重庆网站建设尚智逢源设计公司网站需要考虑什么
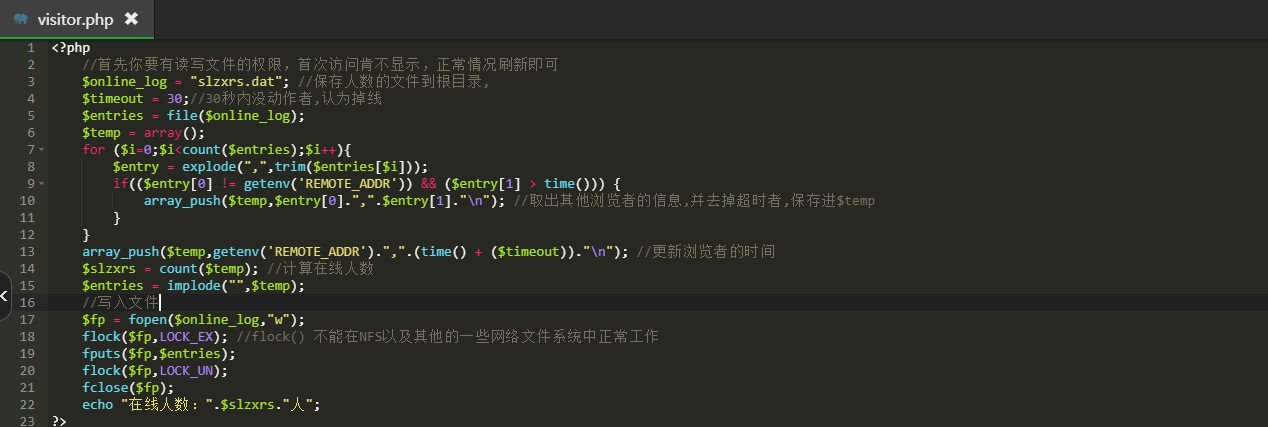
第一步:在模板文件里面创建“visitor.php”的文件吧下面代码入进去
code
- <?php
- //首先你要有读写文件的权限,首次访问肯不显示,正常情况刷新即可
- $online_log = "slzxrs.dat"; //保存人数的文件到根目录,
- $timeout = 30;//30秒内没动作者,认为掉线
- $entries = file($online_log);
- $temp = array();
- for ($i=0;$i<count($entries);$i++){
- $entry = explode(",",trim($entries[$i]));
- if(($entry[0] != getenv('REMOTE_ADDR')) && ($entry[1] > time())) {
- array_push($temp,$entry[0].",".$entry[1]."\n"); //取出其他浏览者的信息,并去掉超时者,保存进$temp
- }
- }
- array_push($temp,getenv('REMOTE_ADDR').",".(time() + ($timeout))."\n"); //更新浏览者的时间
- $slzxrs = count($temp); //计算在线人数
- $entries = implode("",$temp);
- //写入文件
- $fp = fopen($online_log,"w");
- flock($fp,LOCK_EX); //flock() 不能在NFS以及其他的一些网络文件系统中正常工作
- fputs($fp,$entries);
- flock($fp,LOCK_UN);
- fclose($fp);
- echo "在线人数:".$slzxrs."人";
- ?>
第二步:在网站根目录创建一个名为"slzxrs.dat"的文件,这个是存储当前在线人数的ip
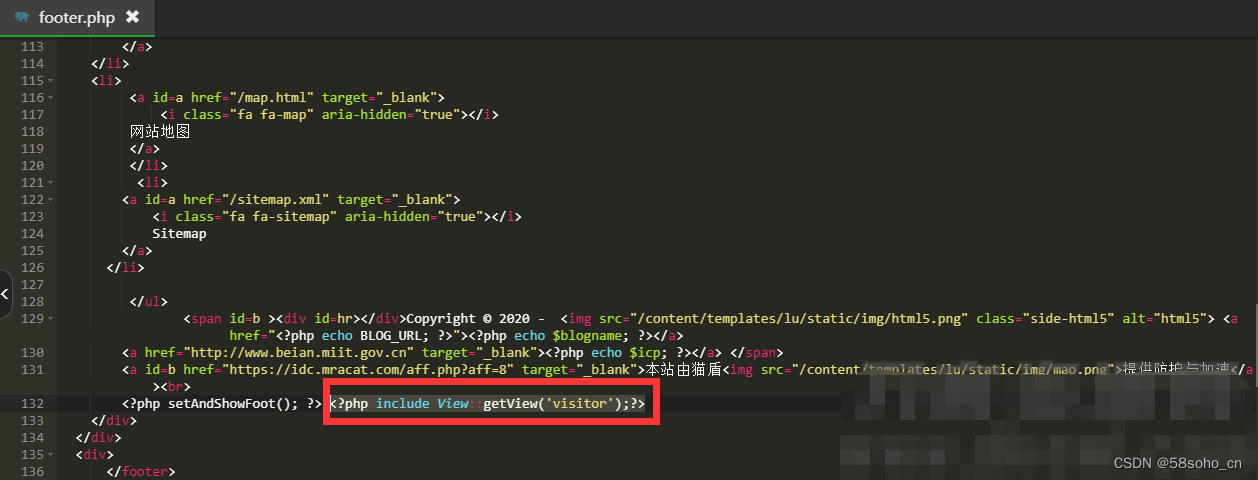
第三步:在当前模板"footer.php"文件中添加调用代码
code
- <?php include View::getView('visitor');?>