深圳营销网站有限公司今天新闻
本文的背景是:大学关系很好的老师问我能不能把Excel中1000个超链接网址对应的pdf文档下载下来。虽然可以手动一个一个点击下载,但是这样太费人力和时间了。我想起了之前的爬虫经验,给老师分析了一下可行性,就动手实践了。
没想到刚开始就遇到了困难,Excel中的超链接读到Python中直接显示成了中文。所以第一步就是把超链接对应的网址梳理出来,再用Python去爬取对应网址的pdf。本文分享批量爬虫下载文件的第一步,从Excel中把超链接转换成对应网址。下一篇文章分享批量爬虫下载pdf文件的代码。
文章目录
- 一、想要得到的效果
- 二、把超链接转换成对应网址的3个方法
- 1 方法一:单个超链接鼠标点击转换
- 2 方法二:自动套用格式
- 3 方法三:自定义VBA函数转换
- [1]启用【开发工具】,具体步骤如下:
- [2]自定义一个VBA函数GetAdrs。
- [3]用函数GetAdrs获取网址。
一、想要得到的效果
首先来看下想要得到的效果,第一列是原始的超链接,第二列是我们想要得到的对应网址。

二、把超链接转换成对应网址的3个方法
网上有很多方法实现超链接转换,我分享3个自己尝试的方法,前2个都失败了,最后1个是成功的。
1 方法一:单个超链接鼠标点击转换
第一个方法是选中想要把超链接转换成对应网址的单元格,接着双击鼠标左键,然后回车,单元格内容就会自动转换成网址。这种方法只适合转换超链接数量较少的情况,我在尝试过程中失败了。
2 方法二:自动套用格式
第二个方法是单击文件-更多-选项-校对-自动更正选项-键入时自动套用格式,选中Internet及网络路径替换为超链接,然后点击确定。第二个方法我尝试下来还是失败了……
3 方法三:自定义VBA函数转换
第三个方法是自定义VBA函数进行转换。
[1]启用【开发工具】,具体步骤如下:
左键单击菜单栏中的【文件】选项卡,然后左键单击【更多】,接着左键单击【选项】。左键单击【Excel 选项】中的【自定义功能区】选项,然后将【开发工具】前的小方格打上对勾,然后左键单击【确定】按钮,此时菜单栏中会多出一个选项【开发工具】。
step1:左键单击菜单栏中的【文件】选项卡,然后左键单击【更多】,接着左键单击【选项】。

step2:左键单击【Excel 选项】中的【自定义功能区】选项,然后将【开发工具】前的小方格打上对勾,然后左键单击【确定】按钮。
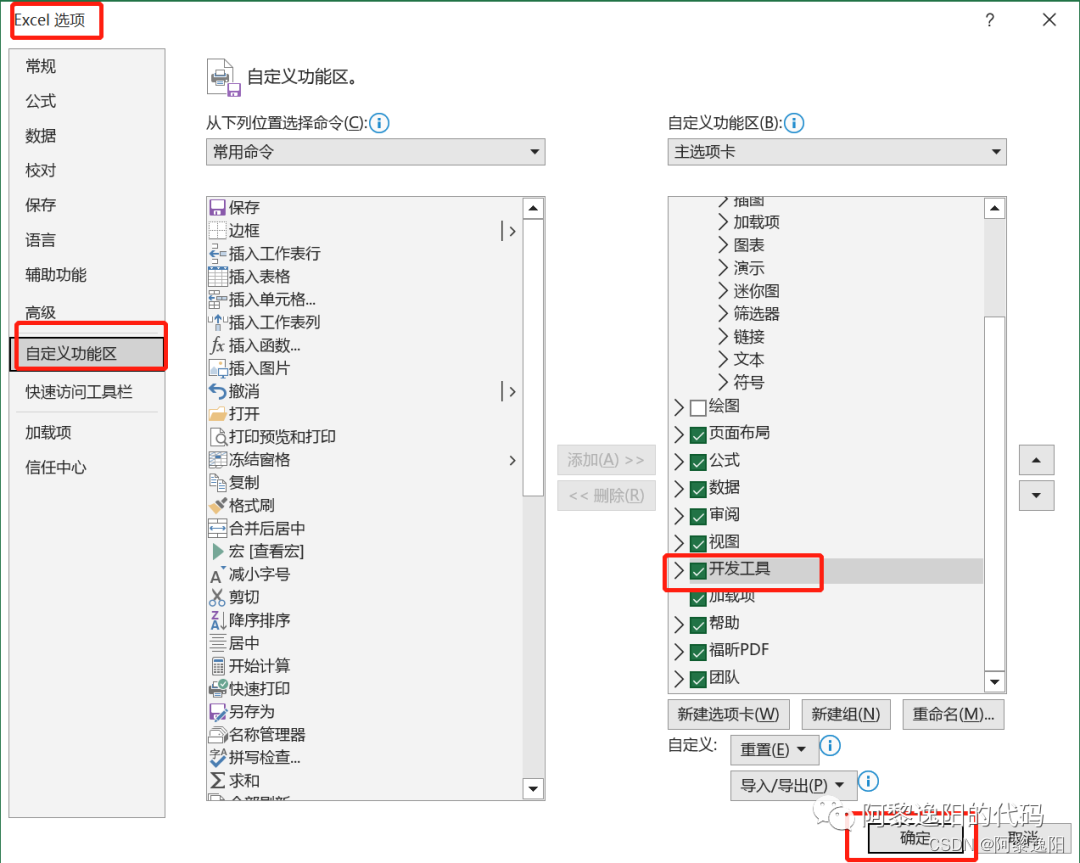
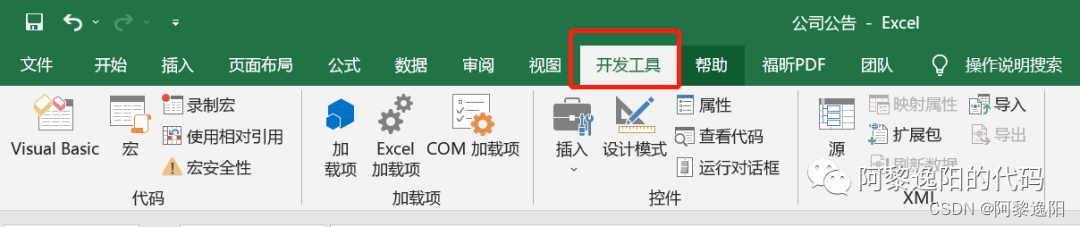
step3:查看菜单栏中是否多出一个选项【开发工具】。
[2]自定义一个VBA函数GetAdrs。
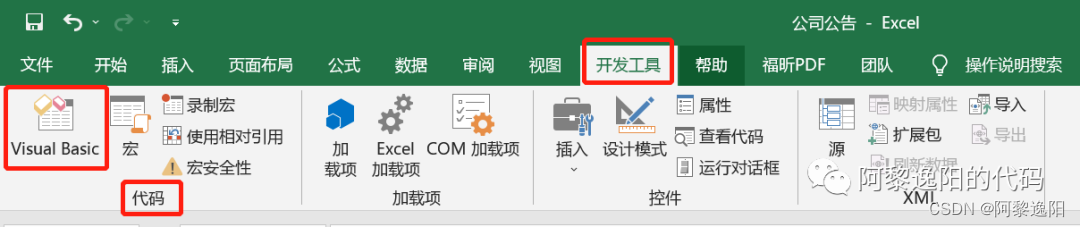
首先左键单击【开发工具】选项,然后左键单击【代码】功能区中的【Visual Basic编辑器】。右键单击【工程资源管理器】窗口,将鼠标指针移动至【插入】选项,左键单击二级菜单中的【模块】选项,插入【模块1】,并将以下代码复制粘贴到【模块1】的代码窗口后,最后关闭Visual Basic编辑器。
step1:左键单击【开发工具】选项,然后左键单击【代码】功能区中的【Visual Basic编辑器】。
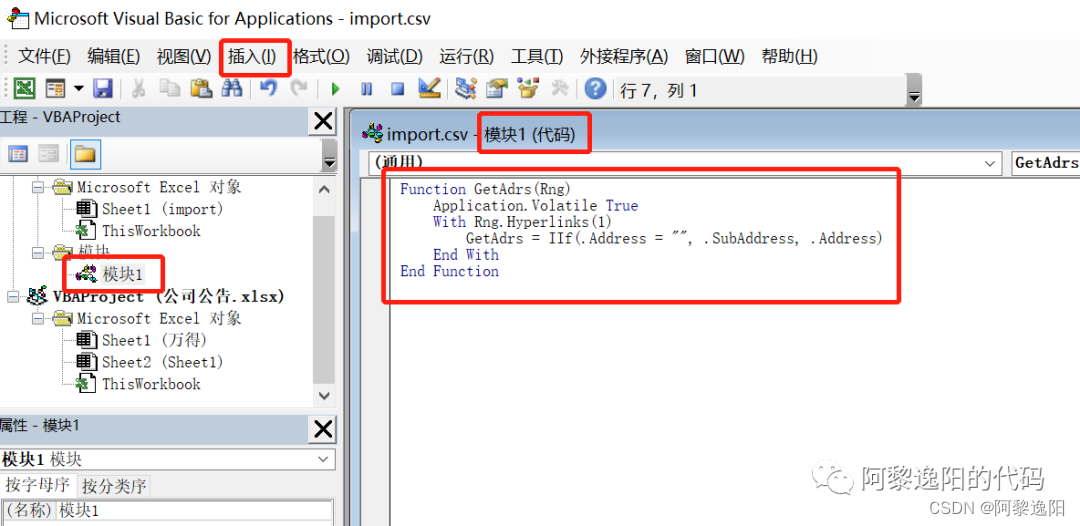
step2:右键单击【工程资源管理器】窗口,将鼠标指针移动至【插入】选项,左键单击二级菜单中的【模块】选项,插入【模块1】,并将以下代码复制粘贴到【模块1】的代码窗口后,最后关闭Visual Basic编辑器。
Function GetAdrs(Rng)Application.Volatile TrueWith Rng.Hyperlinks(1)GetAdrs = IIf(.Address = "", .SubAddress, .Address)End With
End Function
[3]用函数GetAdrs获取网址。
首先左键单击选中【B2】单元格,键入自定义函数【=GetAdrs(A2)】,按回车键进行计算。将鼠标指针移动至【B2】单元格右下角,当鼠标指针变成【+】号后,长按鼠标左键并向下拖动进行公式填充。
至此,把Excel中的超链接快速变成网址已经讲解完毕,感兴趣的同学可以自己实现一遍图片。
【限时免费进群】群内提供学习Python、玩转Python、风控建模、人工智能、数据分析相关招聘内推信息、优秀文章、学习视频,也可交流学习工作中遇到的相关问题。需要的朋友添加微信号19967879837,加时备注想进的群,比如风控建模。
参考文献
https://baike.baidu.com/
https://zhuanlan.zhihu.com/《数据科学与大数据技术》学校排名 - 知乎 (zhihu.com)
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)