秦皇岛做网站seo的北京开发办网站
阻止 NTLM(NT LAN Manager) 攻击设置二
之前郑州景安的服务器被攻击,没过几天阿里云的也被攻击,且都是 NTLM 攻击。
Operating System: Windows Server 2008(R2) Enterprise Service Pack 1 64bit
一、win+r 输入 gpedit.msc
二、依次进入:本地组策略编辑器 - 计算机配置 - Windows 设置 - 安全设置 - 本地策略 - 安全选项。
三、进入【安全选项】,进行如下两项设置:
1. 网络安全:LAN 管理器身份验证级别 - 禁发送 NTLMv2 响应。拒绝 LM;
2. 网络安全:限制 NTLM:传入 NTLM 流量 - 拒绝所有帐户。
以上设置参考:服务器日志出现大量NTLM(NT LAN Manager)攻击_子蛟的博客-CSDN博客
警告,如果未进行如下设置,设置【网络安全:限制 NTLM:传入 NTLM 流量 - 拒绝所有帐户】后,有可能无法登录远程桌面:
一、依次进入:本地组策略编辑器 - 计算机配置 - Windows 设置 - 管理模板 - Windows 组件 - 远程桌面服务 - 远程桌面会话主机 - 安全 - 远程(RDP)连接要求使用指定的安全层 - 已启用。
二、win+r 进入控制台,输入 gpupdate 如下图:
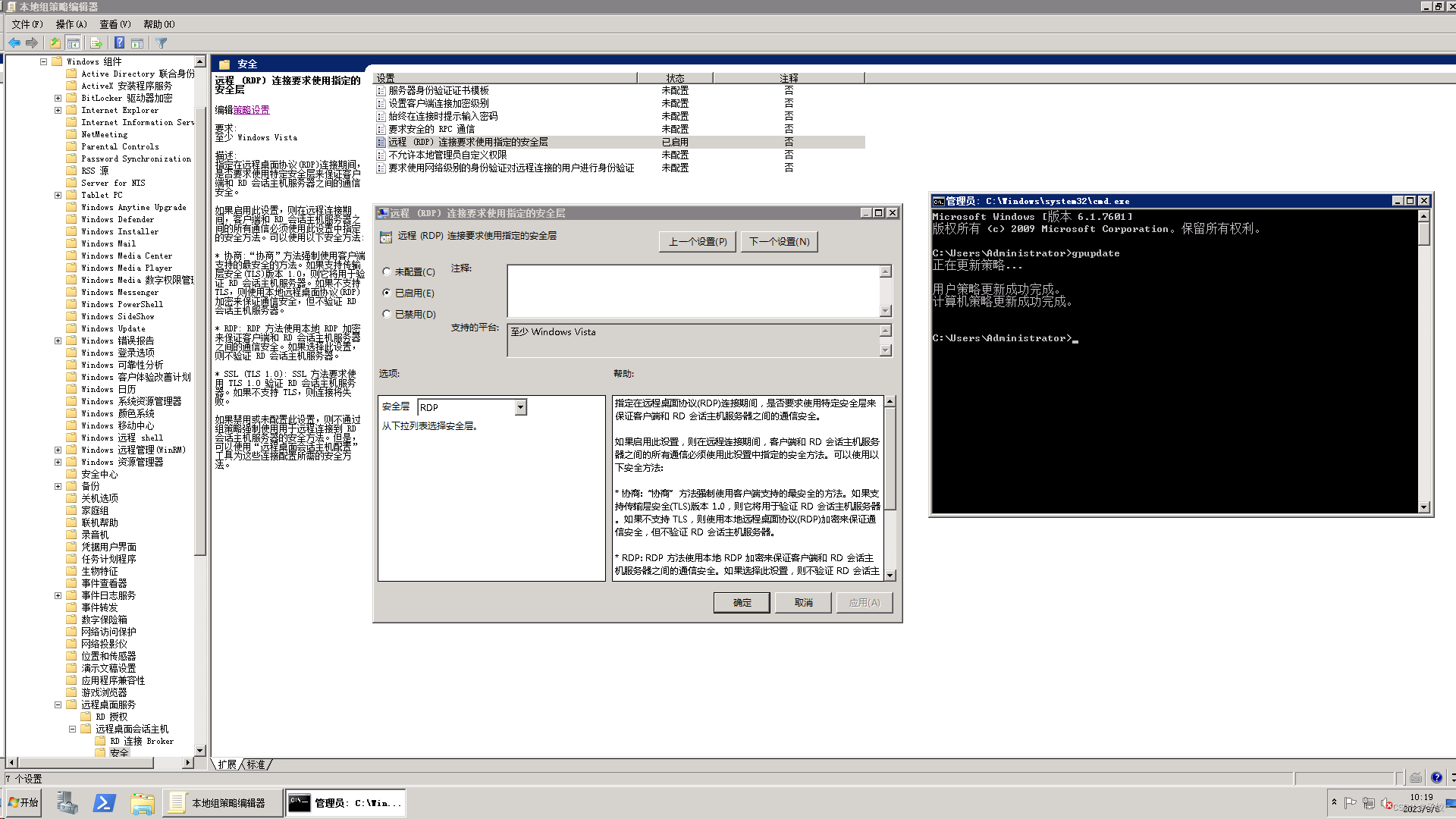
经过以上设置,即可阻止NTLM攻击,又不影响远程登录。