如何充实网站内容标书制作收费
一、源码描述
这是一款简洁十分美观的ASP.NET+sqlserver源码,界面十分美观,功能也比较全面,比较适合 作为毕业设计、课程设计、使用,感兴趣的朋友可以下载看看哦
二、功能介绍
该源码功能十分的全面,具体介绍如下:
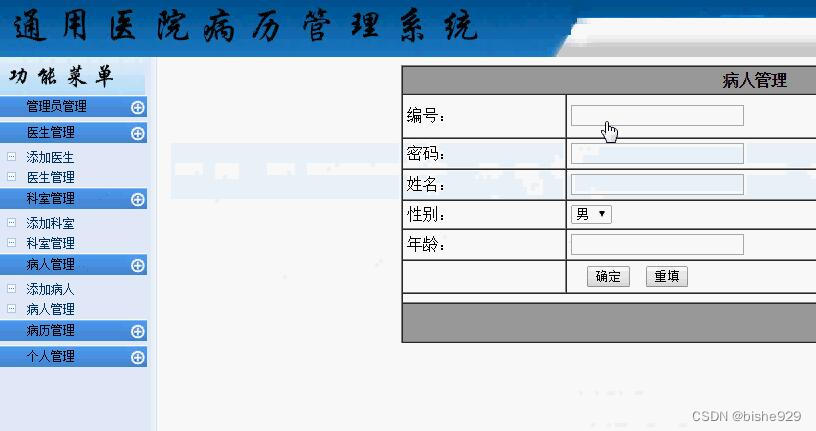
通用医院病历管理系统分为管理员,病人和医生三个角色,每个角色有自己不同的功能,共同来完成医院病历的智能化和信息化管理
管理员部分功能
管理员管理,管理本系统内的管理员信息
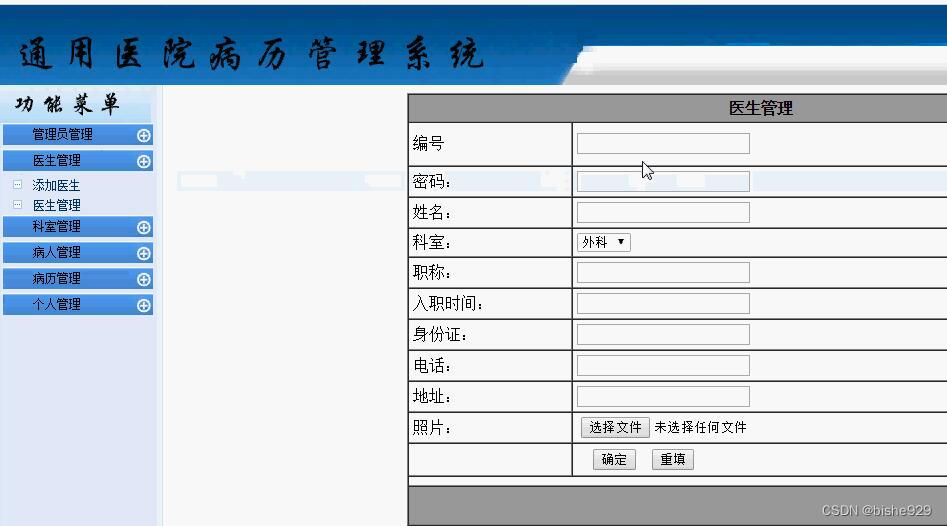
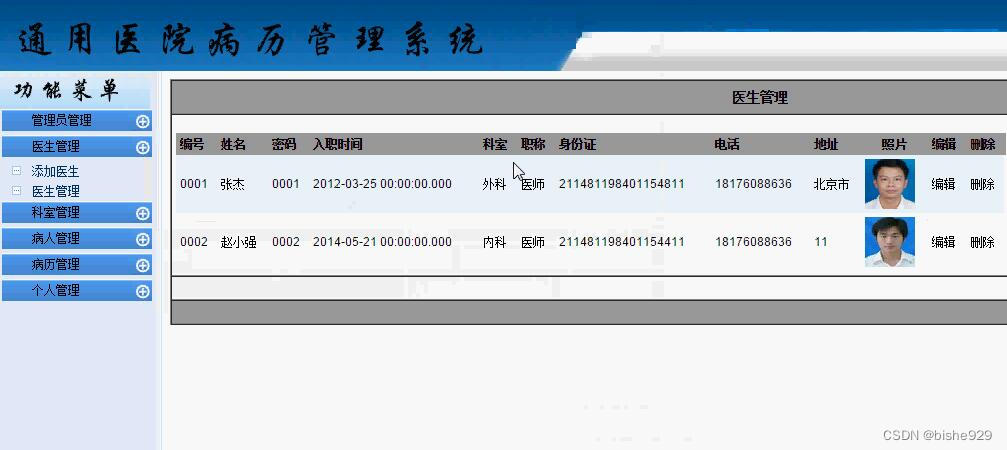
医生管理,管理本系统内的医生信息
科室管理,管理本系统内的科室信息
病人管理,管理本医院系统内的所有病人信息
病历管理,管理医院内的所有的病历信息
个人管理,管理员管理自己的个人信息
医生部分功能
病人管理,医生可以管理自己的病人信息
病历管理,管理自己所属的病人的病历信息
留言管理,对病人的留言信息进行管理,包括回复和删除等操作
个人管理,医生可以管理自己的个人信息
病人部分功能
病历管理, 病人可以查看自己的病历信息
留言管理,病人可以给医生进行留言,更好的配合治疗
个人管理,管理自己的个人信息

三、源码特点
按照毕业设计的具体需求,基于Internet信息服务(IIS)平台,系统需要的环境是Windows7及以上系统,基于WEB的网络编程开发语言C#,所以需要开发人员熟练使用C#语言进行网络编程,以及运用SQL语言对相关数据库进行操作。操作人员还应具有一定的数据库开发功底及编程能力
四、注意事项
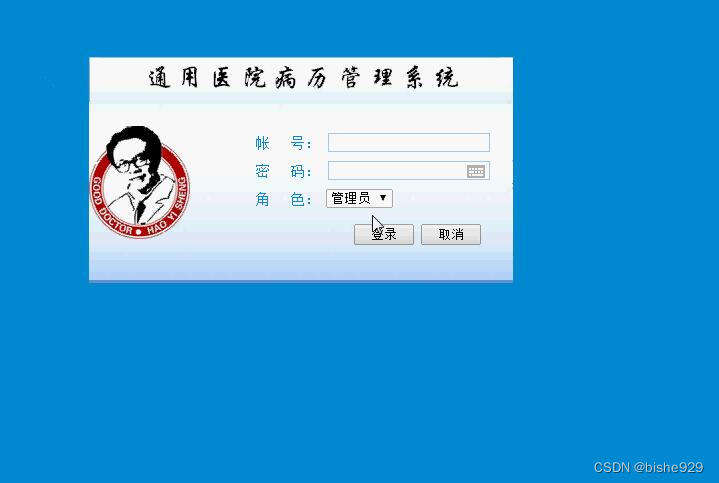
1、后台管理员用户名密码均是:admin
2、开发环境为Visual Studio 2010,数据库为SQL Server 2005,使用.net 2.0开发。
3、数据库文件在数据库文件夹中,附加即可
4、默认数据库连接字符串在webconfig配置文件中修改。