网站后期维护很难吗商标注册网上查询
一、故障现象
一辆2017款东风本田XR-V车,搭载R18ZA发动机,累计行驶里程约为4万km。车主反映,车辆行驶或静止时,向右侧转向比向左侧转向沉重。
二、故障诊断
接车后试车,起动发动机,组合仪表上无故障灯点亮;原地左右来回转动转向盘,确实向左侧转向时较轻,向右侧转向时较沉;进行路试,也是如此,但车辆无跑偏现象。询问车辆的使用状况,得知车32辆左前侧被碰撞过,当时更换了支臂、减振器、转向管柱总成等配件,但事故维修后转向助力左右不一致的故障就一直存在。
该车采用电动助力转向系统(EPS),驾驶人的转向力受到转向柱上EPS电动机的辅助。如图1所示,EPS电动机、EPS控制单元及转矩传感器均安装在转向柱上。

低速时,EPS提供较大的转向助力,易于操控;随着车速的提高,EPS提供的转向助力逐渐减小,驾驶人需要提供的转向力逐渐增大,这样驾驶人就能感受到明显的“路感”,提高了车辆稳定性。
用故障检测仪检测,EPS控制单元中无故障代码存储。接通点火开关,不起动发动机,原地左右转动转向盘,此时EPS不工作,左右转向轻重相同;举升车辆,使车轮离地,左右转动转向盘,左右转向轻重也相同。
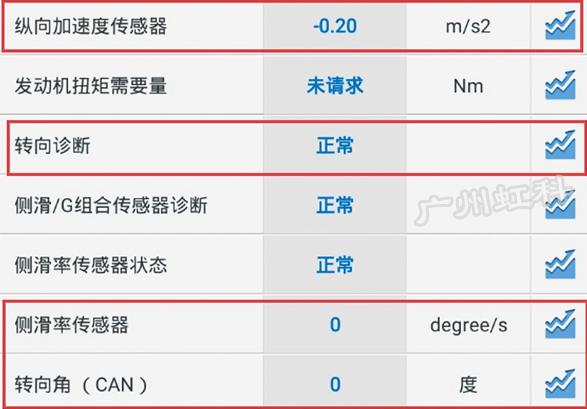
由此可知,故障是在EPS介入工作后才出现的。EPS通过车速、转向转矩、转向盘角度及防侧滑数据等信号进行转向助力大小的控制。起动发动机,读取ABS数据流(图2),转向角为0°,转向诊断为正常,侧滑率传感器为0°,纵向加速度传感器为-0.2m/s2,正常。
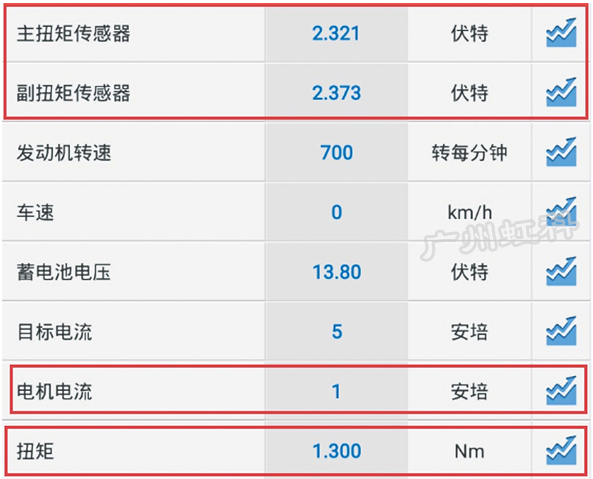
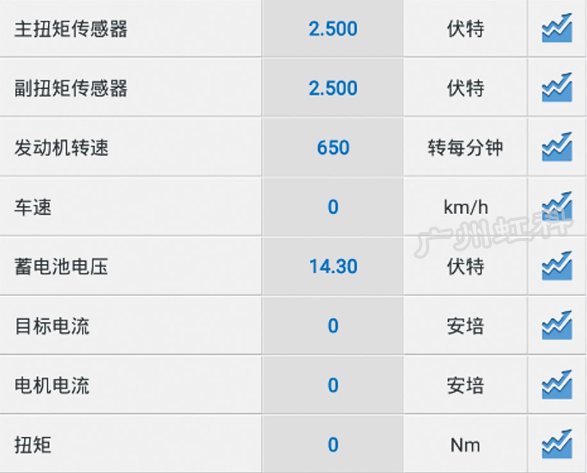
读取EPS数据流(图3),EPS电动机电流为1A,转向转矩为1.3N·m,主转矩传感器信号电压为2.321V,副转矩传感器信号电压为2.373V;左右转动转向盘,EPS电动机电流和转向转矩均会随之变化;轻微向右转动转向盘,转向转矩变为0N·m,EPS电动机电流也随之降为0A;松开转向盘,EPS数据流随之恢复至图3所示的情况。
转矩传感器采用霍尔芯片测量施加到转向柱轴的力与路面摩擦产生车轮转动阻力之间的差异,并将其转换成电压信号发送给EPS控制单元,EPS控制单元根据此信号控制EPS电动机的电流。如图4所示,转矩传感器由中间轴、输入轴、下轴、扭杆、磁轭及多极磁铁等部件组成。

转向盘的输入传输至中间轴,中间轴和下轴由扭杆连接,多极磁铁连接到中间轴,磁轭连接到下轴;当路面阻力大且下轴转动困难时,中间轴和下轴以不同的方式旋转,导致扭杆扭曲,同时多极磁铁和磁轭也发生相对旋转,通过霍尔芯片的磁通量发生变化,以此检测转矩变化;扭杆扭曲程度越大,对应的转矩越大。
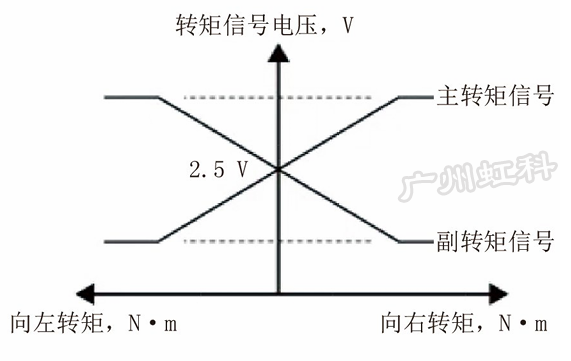
转矩传感器的输出特性曲线如图5所示,静止时,主、副转矩信号电压均为2.5V;向右施加转向力矩时,主转矩信号电压升高至2.5V以上,副转矩信号电压降低至2.5V以下;向左施加转向力矩时,主转矩信号电压降低至2.5V以下,副转矩信号电压升高至2.5V以上。
结合转矩传感器工作原理及EPS数据流进行分析,推断主、副转矩信号电压异常,导致辅助转矩异常。如图6所示,转矩传感器上的4根导线直接连接至EPS控制单元,其中端子A4为5V供电端子,端子A2为搭铁端子,端子A1为主转矩信号端子和A3为副转矩信号端子。

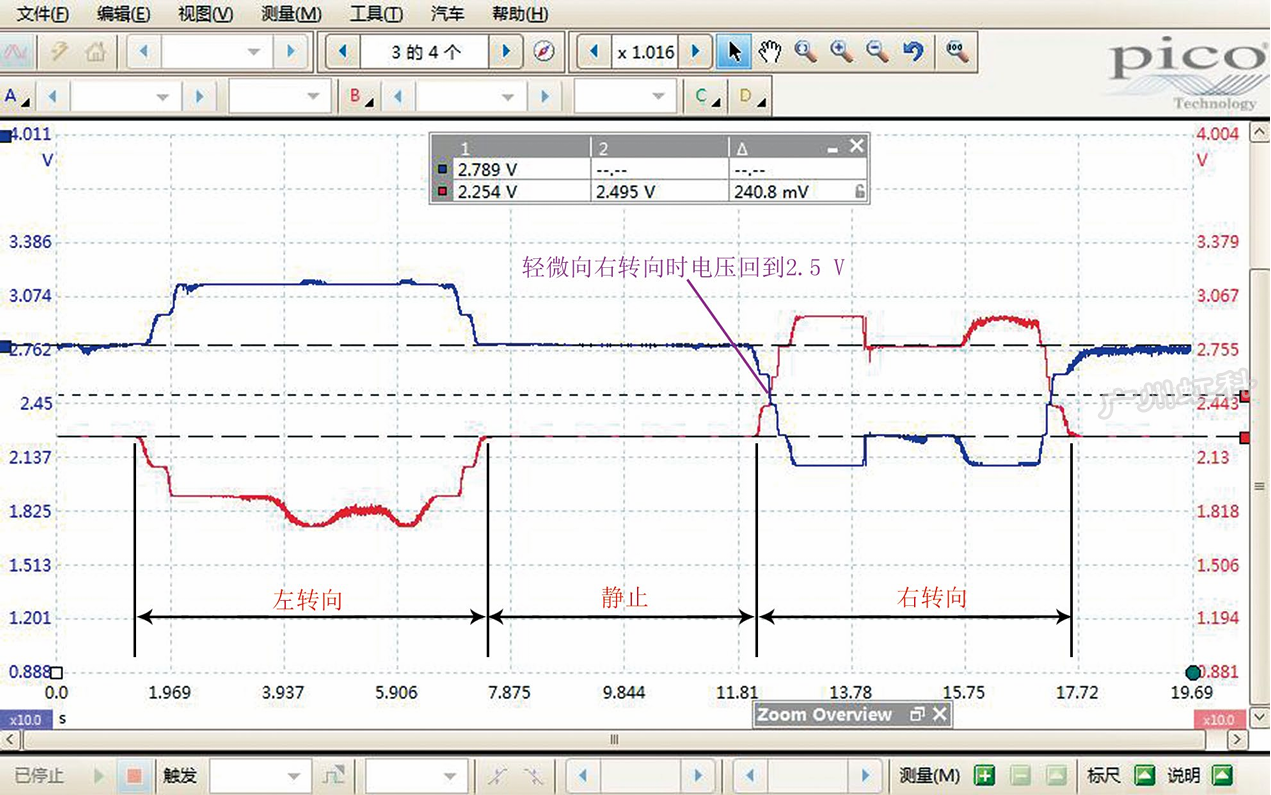
用pico示波器同时测量主、副转矩信号电压(图7),发现向左或向右施加转矩时,主、副转矩信号电压均会发生变化,但静止时,主转矩信号电压约为2.25V,副转矩信号电压约为2.79V,像是一直向左施加了转矩一样,异常(正常应均约为2.5V)。诊断至此,推断转矩传感器损坏。
从转向轴上拆下转矩传感器的霍尔芯片,使其脱离磁场,发现主、副转矩信号电压均恢复至2.5V,说明霍尔芯片正常,推断转向轴内部磁芯故障。拆解转向轴,发现转向轴的磁芯发生相对移动(图8)。

三、故障排除
更换转向管柱总成(包括转向轴、EPS控制单元、EPS电动机及转矩传感器等)后试车,EPS数据流恢复正常(图9),转向助力也恢复正常,故障排除。
作者:中鑫之宝鹤壁店 赵玉宾
赵玉宾,从事汽车维修工作10年,现任中鑫之宝汽车服务有限公司鹤壁分公司高级维修技师。