网站设计制作哪家好大连建设工程信息网官网入口
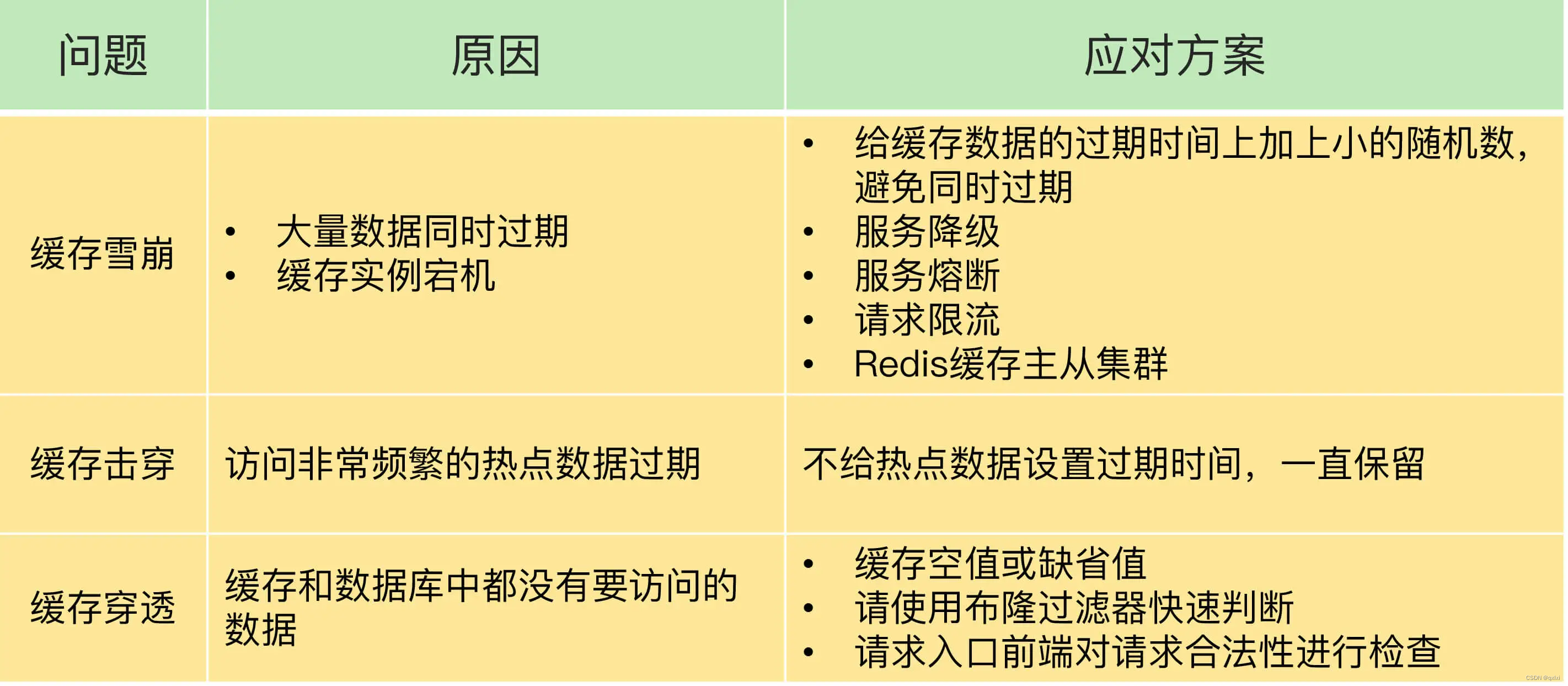
缓存的引入带来了数据读取性能的提升,但是因此也引入新的问题,一个是数据双写一致性,另一个就是雪崩、击穿、穿透,那么如何解决这些问题,我们来说下对应的问题和解决方案
雪崩
缓存雪崩:同一时间内大量请求无法从Redis缓存层获取数据,都将数据请求到数据库层,而导致数据库压力激增。
第一个原因:同一时间内缓存过期,导致无法处理请求
在正常情况下,数据从缓存读取到数据直接返回,但是当大量缓存同时过期时,比如1S内1W个请求从Redis读取不到数据,那么请求就直接打到MySQL中。MySQL负载会过高。
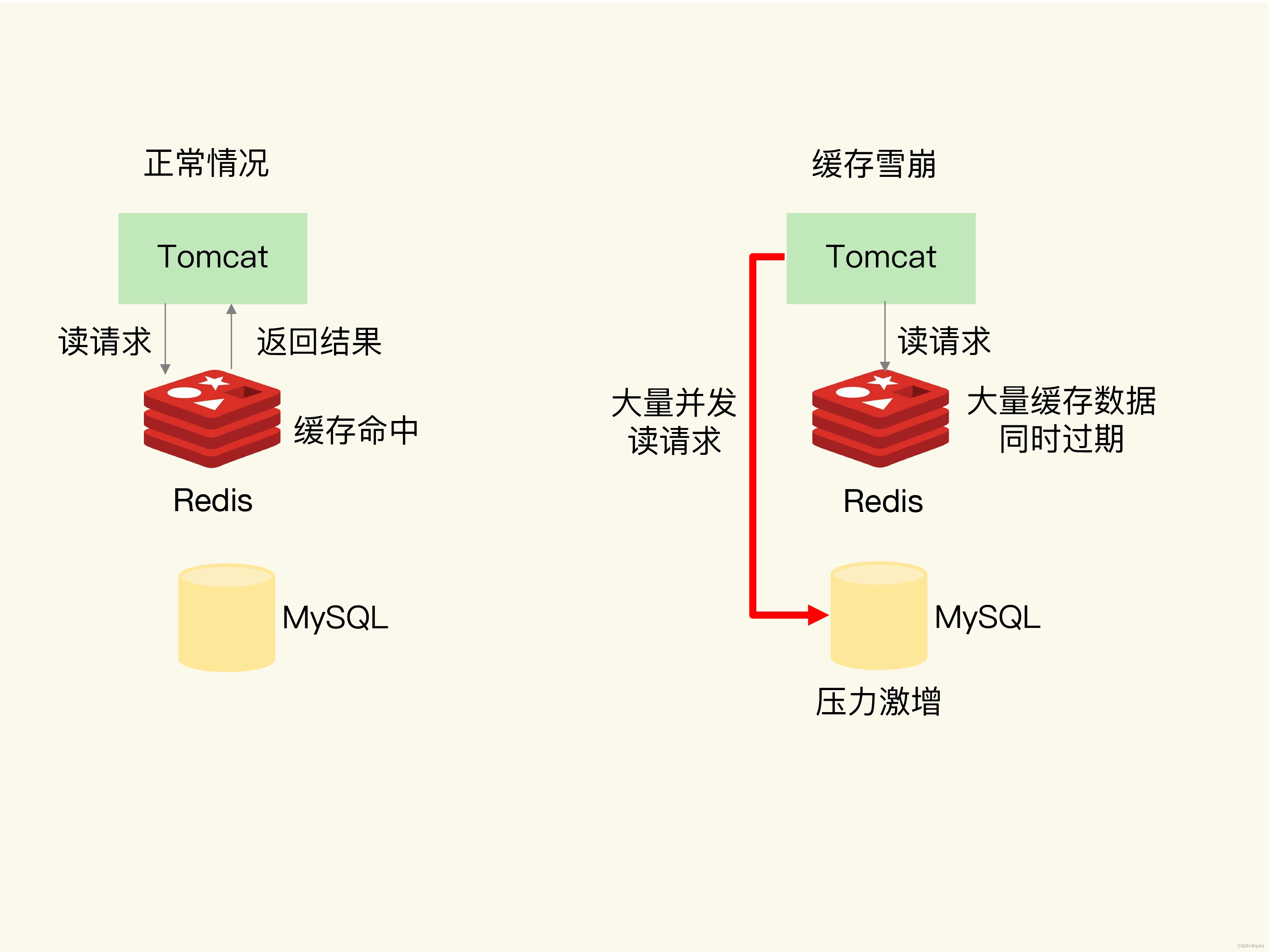
解决方案
1.通过为不同的key设置不同的过期时间,比如随机1-3分钟,以至于不会出现同一时间内大量key数据失效的情况。
2.保证核心业务数据的请求,非核心业务,直接返回配置化数据。也就是服务降级。
这里就要说一个在之前实际经历过的场景,由于业务人员开发的代码BUG,导致一个慢查询一天只会统计一次,但是由于逻辑问题,导致没有查询缓存,每次请求都直接打到数据库,而这个慢SQL很耗费资源,所以出现数据库负载过高,进一步影响到别的业务。
第二个原因:Redis实例宕机
另一个原因则是出现Redis单点宕机,整个缓存层服务无法使用,那么数据请求直接到数据层。
解决方案
一般来说我们需要对请求进行限流,以及降级的方式来保证核心业务的流转,然后非核心业务,直接降级不处理或者别的额方式。这样比直接全部流量进来之后,整个MySQL负载压力小很多。以及我们需要在搭建Redis时候采用主从架构,如果主机宕机,那么备机需要立马切换成主机。
击穿
雪崩是大量的缓存数据失效,而击穿针对的是某个热点key失效,比如微博热搜,top10 如果数据缓存失效,那么都直接达到数据库,数据库肯定承受不住,对于这种情况我们一般不要设置过期时间,以及采用提前预热的方式。
穿透
穿透是从缓存和数据库中都获取不到数据,如果有大量请求查询,那么对缓存和数据库会带来更大的压力。
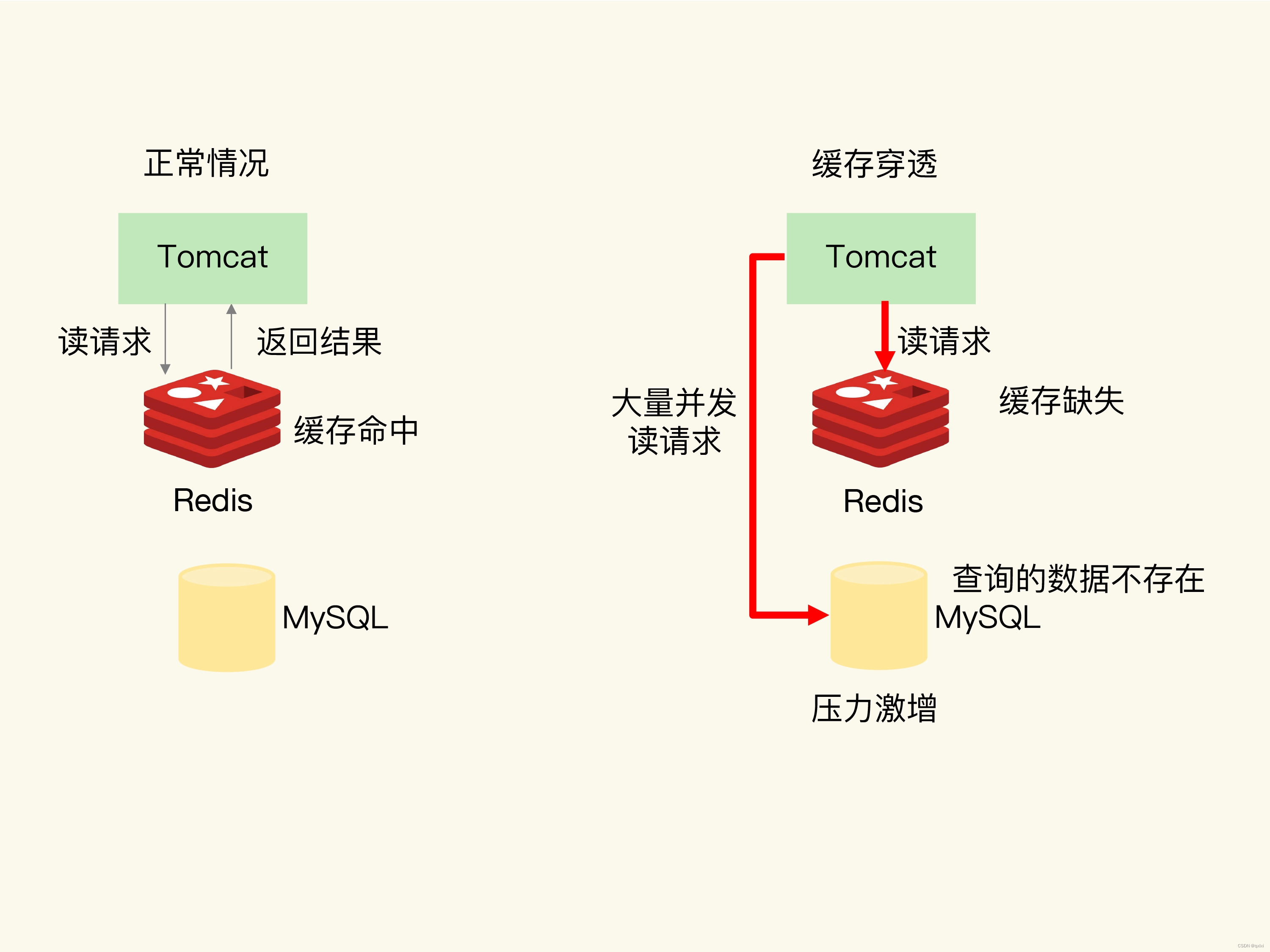
出现的情况,第一要么认为的业务操作,误删除数据和缓存数据,第二个,有人为攻击。
解决方案
1.返回缺省值或者默认值。
2.使用布隆过滤器判断数据是否存在,减轻数据库压力。
3.前端拦截非法请求参数,不请求到数据库。
小结
雪崩是针对大量的缓存失效,而击穿是针对某个热点key,穿透是从数据库中获取不到数据了。