免费做背景调查的网站手机设计软件app推荐
先看一幅图:
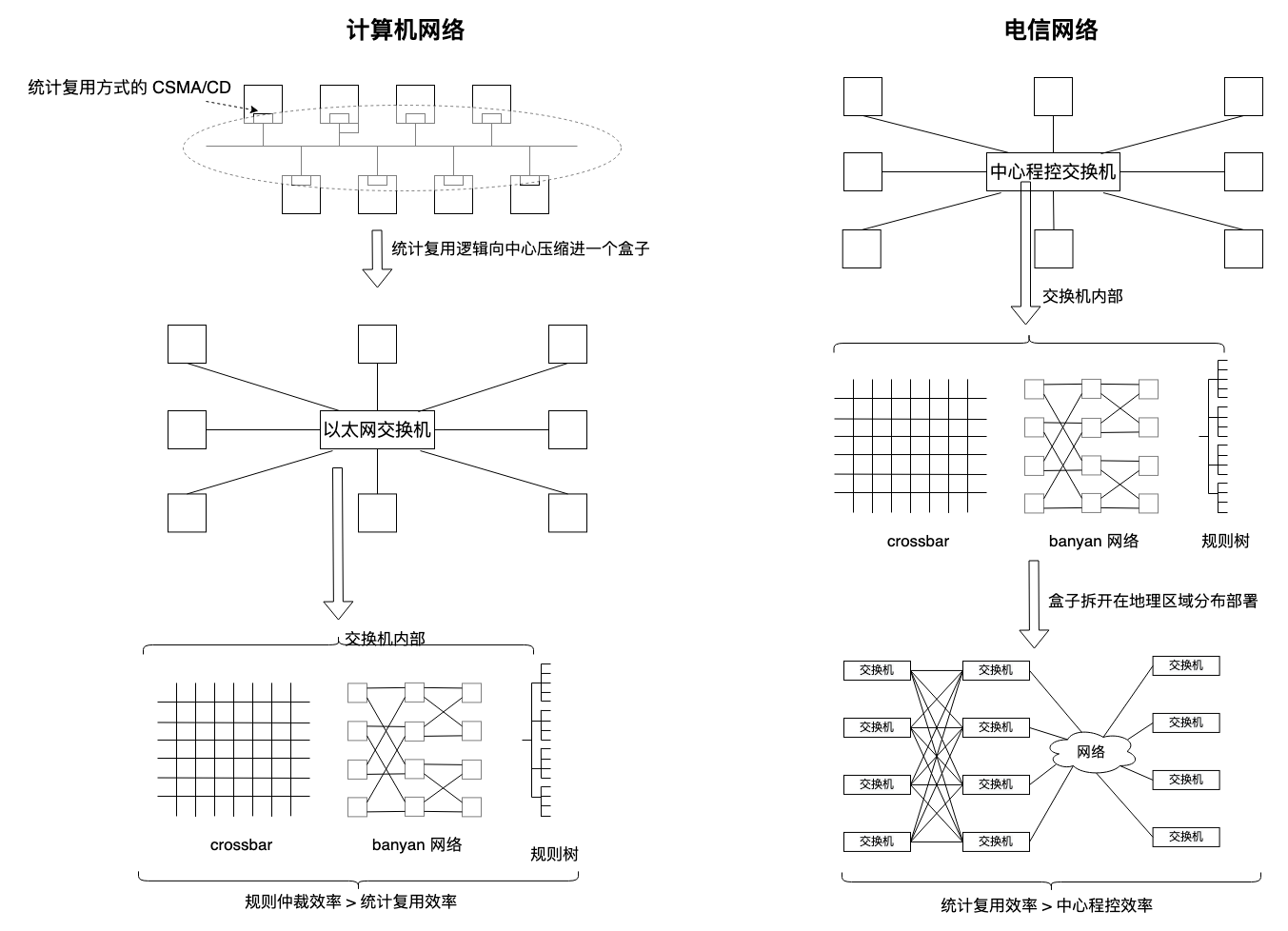
如图,我们对类似 crossbar,banyan tree,b-tree,10-tree,256-tree,甚至 dcn fat-tree 等 “规则拓扑” 网络相当熟悉。规则拓扑网络中,地址信息被编码到拓扑本身,寻址简单直接,像路由表,MMU 页表,也都是规则拓扑结构。
但这种规则拓扑结构只适合中心化控制,比如一个物理盒子里,一个自封闭的系统中。先看 crossbar,它提到它的缺点,可扩展性属其一,它的交叉点是接入节点平方增长的,但一般对一个端口固定的盒子而言,这倒不是问题,再如 banyan 网络就是用阻塞时间换空间,而空间换时间的方案就是规则树了,要么占地方,要么阻塞。
把这些规则结构拆开,每一级结构分离开几十上百公里后,“规则拓扑” 就不再适用,我们可从以太网交换机返祖到 csma/cd 看到这一点。
地理距离意味着控制信号传播时延与数据传输时延处在完全一致的量级上,控制方式必然趋向去中心化,而统计复用几乎是唯一选择。反之,一枚交换芯片不过几厘米,控制系统将在低于数据传输时延至少 3 个数量级完成路由与交换。
在分时系统统计复用的计算机方式和程控中心交换的电信方式融合过程中,中心控制和统计复用之争一直存在,这也是 ATM 出现并失败的理由。
盒子里约束大,拆开盒子把零件散落在外,约束降低,就不能有太多假设,编址寻址从控制拓扑解耦的结果只能是 “逐跳路由”,因为你若想分布式控制下下一跳乃至更远,复杂度将是指数级,由此可见,“best effort” 就是 “逐跳路由” 自然而然的推论。
举个例子,一个公司十个人挤在一间办公室(盒子)工作,彼此靠走动和喊就能协同,瞅一眼就能看出谁在忙而解决同步问题,倘若这十个人分布在全国十个省的分公司,就要更多自我决策而定期同步了,因为出差和电话开销太大,即使当代顶流互联网公司,也要不断面对经理 “我在另一个会上” 这种真实的谎言。
解耦后的网络就是一张拓扑和一套控制该拓扑的算法,便是 “基于图论的网络”,而图论则是一个完整的数学分支,整张网络的行为和特征用它建模。
图论有两大类问题,其一是 “最短路径问题”,考虑 cost,其二是 “最大流最小割问题”。考虑 gain,它们一起构建了高效率的现代数据传输网络的理论基石。
和 E_best = max(gain / cost) 一致,高尚的做法是关注 “最大流 / 最短路径”,而不是其中一个。然而网络性能的研究领域似乎一直要么只关注最短路径,要么只关注最大流。我们的 tcp/ip 路由从一开始就构建在 “最短路径优先” 之上,最多加和权重,而构建在此原则之上的 tcp/ip 协议族显然天生就与 “多路径最大流” 相违背。
先看最短路径,以 Dijkstra 算法为例,它是一个贪心策略,2010 年写过一篇 Dijkstra算法的思想,“一直最努力,结局就不会差”,这就是贪心的动机,如果有一些更加松弛的贪心策略,配合更加松弛的最大流算法,互联网传输效率将彻底改观。在早期那篇文章中,正确性归纳没说清,这里补充:

而最大流的简易理解如下图,来自 Frank R Giordano 的《数学建模》第八章:
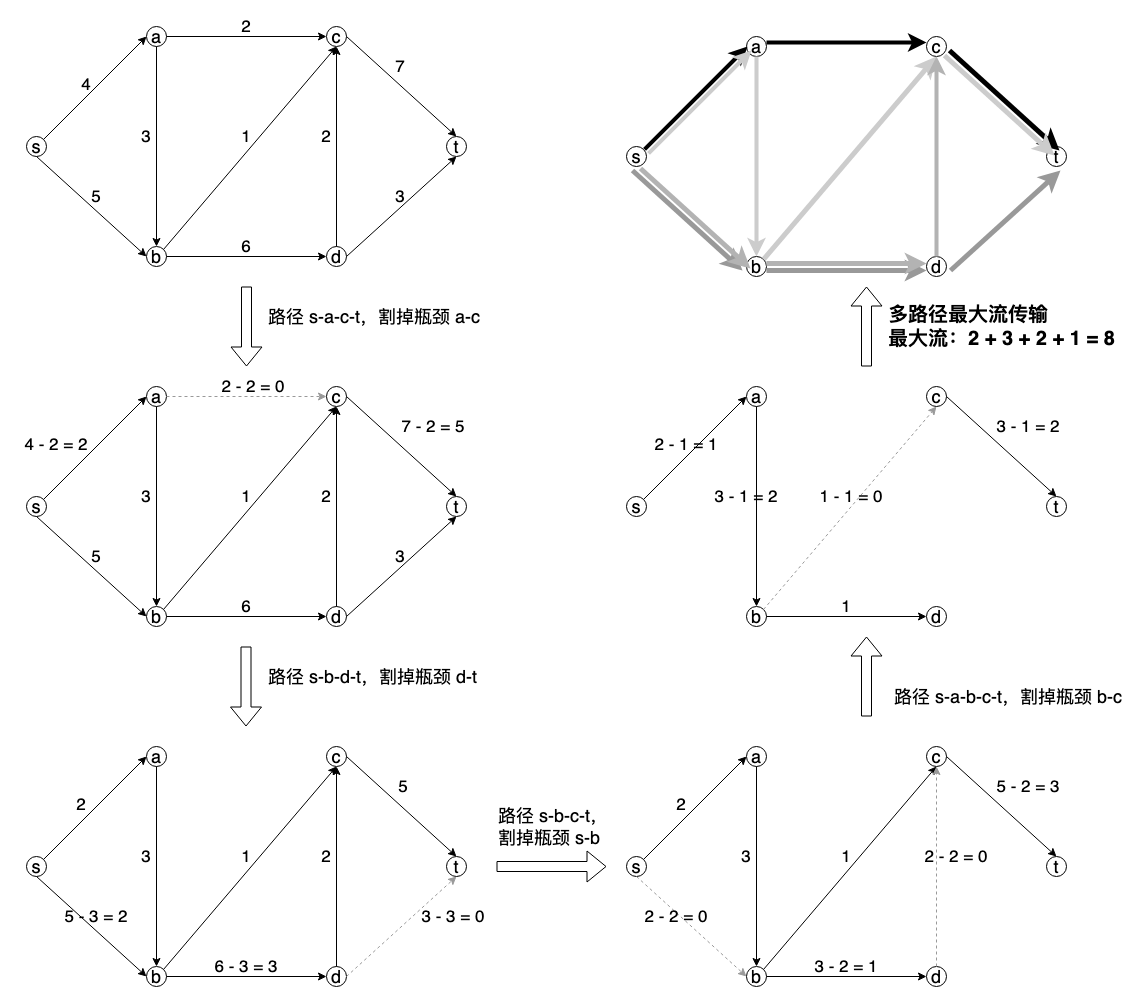
结合最短路径和最大流,每条路径都可以是靠割掉瓶颈后的下一条 Dijkstra 路径,于是就形成了上图的多路径,结合 multipath 协议,就构成了一个高效的传输网络。
在互联网技术演化过程中,最开始基于最短路径构建网络是历史使然。
最短路径适用于单路径简单场景,可让网络设备如路由器快速做出决策,选择最佳路径来转发数据包。这种方法简化了路由表维护,使路由过程更加高效和快速,尤其是在早期网络或大规模网络中,寻找延迟最小,跳数最小的路径有效地降低了传输能耗,数据报文待在网络的每一单位时间都意味着能耗。
最大流算法虽然也是本着高效为出发点,但它是正向反馈,最大流算法不适合直接用于互联网的实时路由选择,特别在早期网络算力不足时,大规模网络实时收敛要消耗大量资源,大大增加路由实现的复杂性,而我们知道,best effort 首要关注廉价的可用性,而不是奢侈的精益求精。
但上面两段的分析对数据中心可是要反过来的。
数据中心善部 sdn,而中心控制的 sdn 配合丰富的算力,小规模且规则拓扑(fat tree,spine-leaf )网络最大流实时收敛可在 ms,甚至 100us 级完成。在数据中心,和广域网常相反,甚至时空因素都相反,此前我说数据中心网络更像主机主板组件的扩展,而不是广域网的微缩,大概就是从规则拓扑和中心控制的角度提出的,
呼应文初的历史观,在规则拓扑,中心控制,百米尺度的共同作用下,最大流路由为主,最短路径为辅助为最大流迭代路径,才能为 multipath 协议铺路背书吧。
ecmp 则永远都在单路径最短路径的阴影下。
浙江温州皮鞋湿,下雨进水不会胖。