信誉好的电商网站建设wordpress 随机重复
目录
一.高可用群集相关概述
1.高可用(HA)群集与普通群集的比较
普通群集
高可用群集(HA)
两者比较
2.Keepalived高可用方案
3.Keepalived的体系模块及其作用
4.Keepalived实现原理
二.LVS+KeepAlived高可用负载均衡集群的部署
1.配置负载调度器(主、备相同)
1.1.配置keeplived(主、备DR 服务器上都要设置)
2.配置节点服务器
3.配置负载调度器
4.网页测试
一.高可用群集相关概述
1.高可用(HA)群集与普通群集的比较
普通群集
普通的群集的部署是通过一台度器控制调配多台节点服务器进行业务请求的处理,但是仅仅是一台
调度器,就会存在极大的单点故障风险,当该调度器的链路或则调度器本身出现故障时,就会导致
整个业务的无法正常进行

高可用群集(HA)
高可用集群是由一台主调度器和一台或多台备用调度器。在主调度器能够正常运转时,由主调度器
进行节点服务器业务的分配处理,其余备用调度器处于待机状态,不参与当前的集群运转。当主调
度器出现故障无法运转时,此时备用调度器会由优先级最高的调度承担主调度器的工作,而出现故
障的主调调度器便会退出当前工作,由人工维修后返回集群

两者比较
高可用集群只需要在调度器上多进行一台或两台(服务器本身的价格比较昂贵,一般备用的服务器
的数量会和当前业务创造的价值对等)的设置,就可避免因调度器瘫痪业务中断的风险,所以实现
了真正的高可用的效果
2.Keepalived高可用方案
Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故
障问题
在一个LVS服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务
器,但是对外表现为一个虚拟IP(VIP),主服务器会发送VRRP通告信息给备份服务器,当备份
服务器收不到VRRP消息的时候,即主服务器异常的时候,备份服务器就会接管虚拟IP,继续提供
服务,从而保证了高可用性。(主备服务器之间由优先级决定,优先级更高的充当主服务器,优先
级低的成为备份服务器)

3.Keepalived的体系模块及其作用
keepalived体系架构中主要有三个模块,分别是core、check和vrrp
- core模块:为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析。
- vrrp模块:是来实现VRRP协议的。(调度器之间的健康检查和主备切换)
- check模块:负责健康检查,常见的方式有端口检查及URL检查。(节点服务器的健康检查)
4.Keepalived实现原理

二.LVS+KeepAlived高可用负载均衡集群的部署
本次实验部署采用的时KeepAlived的运用与LVS中DR模式的结合,共同部署出高可用的负载均衡
的集群。真实环境还会存在NFS共享目录服务器,考虑在上次的DR实验与NAT实验中都已经展示
了NFS服务器与节点服务器之间的连接,本次若做也是相同的操作步骤,就省略了
设备准备
主DR服务器:192.168.80.104
备DR服务器:192.168.80.105
web服务器1:192.168.80.106
web服务器2:192.168.80.107
客户端:192.168.80.108
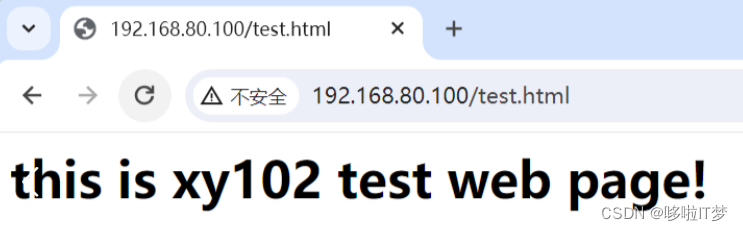
VIP:192.168.80.100
1.配置负载调度器(主、备相同)


1.1.配置keeplived(主、备DR 服务器上都要设置)

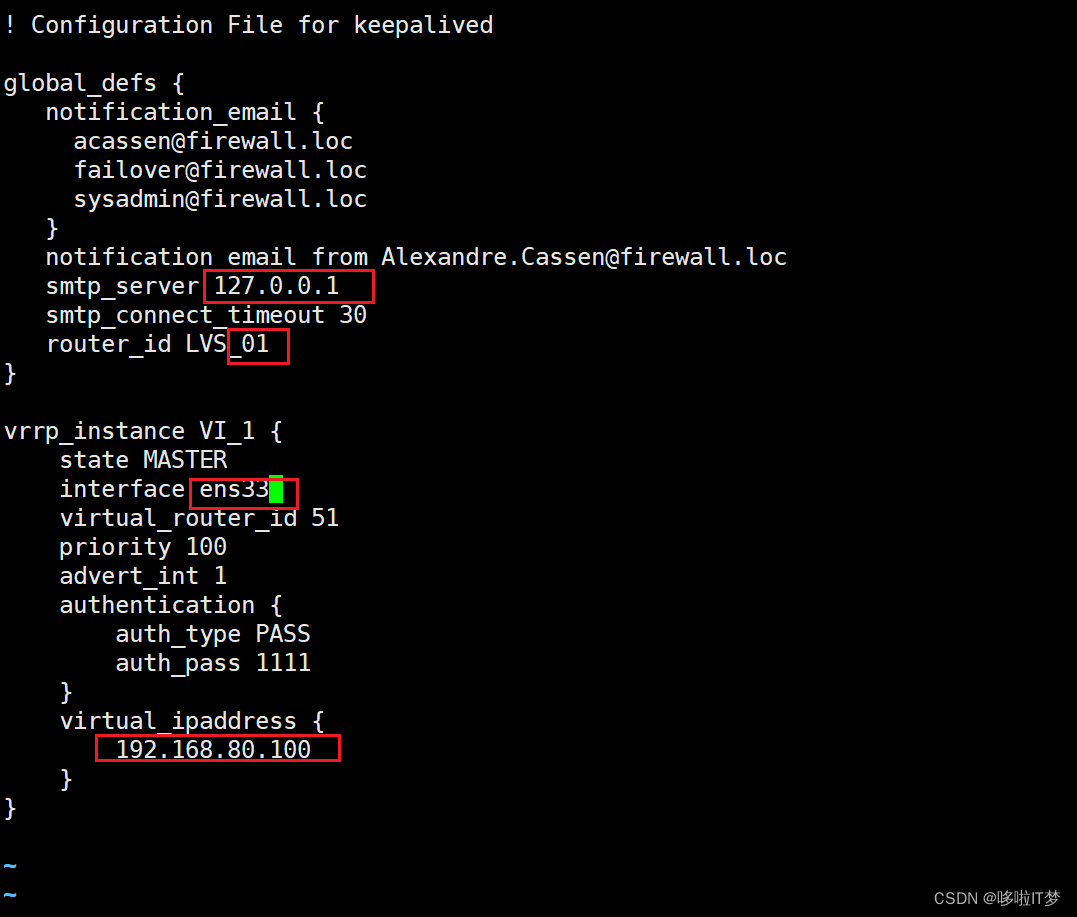
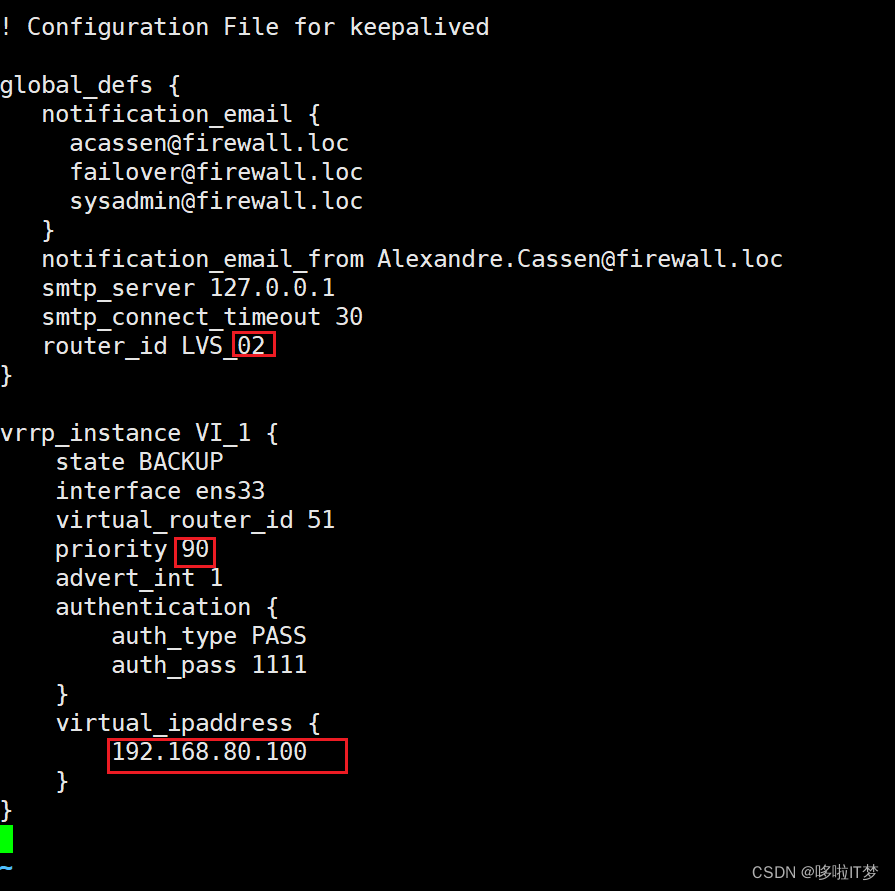
主有备没有


2.配置节点服务器
参考这篇文章的配置节点服务器操作
添加永久生效
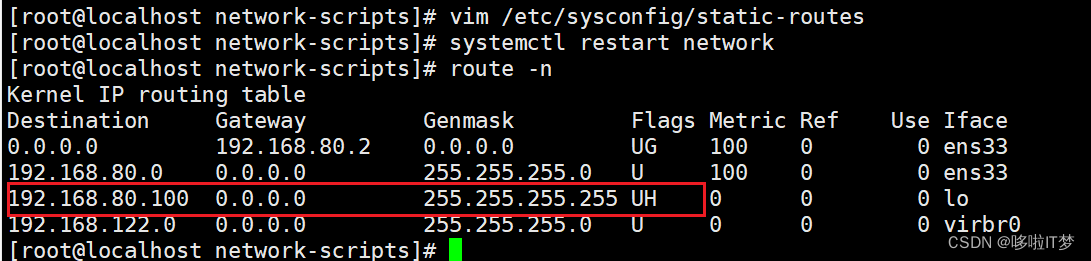

3.配置负载调度器

启动 ipvsadm 服务



复制到备
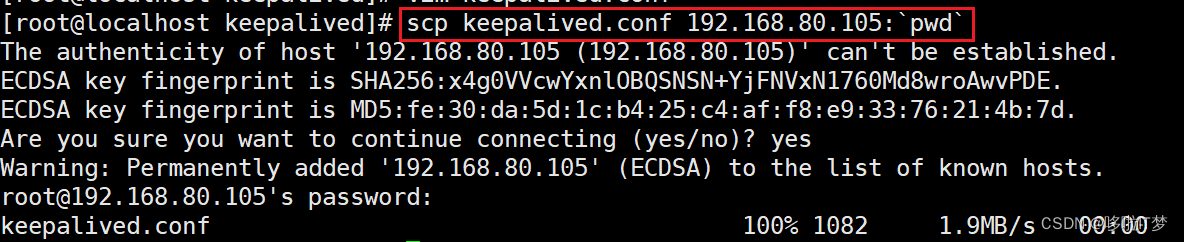


4.网页测试