宁夏建设工程质量网站.net企业网站
1 服务发现 SOME/IP SD
服务发现主要用于
- 定位服务实例
- 检测服务实例状态是否在运行
- 发布/订阅行为管理
SOME/IP SD 也是 SOME/IP 消息,遵循 SOME/IP 消息格式,有固定的 Message ID、Request ID 以及 Message Type 等。并对 SOME/IP Payload 进行了详细的定义。
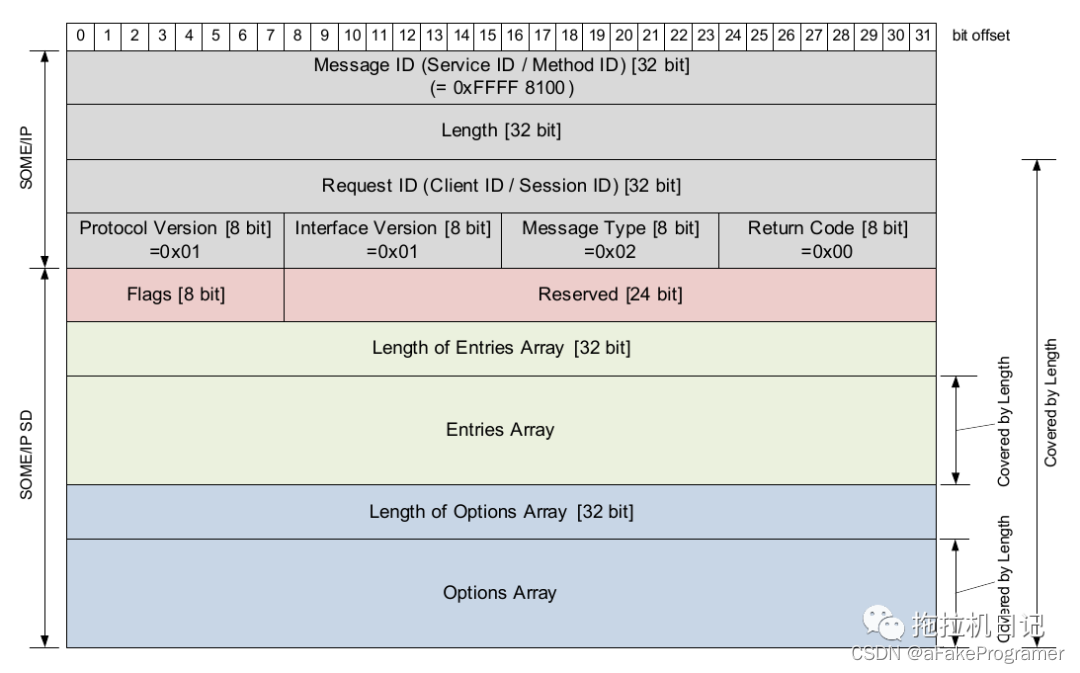
SOME/IP SD 只用 UDP 协议的 30490 端口通信。
2 SOME/IP SD 的 Payload 中主要包含 Entry 和 Option:
2.1 Entry:
Entry用于提供服务、发现服务、订阅事件组。
SOME/IP TTL是指SOME/IP服务发现(SD)中的Entry的生存时间(Time To Live),它表示一个Entry的有效期,单位是秒¹。
SOME/IP SD是一种基于IP的可扩展面向服务的中间件,它用于实现服务提供者和服务消费者之间的通信和协调²。
SOME/IP SD中有两种Entry:
- 服务Entry(Service Entry)