长春建站公司网站压缩wordpress空间
概述
前后端网络请求工具
- 原生ajax
- fetch api
- axios
GET和POST请求
get只能发纯文本
post可以发不同类型的数据,要设置请求头,需要告诉服务器一些额外信息
测试服务器地址
有一些公共的测试 API 可供学习和测试用途。这些 API 允许你发送 HTTP 请求(GET、POST 等),并从服务器获取响应。以下是一些常用的公共测试 API:
- JSONPlaceholder:
- Base URL: https://jsonplaceholder.typicode.com
- Example Endpoints:
- Posts:
/posts - Comments:
/comments - Users:
/users
- Posts:
- Usage Example (GET): https://jsonplaceholder.typicode.com/posts/1
- ReqRes:
- Base URL: https://reqres.in
- Example Endpoints:
- Users:
/api/users - Single User:
/api/users/2 - Create User:
/api/users
- Users:
- Usage Example (POST): https://reqres.in/api/users
原生ajax
前端页面代码
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<script src="ajax_get.js"></script>
</body>
</html>
GET
//原生ajax
const xhr = new XMLHttpRequest();
//xhr.open('GET', 'http://wuyou.com/common/get');
xhr.open('GET', 'https://jsonplaceholder.typicode.com/posts/1')
xhr.send();
xhr.onreadystatechange = function(){if(xhr.readyState == XMLHttpRequest.DONE && xhr.status === 200){console.log(JSON.parse(xhr.responseText));}
}
返回结果

POST
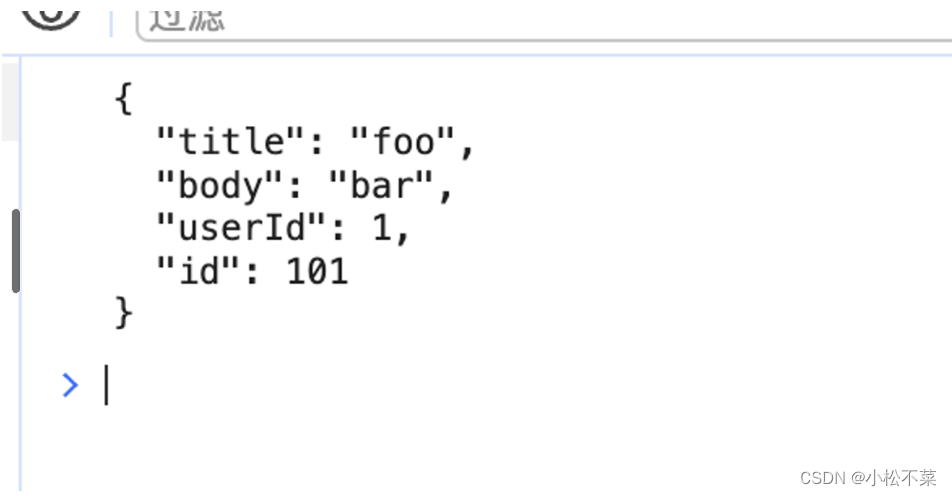
const xhr = new XMLHttpRequest();
xhr.open('POST', 'https://jsonplaceholder.typicode.com/posts');
xhr.setRequestHeader('Content-Type', 'application/json'); // 修改 Content-Type
xhr.send(JSON.stringify({title: 'foo',body: 'bar',userId: 1
}));xhr.onreadystatechange = function() {if (xhr.readyState === XMLHttpRequest.DONE && xhr.status === 201) {console.log(xhr.responseText); // 不解析 JSON,直接输出响应文本}
};
返回结果
Axios
前端页面代码
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<script src="axios.min.js"></script>
<script src = 'axiosjs.js'></script>
</body>
</html>
直接传输
最简单的axios使用方式,get函数中填写请求的url
//用axios来get一个请求
axios.get('https://jsonplaceholder.typicode.com/posts/1').then(response => {console.log('GET Response:', response.data);}).catch(error => {console.error('GET Error:', error);});
返回结果

异步传输
用异步的方式传输,在axios中配置地址,请求/响应拦截器
//异步请求处理
//异步发送get请求
(async () => {try {const ins = axios.create({baseURL: 'https://jsonplaceholder.typicode.com',});// 请求拦截器ins.interceptors.request.use((config) => {console.log('发送了请求');return config;});// 响应拦截器ins.interceptors.response.use((response) => {// 在这里可以对响应数据进行处理return response.data;},(error) => {// 在这里处理响应错误return Promise.reject(error);});const res = await ins.get('/posts/1');const res2 = await ins.post('/posts', {title: 'foo',body: 'bar',userId: 1,});console.log('GET 的结果:', res);console.log('POST 的结果:', res2);} catch (error) {console.error('发生错误:', error);}
})();
返回结果

Fetch
前端页面代码
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<script src = 'fetch_get.js'></script>
</body>
</html>
GET请求
fetch('https://jsonplaceholder.typicode.com/posts/1')
.then(res => {if(res.ok){return res.json()}
})
.then(data =>{console.log(data)}).catch(error =>{console.error(error)
})
结果:

POST请求
在参数处需要传入一些配置项
//post在参数的地方需要传入一些配置项const postData = {title: 'foo',body: 'bar',userId: 1
};
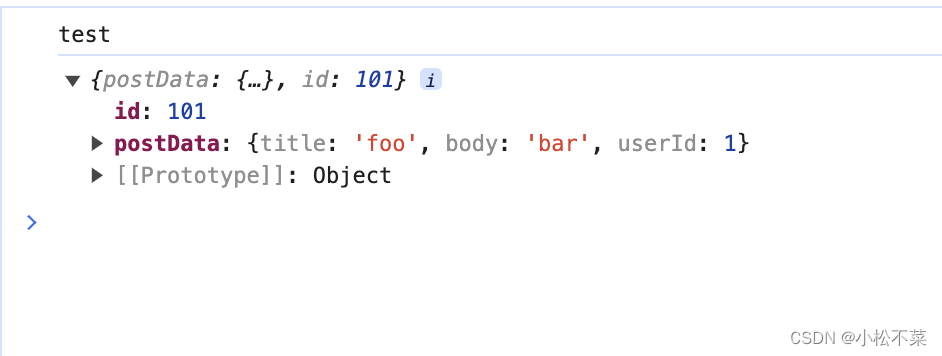
console.log("test")
fetch('https://jsonplaceholder.typicode.com/posts', {method: 'POST',headers:{'Content-Type': 'application/json'},body:JSON.stringify({postData})}
).then(res =>{if(res.ok){return res.json()}
})
.then(data =>{console.log(data)}
)
结果