芜湖做的好的招聘网站a市最牛的网站
使用 External Tools 偏好设置可设置用于编写脚本、处理图像和进行源代码控制的外部应用程序。
External Script Editor:选择 Unity 应使用哪个应用程序来打开脚本文件。Unity 会自动将正确的参数传递给内置支持的脚本编辑器。Unity 内置支持 Visual Studio Community、Visual Studio Code (VSCode) 和 JetBrains Rider。Open by file extension 选项会将设备的默认应用程序用于打开相关的文件类型。如果没有默认应用程序可用,设备会打开一个窗口,提示选择用于打开文件的应用程序。
详细说明可以查看Unity手册:Preferences - Unity 手册
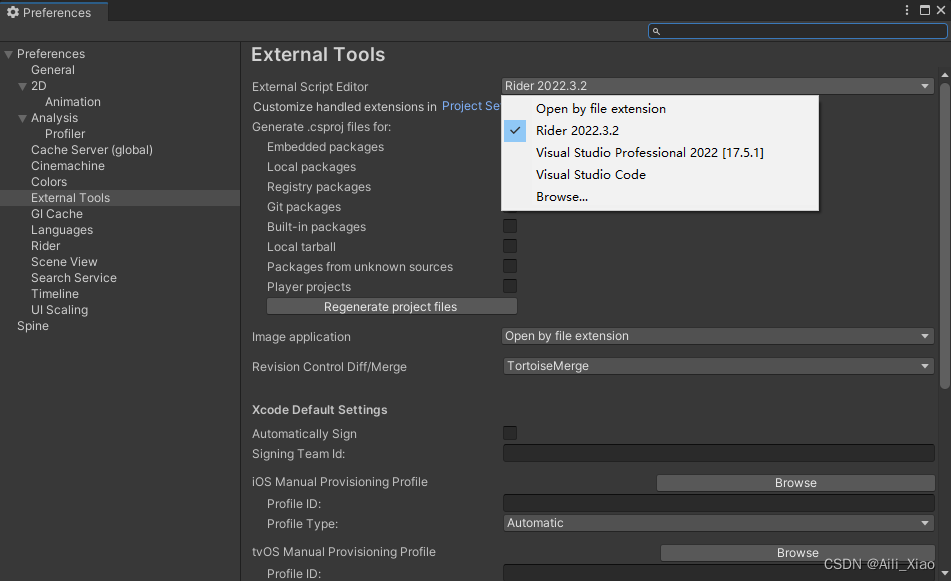
但在项目开发时可能会出现多个项目解决方案,这时候为了方便,可能会在菜单中自定义打开。
在使用Unity提供的方法 EditorUtility.OpenWithDefaultApp 中会将解决方案使用默认的打开方式打开,如果电脑上有多个IDE时,默认打开方式可能不是想用的程序,这时候就可以使用 External Script Editor 设定的值来打开。
想拿到 External Tools 中的 External Script Editor 值,可以通过:CodeEditor.CurrentEditor 和 CodeEditor.CurrentEditorInstallation 来获取。
CodeEditor.CurrentEditor:获取当前代码编辑的可能执行文件包
CodeEditor.CurrentEditorInstallation:获取当前代码编辑器的安装路径
拿到当前 External Script Editor 执行程序的文件路径后,可以通过 CodeEditor.OSOpenFile 方法执行打开指定的解决方案。
public static bool OSOpenFile(string appPath, string arguments)
appPath:传入 CodeEditor.CurrentEditorInstallation 的值
arguments:传入指定的解决方案路径
示例:
[MenuItem("Tools/编辑XLua脚本", false, 99998)]static void EditorGameScripts(){CodeEditor.OSOpenFile(CodeEditor.CurrentEditorInstallation, Path.Combine(Application.dataPath,"../LuaScripts.sln"));}