专业网站制作推广服务做网站要交百分七十定金
Oracle实现高可用性的工具(负载均衡/故障切换)
- 1 Oracle RAC
- 故障转移
- 负载均衡
- 2 Data Guard
- 负载均衡-读写分离
- Data Guard Broker
- 3 GDS
- GSM:
| 连接管理工具 | 主要功能 |
|---|---|
| Data Guard Broker | 功能是监控Data Guard状态,当主库异常时自动切换角色 |
| GSM 全局服务管理器 | GSM 就是―全球监听器,它了解实时负载特征和复制数据库上的用户定义的服务布置策略。这些 GSM 有助于执行 GDS 的数据库间服务故障切换和负载平衡。 |
| Oracle Net Services | Oracle Net Services 为数据库连接提供了连接负载均衡。 |
| 负载均衡顾问程序 | Oracle 真正应用集群提供了一个负载均衡顾问程序。RAC 按每个提供服务的实例持续监视针对每个服务执行的负载。 |
| Oracle Clusterware | CRS主要完成集群成员管理、心跳监控、故障切换等功能。Oracle Clusterware 用于监管 Oracle Real Application Cluster 数据库。 |
| VIP | 1. VIP是在clusterware安装最后阶段,通过脚本VIPCA创建的;2. VIP作为一个Nodeapps类型的CRS Resource注册到OCR中,并由CRS维护状态;3. VIP会绑定到节点的public 网卡上;那么public网卡就有两个地址了;4. 当某个节点发生故障时,CRS会把故障节点的VIP转移到其他节点上;5. 每个节点的Listener会同时在public网卡的public IP和VIP两个地址上监听;6. 客户端的tnsname.ora一般会配置指向节点的VIP; |
| SCAN IP | scan,single client access name。简单客户端连接名,这是一个唯一的名称,在整个公司网络内部唯一,并且在DNS中可以解析为三个ip地址,客户端连接的时候只需要知道这个名称,并连接即可, 每个SCAN VIP对应一个scan listener,cluster内部的service在每个scan listener上都有注册,scan listener接受客户端的请求,并foward到不同的Local listener中去,还是由local 的listener提供服务给客户端。client -> scan listener -> locallistener -> local instance |
| TAF | 透明应用程序故障转移 |
| 深信服AD应用交付平台(第三方工具) | 作为应用服务器和oracle数据库之间的媒介,提供了负载均衡和健康监控的服务。借助AD可实现集中的健康监控,而不需要每台应用服务器都监控数据库服务器,从而卸载了应用服务器的负载,释放宝贵的计算资源。 |
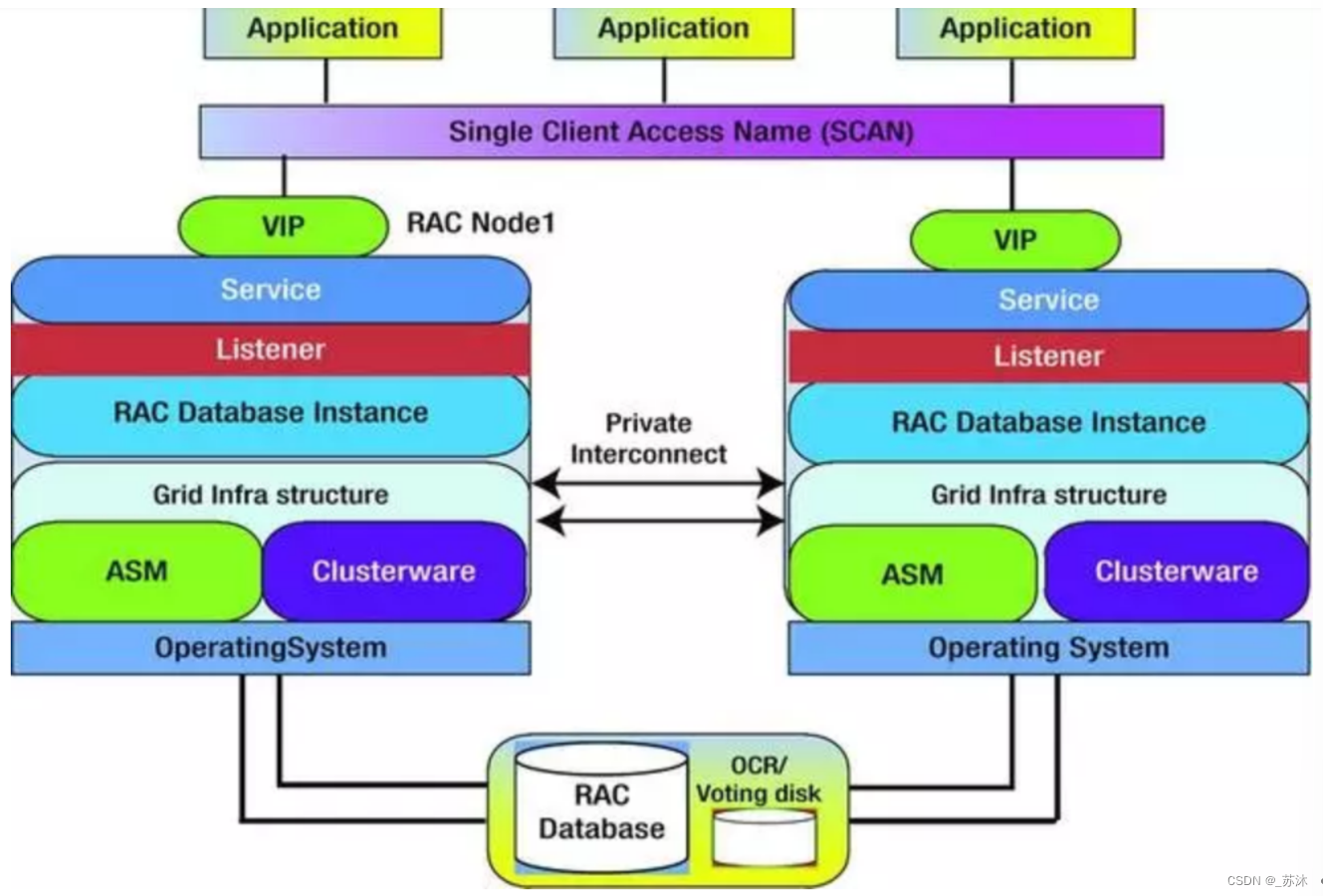
1 Oracle RAC
多个Oracle服务器组成一个共享的Cache,而这些Oracle服务器共享一个基于网络的存储。
故障转移
Oracle Net中实际应用了两种连接故障转移功能。
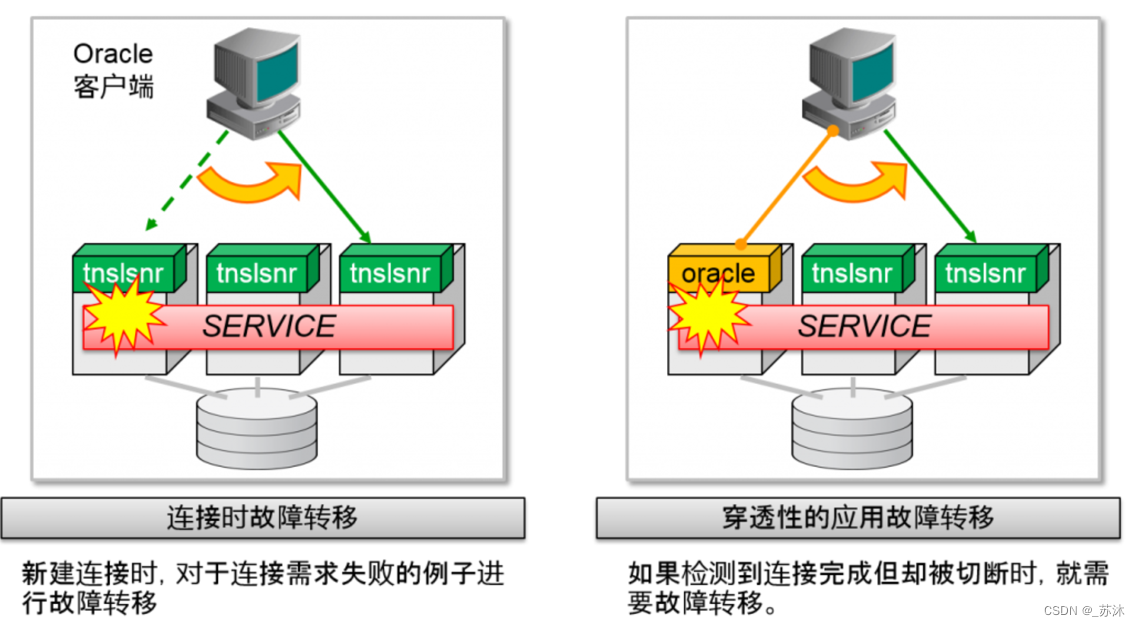
连接时的故障转移Connect-Time Failover (CTF)
新建连接时,对于连接需求失败的例子进行故障转移;考虑到高可用性时,需要实际安装的功能
穿透性的应用故障转移Transparent Application Failover (TAF)
Oracle Call Interface(OCI) 客户端的功能;对于建立完成的连接中检测到切断时进行故障转移;并不是重新执行一次更新事务,对应用透明
负载均衡
客户端连接负载均衡
Oracle客户端的连接描述符中,会记录发出连接需求的Oracle listener的网络地址。其中可以记录多个Oracle listener的网络地址。客户端连接负载均衡对于这些Oracle listener的候补会分散发出连接需求的地址。
服务器连接负载均衡
Oracle listener中会记录构成RAC的oracle实例服务结构。记录的不止是服务的设定,还记录了负荷信息,并且会自动更新。Oracle listener如果接受Oracle客户端的连接需求的话,请对那个服务进行测试,判断是否需要分散负荷,重新定位到适合的节点中。因此,即使制成了客户端连接负荷均衡,实际上决定连接地址的还是服务器连接负载均衡。
RAC的故障转移与负载均衡(SCAN)
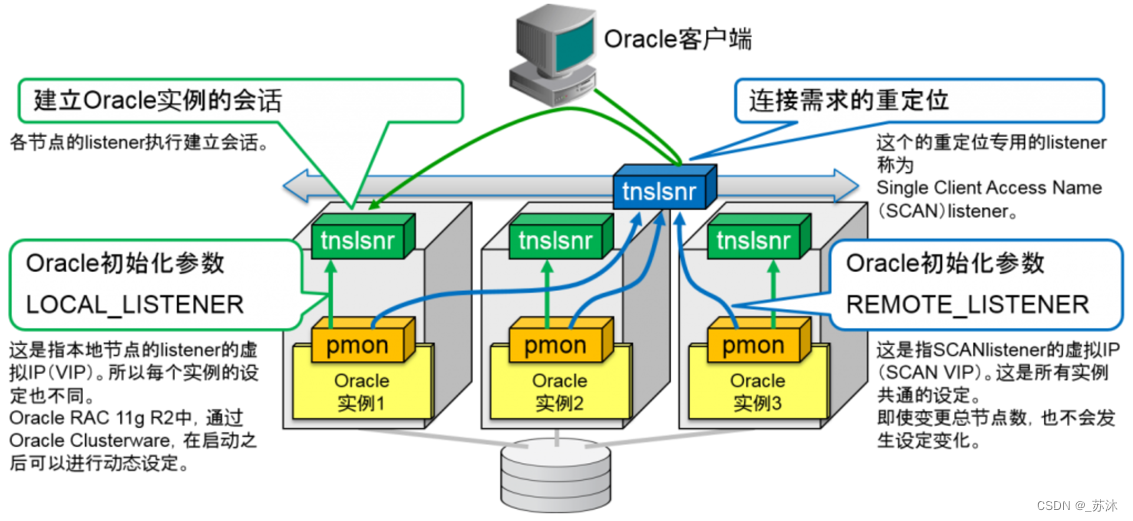
SCAN listener以及SCAN虚拟IP地址(SCAN VIP)同时启动
SCAN listener的运行节点中发生故障的话,就会在其他节点中通过SCAN VIP以及set来重启
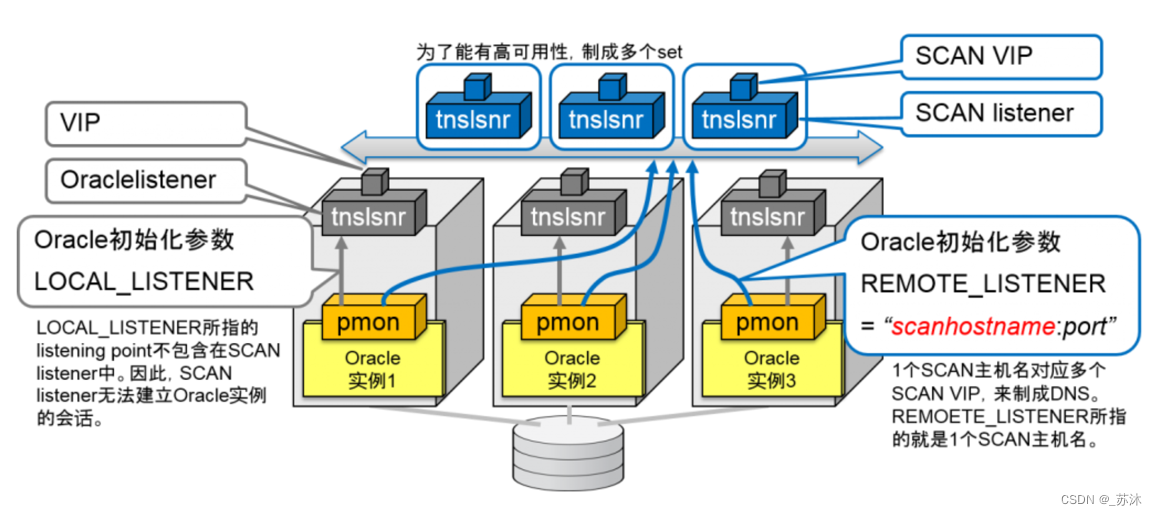
通过DNS使得1个SCAN主机名对应多个SCAN VIP
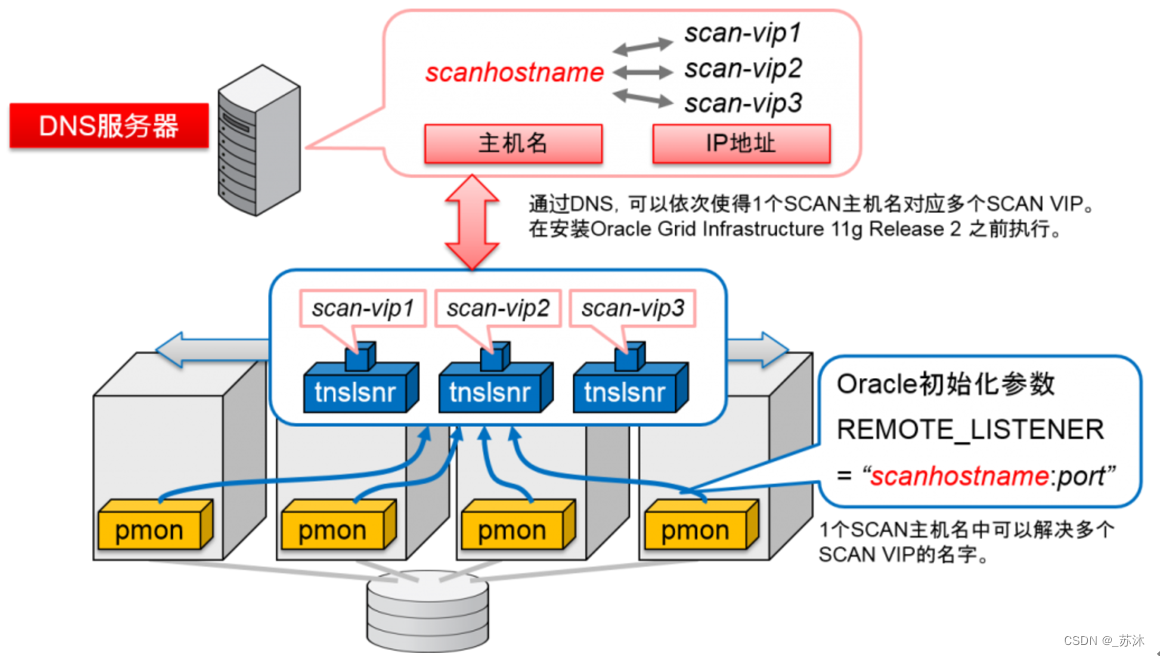
客户端负载平衡将在集群内的全部 SCAN 监听器中平衡连接请求,方法是在客户端连接字符串的地址列表上使用 SCAN。 SQL*NET 将随机选择其中一个 SCAN ip 地址。如果选中的服务器不可用,则将尝试列表中的下一台服务器。使用DNS解析SCAN的时候,DNS服务器会采用rr(round-robin)的方式循环解析为它准备的3个IP地址,与Oracle 11g R2的客户端配合使不同的客户端能够连接到不同的SCAN Listener上,这相当于是Oracle 10g中配置的客户端负载均衡使用SCAN连接数据库实例,整个过程实现了客户端的Failover(Oracle 10g R2是通过FAILOVER=on来配置),DNS服务器返回的是一个SCAN VIP列表,客户端会选择其中一个连接到RAC,如果这个IP地址不能正常访问,客户端会选择另一个IP地址继续连接,直到所有的地址都不能正常连接,才返回错误给客户端,整个过程对客户端程序来说依然是透明的。
服务器端负载平衡是通过 SCAN 监听器实现的。每个 SCAN 监听器都能感知到提供每项服务的集群中的所有实例。基于为服务定义的目标,监听器会选择最符合目标的实例,然后通过本地监听器连接到该实例。Oracle RAC服务器端的负载均衡是根据RAC中各节点的连接负荷数情况,将新的连接请求分配到负荷最小的节点上去。当数据库处于运行时,RAC中各节点的PMON进程每3秒会将各自节点的连接负荷数更新到service_register。而对于节点中任意监听器故障或监听器意外失败时,PMON进程会每1秒钟检查当前节点上的监听是否重启,以获得最新的负载信息来及时调整负载均衡。
2 Data Guard
Data Guard这个方案就适合多机房的。某机房一个production的数据库,另外其他机房部署standby的数据库。Standby数据库分物理的和逻辑的。物理的standby数据库主要用于production失败后做切换。而逻辑的standby数据库则在平时可以分担production数据库的读负载。
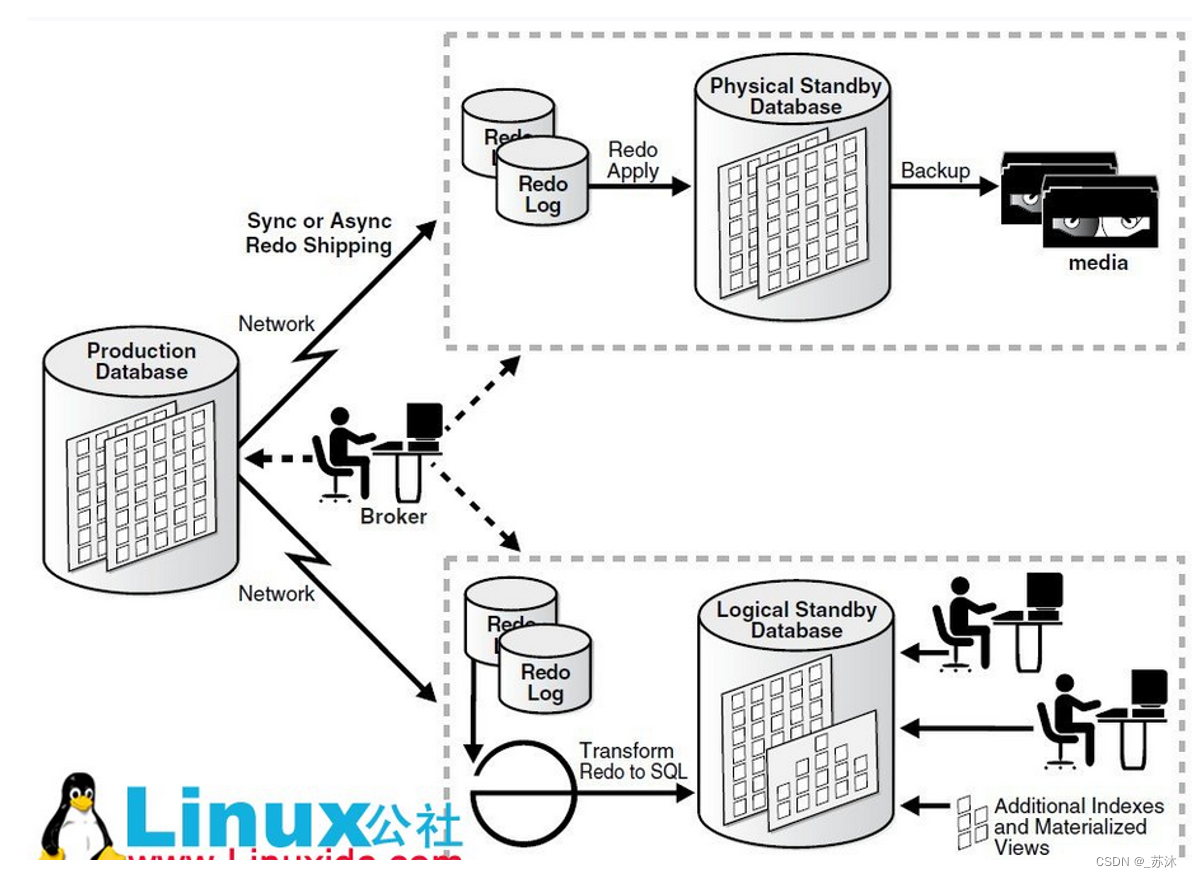
负载均衡-读写分离
某机房一个production的数据库,另外其他机房部署standby的数据库。Standby数据库分物理的和逻辑的。物理的standby数据库主要用production失败后做切换。而逻辑的standby数据库则在平时可以分担production数据库的读负载。
Data Guard Broker
Data Guard 自带的工具,它不但自动进行 Data Guard 配置的创建、维护和监视,还对这些操作进行统一管理。数据库管理员 (DBA) 可通过 Broker 的命令行界面或 Oracle Enterprise Manager Cloud Control 与 Broker 进行交互。由 Data Guard Broker 管理的角色转换能够自动将一个备用数据库转换为主数据库角色,启动适合主数据库角色的数据库服务,通知应用程序客户端与出现故障的主数据库断开连接(结束它们的 TCP 超时状态),并引导其连接到新的主数据库,上述操作全部无需人工干预。对于使用全局负载平衡器和 DNS 故障切换来将用户连接重定向到新中间层的场合,也可以使用 Data Guard 角色更改事件来实现该场合的自动化处理。并且使用Oracle Net Services自动在Data Guard配置中的数据库之间进行通信。
3 GDS
GDS将智能负载平衡和客户端故障切换的概念扩展至全局分布式环境,在该环境中有两个或更多的可用于保持可用性的故障切换目标。
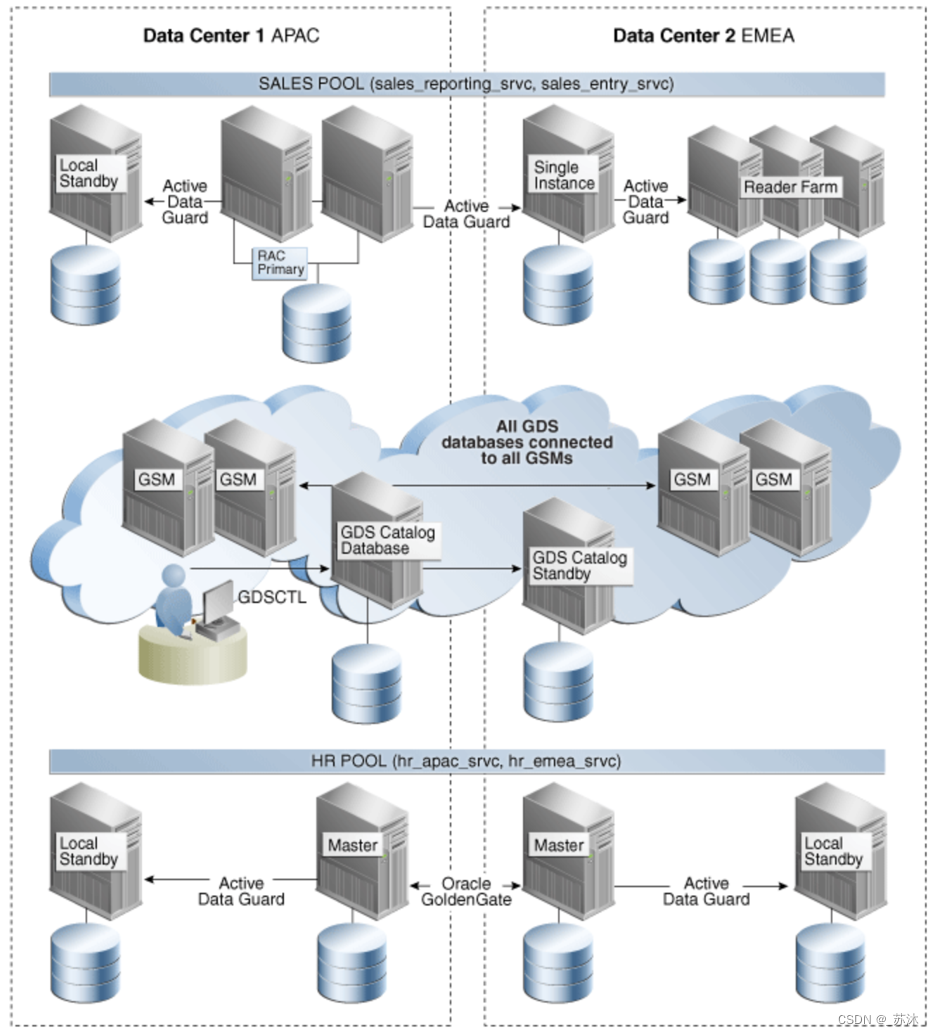
GSM:
GSM 就是―全球监听器,它了解实时负载特征和复制数据库上的用户定义的服务布置策略。这些 GSM 有助于执行 GDS 的数据库间服务故障切换和负载平衡。
gsm的职责如下:
- 提供客户端连接时的负载均衡
- 提供service级别的负载均衡,故障转移
- 创建 run time LBA(load balancing advisory),并分发到所有的客户端
- 监控数据库实例的可用性和全局服务的可用性,并在失败的时候通知客户端
- 作为区域的监听,用户客户端连接global service