网站建设与开发做什么什么是响应式网站设计
大多数使用 PDF 文档的用户都熟悉处理这种格式的文件时出现的困难。有些人仍然认为注释 PDF 的唯一方法是打印文档,使用笔或荧光笔然后扫描回来。
您可能需要向 PDF 添加注释、添加注释、覆盖一些文本或几何对象。经理、部门负责人在编辑公司内的合同、订单、发票或任何其他文件时可能需要采取此类行动。今天我们将向您展示如何在Windows操作系统上注释PDF文档。
使用奇客PDF编辑器免费注释 PDF
下载奇客PDF注释器,安装并打开软件。上传文档并切换到“注释”模式。所有必要的工具都可以在左侧菜单中找到,请参阅下面的屏幕截图。
奇客PDF编辑-PDF文档内容编辑轻松搞定奇客PDF编辑-PDF文档内容编辑轻松搞定,像编辑Word一样编辑PDF,一切如此简单。![]() https://www.geekersoft.cn/geekersoft-pdf-editor.html
https://www.geekersoft.cn/geekersoft-pdf-editor.html
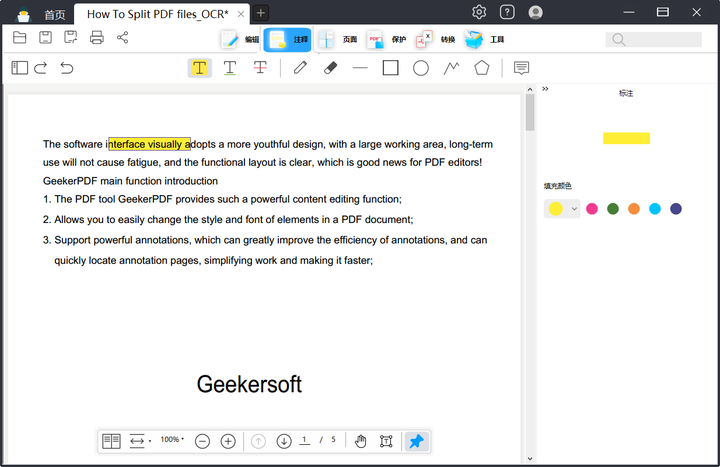
现在让我们仔细看看所有可能的 PDF 注释工具。
打开文件后,点击“注释”按钮,跳转到PDF注释界面,可以添加的注释功能主要有:高亮、下划线、删除线、铅笔、橡皮擦、直线、矩形、圆形、折线、多边形、便签。
1. 手势
旨在快速移动文档并查找必要的信息。选择该工具并按住鼠标左键将纸张沿所需方向移动。
2. 选择
用它来选择对象和文本。选择图形以移动或调整其大小。请注意,它仅适用于在“注释 PDF”模式中添加的对象。
3. 文字
在 PDF 上书写,在文本顶部添加注释,或添加新段落并在末尾添加文档摘要。您可以选择字体类型和大小,以及颜色和对齐方式(左对齐、右对齐或对齐)。
4. 邮票
有标准的PDF 印章,例如“已接受”、“免责”、“禁止”等,以及定制设计。您可以输入自己的文本、添加时间戳或上传图像以用它来注释 PDF。
5. 便利贴
向 PDF 添加注释并用颜色突出显示。这样你就可以给你的论文留下长评论。
6. 高亮区域
突出显示文档的随机区域和自定义区域。选择背景颜色并调整透明度。因此,您可以吸引读者注意文档的某些重要部分,例如不准确之处或段落。
7.突出显示文本
文本突出显示是 PDF 注释工具,用于指示订单、说明、合同中的重要信息。从广泛的调色板中选择 7 种标准颜色和 5 种自定义颜色中的一种颜色。
8. 下划线
该工具为 PDF 中的文本添加下划线。线条颜色由用户设置,如第 7 点所示。
9. 三振
划掉错误信息和不必要的内容以进行进一步编辑。
10. 矩形
指出文档的重要区域。该对象有一个框架和一个颜色填充,其色调可以更改。此外,您还可以调整轮廓的粗细和背景的透明度。按住 Ctrl 键绘制一个正方形。
11. 圆圈
与“矩形”类似,它选择文档中的一个区域,只是它具有圆形形状。填充和轮廓颜色的设置,以及后者的厚度和背景的透明度也可用。按住 Ctrl 键绘制一个完美的圆。
12. 线
PDF注释器这个工具用于标记非文本内容或绘制直线。
13. 箭头
用它来指示重要部分或您的论文,指定说明中的操作顺序等。您也可以自定义颜色和厚度。
14. 铅笔
使用鼠标光标在 PDF 上绘图。使用它来编辑图片、表格中的小瑕疵,以及创建您自己的签名或以您能想到的任何其他可能的方式编辑 PDF。
15.橡皮擦
该注释工具用于擦除“铅笔”。在其设置中,您可以更改活动区域的大小,以便更准确和高质量地处理较小的对象。
谁可能需要学习注释 PDF
设计师。该领域的专家将会欣赏 PDF 编辑器的技术能力。您可能需要使用 PDF 来创建初步设计的草图,因为这种格式最常用于创建建筑物的图纸和技术计划。此外,网络工作室设计师可能需要在 PDF 上绘制客户提供的徽标、表格、产品说明等元素。那么,奇客PDF将成为解决此类任务不可或缺的助手。
会计师、经济学家。该 PDF 编辑器非常擅长识别表格中的文本,因此,如果您在检查报告时遇到任何错误,您可以立即更正它们,而无需创建新文档。通过这种方式,金融公司的员工将减少在项目上花费的时间,并为管理层提供准确的数据。
管理。该程序将有助于主管起草工作描述、雇佣合同以及对重大交易文件进行更正。这使您可以指出所有缺点并直接对 PDF 进行注释。
学生和老师。PDF 编辑器对于大学生和教育工作者创建论文、项目和研究生资格作品、准备实践报告非常有用。强大的功能和灵活的设置将使您能够创建合适的项目以获得优异的成绩。
编辑、文案、内容经理。客户通常以 PDF 格式提供有关其产品的信息。为了提取图像、规格、公司标签,您需要一个强大的工具。在这种情况下,奇客PDF将是一个很好的解决方案。
其他 PDF 编辑专业人员。该程序拥有大量的 PDF 注释和编辑工具以及清晰的界面。它既适合新手用户,也适合经验丰富的专业人士。
PDF离线注释方式总结
现在您知道如何使用 Windows 离线编辑器对 PDF 进行注释。它旨在帮助用户创建高质量的文档、合同和说明。此外,该程序是免费分发的,任何人都可以使用它,无论经验或年龄如何。下载 PDF 编辑器并充分利用该软件的所有功能。好好工作!
我们使用PDF注释功能,主要是为了给PDF文件进行标记和注释,就像我们在阅读纸质版文件和资料的时候,经常会给重点做一定的标记或添加便签等等。通过本文我们之前奇客PDF编辑器是如何给PDF文件添加注释的。