html5 做网站佛山市seo网站设计哪家好
IOU
- 什么是IOU?
- IOU应用场景
- 写代码调试
什么是IOU?
简单来说IOU就是用来度量目标检测中预测框与真实框的重叠程度。在图像分类中,有一个明确的指标准确率来衡量模型分类模型的好坏。其公式为:

这个公式显然不适合在在目标检测中使用。我们知道目标检测中都是用一个矩形框住被检测物体,又因为检测物体尺度不同,预测框与真实框或大或小。所以度量标准必然是具有尺度不变性的,那么大神们就引入了一个概念IOU(交并比),用预测框(A)和真实框(B)的交集除上二者的并集,其公式为:

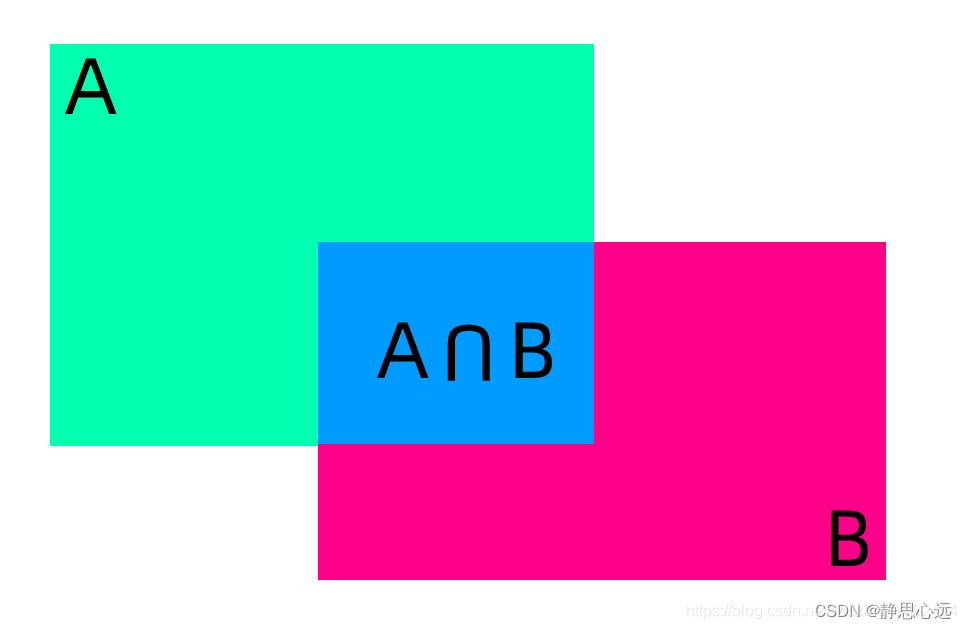
显而易见,IOU的值越高也说明A框与B框重合程度越高,代表模型预测越准确。反之,IOU越低模型性能越差。
IOU应用场景
除了作为目标检测的评价指标,IOU还有其他应用场景:
- 1.在anchor-based方法的目标检测中,根据IOU的值来区分正样本和负样本。
- 2.可以直接作为边界框回归的loss函数进行优化。
- 3.在NMS(非极大值抑制)对预测框筛选。
参考:目标检测中的IoU、GIoU、DIoU与CIoU
写代码调试
说了这么多,关键还得写代码调试看看
python代码
example1
import numpy as npdef IoU(box1, box2):b1_x1, b1_y1, b1_x2, b1_y2 = box1b2_x1, b2_y1, b2_x2, b2_y2 = box2xx1 = np.maximum(b1_x1, b2_x1)yy1 = np.maximum(b1_y1, b2_y1)xx2 = np.minimum(b1_x2, b2_x2)yy2 = np.minimum(b1_y2, b2_y2)w = np.maximum(0.0, yy2 - yy1)h = np.maximum(0.0, xx2 - xx1)inter = w * hIoU = inter/((b1_x2-b1_x1)*(b1_y2-b1_y1) + (b2_x2-b2_x1)*(b2_y2-b2_y1) - inter)print("IoU: "