网站建设丶金手指花总11外贸平台是什么
目录
一、字母图形
二、完美的代价
三、01字串
四、序列求和
一、字母图形
问题描述
利用字母可以组成一些美丽的图形,下面给出了一个例子:
ABCDEFG
BABCDEF
CBABCDE
DCBABCD
EDCBABC
这是一个5行7列的图形,请找出这个图形的规律,并输出一个n行m列的图形。
输入格式
输入一行,包含两个整数n和m,分别表示你要输出的图形的行数的列数。
输出格式
输出n行,每个m个字符,为你的图形。
样例输入
5 7
样例输出
ABCDEFG
BABCDEF
CBABCDE
DCBABCD
EDCBABC数据规模与约定
1 <= n, m <= 26。
思路:
- 观察样例输出,可得(0,0)、(1,1)...(n,n)这一对角线上的字母都是A。
- 然后,对于对角线左侧的位置(i, j),其中i > j,字母是向后偏移的,偏移量为i - j;
- 而对于对角线右侧的位置(i, j),其中i < j,字母是向前偏移的,偏移量为j - i。
- 我们可以对偏移量进行模26运算来得到正确的字母。
代码实现如下:
#include<bits/stdc++.h>
using namespace std;
int main()
{int n, m; cin >> n >> m; vector<vector<char> >a(n, vector<char>(m));for (int j = 0; j < m; j++){a[0][j] = 65 + j;cout << a[0][j];}cout << '\n';for (int i = 1; i < n; i++){for (int j = 0; j < m; j++){if (i > j){a[i][j] = a[0][0] + i - j;}else {a[i][j] = a[0][0] + j - i;}cout << a[i][j];}cout << '\n';}
}二、完美的代价
问题描述
回文串,是一种特殊的字符串,它从左往右读和从右往左读是一样的。小龙龙认为回文串才是完美的。现在给你一个串,它不一定是回文的,请你计算最少的交换次数使得该串变成一个完美的回文串。
交换的定义是:交换两个相邻的字符
例如mamad
第一次交换 ad : mamda
第二次交换 md : madma
第三次交换 ma : madam (回文!完美!)输入格式
第一行是一个整数N,表示接下来的字符串的长度(N <= 8000)
第二行是一个字符串,长度为N.只包含小写字母输出格式
如果可能,输出最少的交换次数。
否则输出Impossible样例输入
5
mamad样例输出
3
思路:
双指针类题。
开始准备:
- 回文字符串,使字符串满足两端中心对称,设置一个头指针和尾指针。头指针指向第一个字母,下标为0;尾指针指向最后一个字母,下标为n - 1;并再使用一个指针记录尾指针开始遍历的位置。
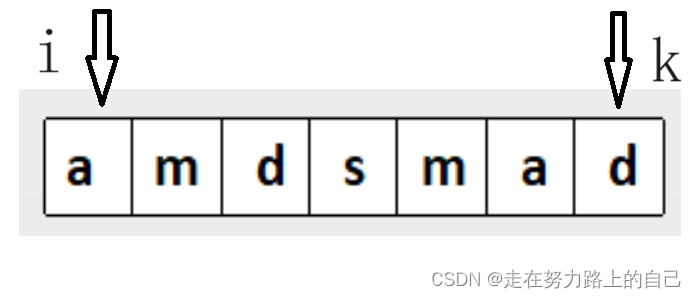
char a[8001];bool flag = false;
int n, sum=0, i, t,mk; // k是记录指针
cin >> n;getchar(); // 取消换行符
cin >> a; // 读取字符串到数组a中t = n - 1; // 设置t为字符串的最后一个字符的索引
循环过程:
- 我们使用双指针的方法来遍历字符串。外层循环从头指针i开始,遍历到倒数第二个字符。内层循环从尾指针k开始,从字符串末尾向前遍历,寻找与头指针i处的字符相等的字符。
- 将尾指针往后的节点全部都向前移动,记录指针处的节点赋值为头指针处的值,这样就保证了中心对称
// 外层循环遍历字符串的每个字符,直到倒数第二个字符
for(i=0; i<t; ++i)
{
// 内层循环从字符串末尾向前遍历,寻找与a[i]相等的字符
for (k = t; k >= i; --k)
{......
}
}
- 在内层循环中,我们首先检查头指针和尾指针是否相遇。
- 如果相遇了,说明字符串遍历完毕。
找到相同字母:
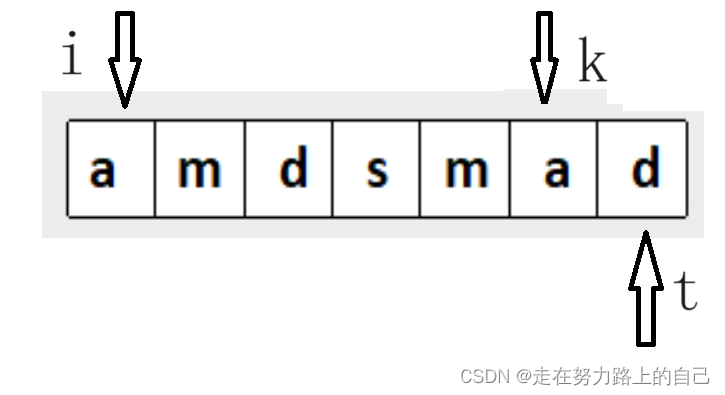
- 如果找到了与头指针i处字符相等的字符,我们将匹配字符后面的所有字符都向前移动一位,并累计移动次数。
- 然后,我们更新字符串的末尾索引t,并将匹配的字符移动到其正确的位置(即末尾)。
- 记录指针--,头指针++
- 最后,我们跳出内层循环,继续外层循环的下一个迭代。

// 如果找到了与a[i]相匹配的字符
if (a[i] == a[k])
{
// 将匹配字符后面的所有字符都向前移动一位,累计移动次数
for (m = k; m < t; ++m)
{
a[m] = a[m + 1];
sum++;
}
// 更新字符串的末尾索引t,并将匹配的字符移动到其正确的位置
a[t] = a[i];
--t;
break;
}
结束条件(一、无法形成回文):
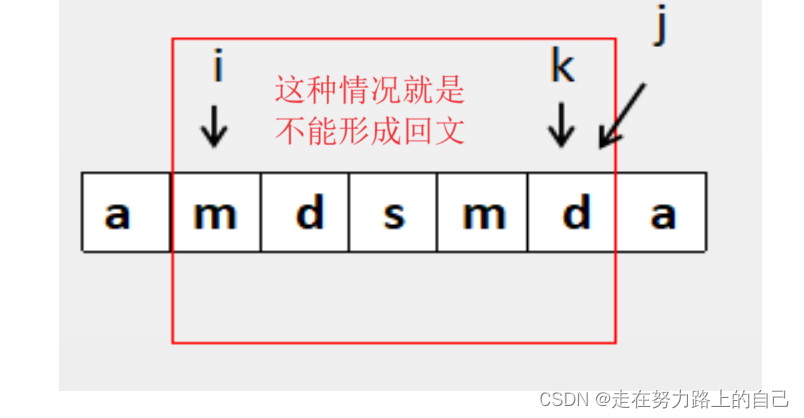
- 此时,我们检查字符串的长度是否为偶数,或者是否已经处理过一个单独的字符(由变量flag记录)。
- 如果满足这两个条件之一,说明无法将字符串转变为回文字符串,我们输出"Impossible"并结束程序。
// 如果i和k相遇,说明中间的字符没有匹配的字符
if (i == k)
{
// 如果字符串长度为偶数,或者flag已经被设置为true
//(即已经处理过一个单独的字符),则输出Impossible
if (n % 2 == 0 || flag)
{
printf("Impossible");
return 0;
}
......}
结束条件(二、打印次数):
- 如果字符串长度为奇数,并且这是第一次遇到单独的字符,我们计算移动次数(即将剩余的字符移动到字符串末尾的次数),并将flag设置为true。

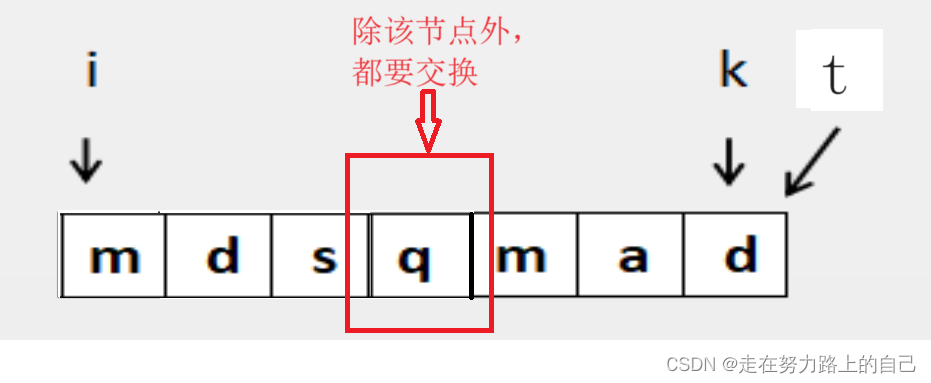
sum += n / 2 - i;
flag = true;
break;
- 最终,当外层循环结束时,我们输出累计的移动次数sum作为结果。
#include<bits/stdc++.h>
using namespace std;int main(void)
{char a[8001];bool flag = false; int n, sum=0, i, t, k, m; cin >> n;getchar(); // 取消换行符cin >> a; // 读取字符串到数组a中t = n - 1; // 设置t为字符串的最后一个字符的索引// 外层循环遍历字符串的每个字符,直到倒数第二个字符for(i=0; i<t; ++i){// 内层循环从字符串末尾向前遍历,寻找与a[i]相等的字符for (k = t; k >= i; --k){// 如果i和k相遇,说明中间的字符没有匹配的字符if (i == k){// 如果字符串长度为偶数,或者flag已经被设置为true//(即已经处理过一个单独的字符),则输出Impossibleif (n % 2 == 0 || flag){printf("Impossible");return 0;}// 如果字符串长度为奇数,并且这是第一次遇到单独的字符,// 则计算移动次数,设置flag为truesum += n / 2 - i;flag = true;break;}// 如果找到了与a[i]相匹配的字符if (a[i] == a[k]){// 将匹配字符后面的所有字符都向前移动一位,累计移动次数for (m = k; m < t; ++m){a[m] = a[m + 1];sum++;}// 更新字符串的末尾索引t,并将匹配的字符移动到其正确的位置a[t] = a[i];--t;break;}}}// 输出最少的移动次数cout <<sum;return 0;
}
三、01字串
问题描述
对于长度为5位的一个01串,每一位都可能是0或1,一共有32种可能。它们的前几个是:
00000
00001
00010
00011
00100
请按从小到大的顺序输出这32种01串。
x >> i & 1;
// 结果必然为0或1, 表示 x 的二进制表示中的第i位获取二进制数的某一位的应用:
#include<bits/stdc++.h>
using namespace std;
int main()
{for (int n = 0; n < 32; n++){for (int i = 4; i >= 0; i--){if (n >> i & 1)cout << 1;else cout << 0;}cout << '\n';}return 0;
}四、序列求和
问题描述
求1+2+3+...+n的值。
输入格式
输入包括一个整数n。
输出格式
输出一行,包括一个整数,表示1+2+3+...+n的值。
样例输入
4
样例输出
10
样例输入
100
#include <bits/stdc++.h>
using namespace std;int main() {long long n; // 定义一个长整型变量n来存储用户输入scanf("%I64d", &n); // 使用scanf函数读取用户输入的长整型数值,并存储在n中long long sum = 0; // 定义一个长整型变量sum来累计从1到n的和,初始化为0for (long long i = 1; i <= n; i++) // 从1遍历到n{sum += i; // 将当前的i加到sum上,累计求和}printf("%I64d", sum); // 使用printf函数输出求得的和sumreturn 0; // 程序正常结束,返回0
}
今天就先到这了!!!

看到这里了还不给博主扣个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
你们的点赞就是博主更新最大的动力!
有问题可以评论或者私信呢秒回哦。