必知的网站妇科医院免费的咨询
drools8的maven模板项目里没有单元测试, 相比而言drools7有个非常好的test senorios
那就自己弄一个
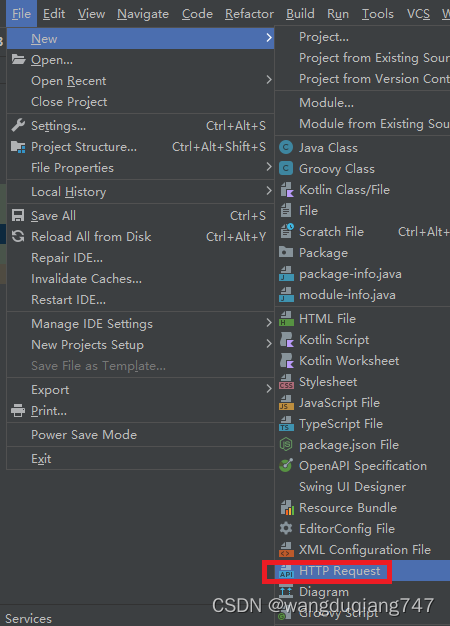
文件是.http后缀的,写了个简单的例子如下
//测试交通违章
POST http://localhost:8080/Traffic Violation
accept: application/json
Content-Type: application/json{"Violation": {"Code": "zzfdsfz","Date": "2023-08-23","Type": "speed","Speed Limit": 10,"Actual Speed": 100},"Driver": {"Name": "string","Age": 0,"State": "string","City": "string","Points": 0}
}> {%
// 这块是对结果的测试
client.test("Request executed successfully", function() {client.assert(response.status === 200, "Response status is not 200");//client.assert(response.status === 203, "Response status is 200");//意思是说,罚金恒等于1000 否则报错"罚金计算错误"client.assert(response.body.Fine.Amount === 1000, "罚金计算错误");});
%}
感觉还不错
下一步应用到k8s里,或者是看原生的微服务是什么东西