织梦网站名称改不了萧山网站建设微信 话
写在前面:
首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
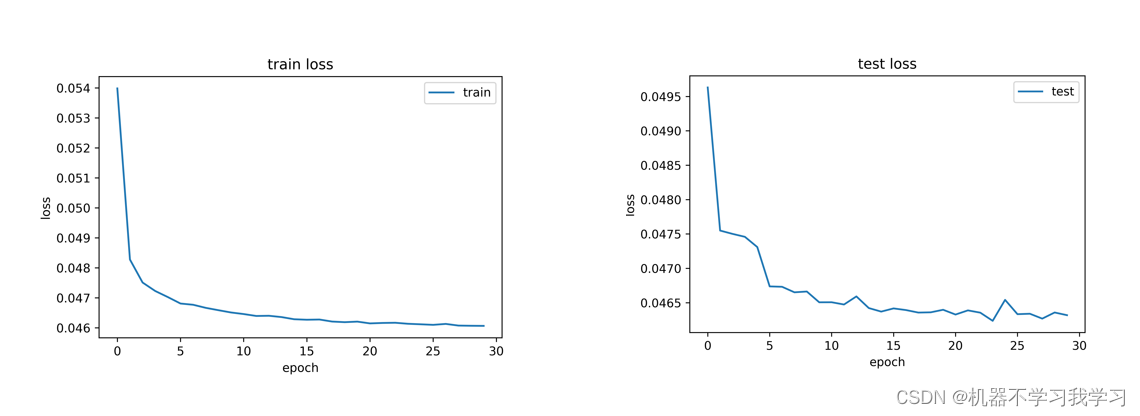
提起LSTM大家第一反应是在NLP的数据集上比较常见,不过在图片分类中,它同样也可以使用。我们以比较熟悉的 mnist 数据集为例进行讲解。当然,你可以根据本教程中得代码,在自定义数据集上训练LSTM图像分类模型。本教程绝对保真,先看一下模型在训练集和测试集山得损失变化:
我们知道mnist数据集是 28*28 的手写数字,而且因为是黑白照片,所以不像彩色图片一样是三通道,只有一个通道。
这里对于数据的理解,我们进行一下简单的介绍:对于每一张图片,我们看作一条数据,就像NLP中的一个句子一样。将照片的每一行看做一个向量,对应一个句子中的词向量,所以很显然,图片的行数就句子的长度。所以对这个 28*28 的照片,就是一个由 28 个向量组成的序列,且每个向量的长度都是 28。在NLP领域中,就是一个有 28 个单词的句子,且每个单词的词向量长度都为 28。
28行28列:
x1_1,x1_2,x1_3,x1_4,x1_5,x1_6, ..., x1_28
x2_1,x2_2,x2_3,x2_4,x2_5,x2_6, ..., x2_28
x3_1,x3_2,x3_3,x3_4,x3_5,x3_6, ..., x3_28
...
x27_1,x27_2,x27_3,x27_4,x27