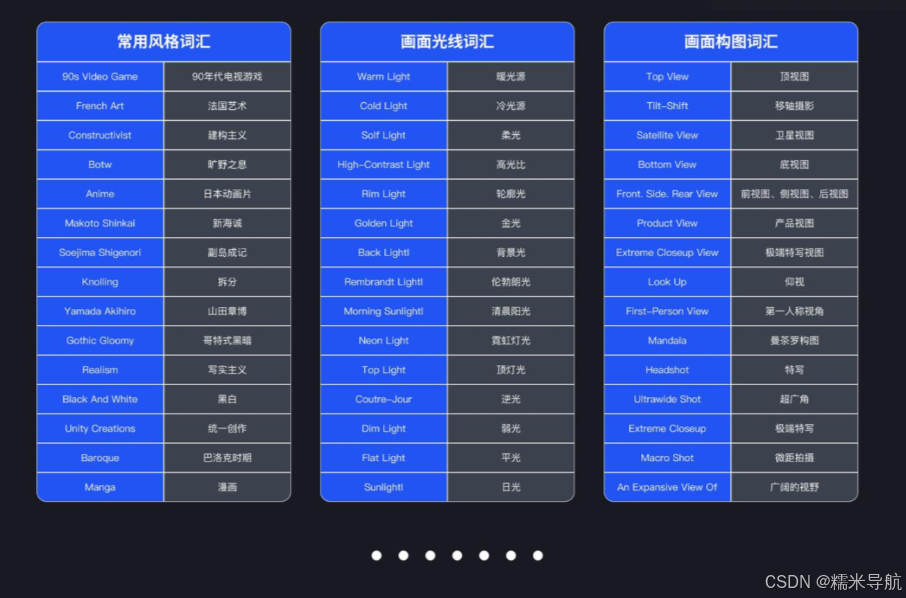
这里给大家分享下关键词词汇,帮助大家更快的掌握 AI 绘图,篇幅有限,有需要的朋友可以试试这个网站:
Midlibrary! 收录 2000+ 风格关键词的 Midjourney 提示资源库
今天为大家推荐一个实用超强的 Midjourney 提示词资源网站 Midlibrary,它由国外艺术家 Andrei Kovalev 主导建立,目前收录了 2078 种适用于 Midjourney 的风格流派、艺术运动、技法及艺术家关
3.
3. Discor 操作命令
1)基本命令概述
(这里只列出一些我们会用到的参数命令,其他的参数对我们学习 AI 绘画意义不大)
1.
/ask 获取问题的答案。你可以提一些问题让 midjourney 给你回答,类似 FAQ;
2.
/blend 融图,一共可以上传 6 张图片,发送给机器人会帮你把上传的图片融合一起生成新的一组图片;
3.
/docs 在官方的 Midjourney Discord 服务器中使用,可以快速生成本用户指南中涉及的主题链接;
4.
/fast 切换到快速模式,一般还有 Fast 使用时长不需要切换这个命令;
5.
/help 显示关于 Midjourney Bot 的有用基本信息和提示,帮助中心,字面意思;
6.
/imagine 使用提示生成一个图像,这个就是生图的命令,输入关键词发送;
7.
/info 查看关于你的账户和任何排队或运行中的工作的信息,可以查看账户的剩余作图时长等相关信息;
8.
/stealth 对于专业计划的用户(60 美金/月):切换到隐身模式。意思是你生成的图片不在社 区展示;
9.
/piblic 对于专业计划的用户(60 美金/月):切换到公共模式,字面意思;
10.
/subscribe 为用户的帐户页面生成个人链接;
11.
/settings 查看和调整 Midjourney Bot 的设置;
12.
/prefer option set 创建或管理一个自定义选项;
13.
/prefer option list 查看你当前的自定义选项;
14.
/prefer suffix 指定一个后缀,添加到每个提示的末尾;
15.
/show 使用图像作业 ID,在 Discord 内重新生成作业;
16.
/relax 切换到放松模式。这个模式比 Fast 慢