国内网站怎么做有效果上海网站建设企业排名
黄国强 2024/1/10 acloud@163.com
对任何公司来说,在短时间内开发一款高质量设备专用软件,是一件不太容易做到的事情。麦芯是笔者发明的一款设备软件中间件产品。麦芯致力于给设备厂商提供一个开发工具和平台,让客户快速高效的开发自己的设备专用软件。麦芯从下面几个方面给客户创造价值:
麦芯提供了一个整体框架
客户公司所有设备软件都可以统一到麦芯一个软件平台上开发,从而节约了大量的人力成本,减少了冗余开发,从根本上提高了开发效率。后续人力成本主要投入到应用软件界面和特定设备组件的开发。

上图为麦芯总体架构图,需要客户自己开发的部分,图中用黄颜色标注。
内置常用组件
麦芯内置一个常用组件库,集成了市面上常见的板卡,相机,PLC,机械手等,这个集成过程会一直进行下去,使组件库不断完善。
不限制前台开发语言
麦芯是后台运行的软件,前台应用软件通过Redis访问麦芯。只要支持Redis的软件开发语言,都可以用来开发麦芯前台应用,比如C#,Java甚至JavaScript。
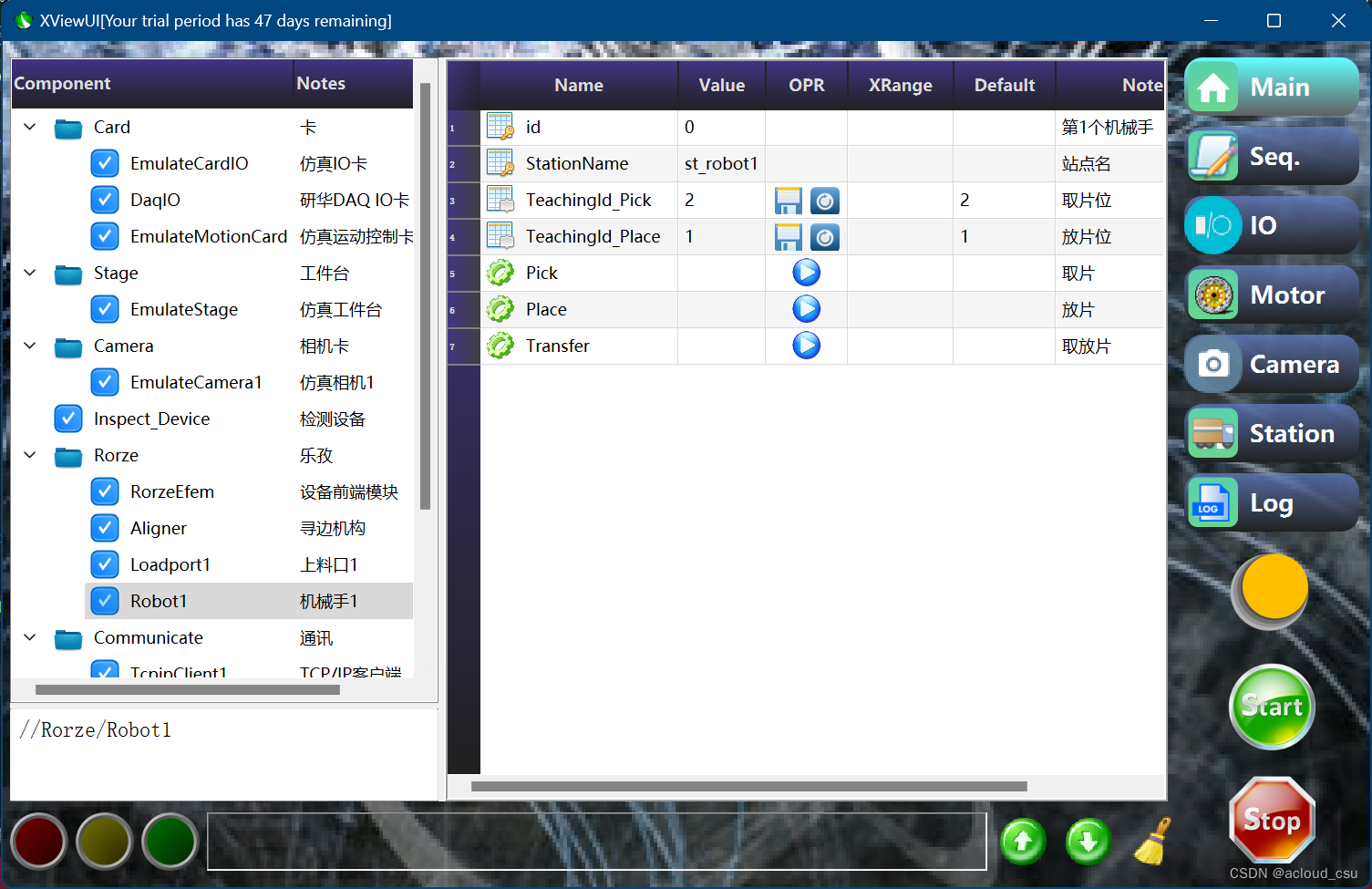
麦芯强大的调试界面
麦芯提供了一个通用调试界面。利用该调试界面,可以为整个开发、调试、生产和后期维护,提供强大的调试工具。
后续文章主要介绍设备组件开发技术。