娱乐网站建设公司网站制作先做数据库还是前台
机器视觉任务中语义分割方法的进化历史
- 一、基于传统方法的图像分割
- 二、基于卷积神经网络的图像分割
- 三、基于Attention机制的图像分割
- 四、语义分割模型的挑战与改进
在图像处理领域,传统图像分割技术扮演着重要角色。
一、基于传统方法的图像分割
这些方法包括大津法、分水岭法和区域生长法。
-
大津法通过分析图像的灰度特性,自动选择一个合适的阈值,将图像清晰地区分为目标区域和背景。这种方法的优势在于其自适应性,能够应对不同图像的特性。
-
分水岭法基于形态学的拓扑理论,通过识别灰度值分布中的局部最小值来确定分割阈值,实现图像的精确分割。这种方法适用于那些灰度值分布具有明显层次的图像。
-
区域生长法侧重于将具有相似灰度、强度和纹理等特征的相邻像素合并,形成具有一致性的区域。这种方法通过对图像中每个像素的逐一分析,构建出孔隙结构的准确图像。
虽然,这些方法简单,高效,但是传统方法不能完全挖掘图像数据的信息,只能简单的通过灰度值、颜色、直方图以及局部信息来进行分割。随着深度学习的发展,人们纷纷探索使用卷积神经网络对图像进行分割。
二、基于卷积神经网络的图像分割
全卷积网络(fully convolutional networks, FCN)通过将传统CNN中的全连接层替换为卷积层,使得网络能够处理任意尺寸的输入图像,并输出与输入尺寸相同的分割图像。这种设计保证了图像的空间信息不会丢失,对于图像的孔隙结构分析尤为有效。

在编码器中,3×3的卷积层后接一个ReLU激活函数,然后通过最大池化层进行下采样,这样不断重复,虽然特征图的尺寸在减小,但特征通道的数量却在增加。
解码器则采用了多种上采样技术,如反卷积和线性插值等,以恢复图像的细节。
U-net的一个创新之处在于其跳跃连接(skip connections),它将编码器中的深层特征与解码器中的浅层特征相结合,弥补了在下采样过程中可能丢失的细节,从而提高了分割的精度。
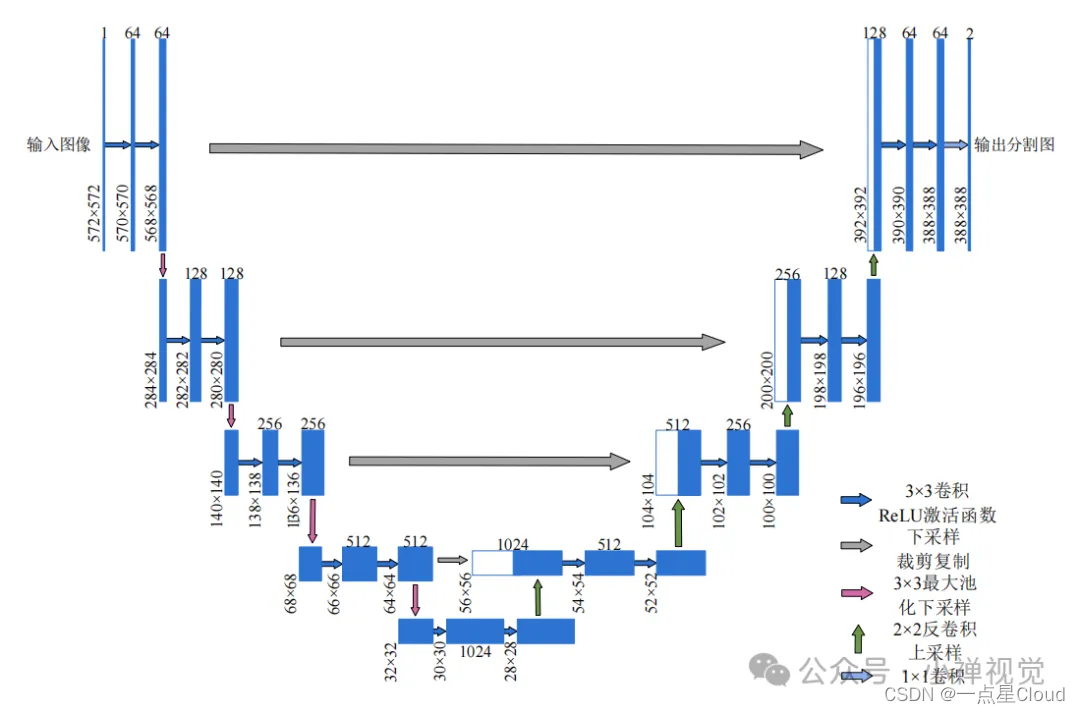
为了解决这些问题,研究者们开始探索基于注意力机制的Transformer模型。
三、基于Attention机制的图像分割
Transformer在图像分割中的应用是深度学习领域的一个重要进展。最初,Transformer架构是为自然语言处理任务设计的,但后来研究者发现它也能在图像处理任务中发挥巨大作用。
在图像分割中,Transformer通过自注意力机制(Self-Attention Mechanism)来捕捉图像中不同区域之间的关系,无需像卷积神经网络那样依赖于局部感受野。这使得Transformer能够更有效地处理图像中的长距离依赖关系,从而提高分割的精度。
其次,Transformer的一个关键优势是其灵活性和扩展性。它可以很容易地扩展到更大的模型尺寸,以处理更复杂的图像分割任务。此外,Transformer的并行化处理能力也比传统的卷积神经网络更强,这使得它在处理大规模图像数据时更加高效。
在实际应用中,Transformer可以与卷积神经网络结合使用,形成混合模型。例如,可以使用卷积神经网络来提取图像的局部特征,然后使用Transformer来整合这些特征,并进行最终的分割决策。这种混合模型结合了两者的优点,能够处理更复杂的图像分割任务。
此外,Transformer还可以用于弱监督学习,以处理标注不准确的图像数据。通过自注意力机制,Transformer能够从有限的标注信息中学习到更多的上下文信息,从而提高分割的鲁棒性。
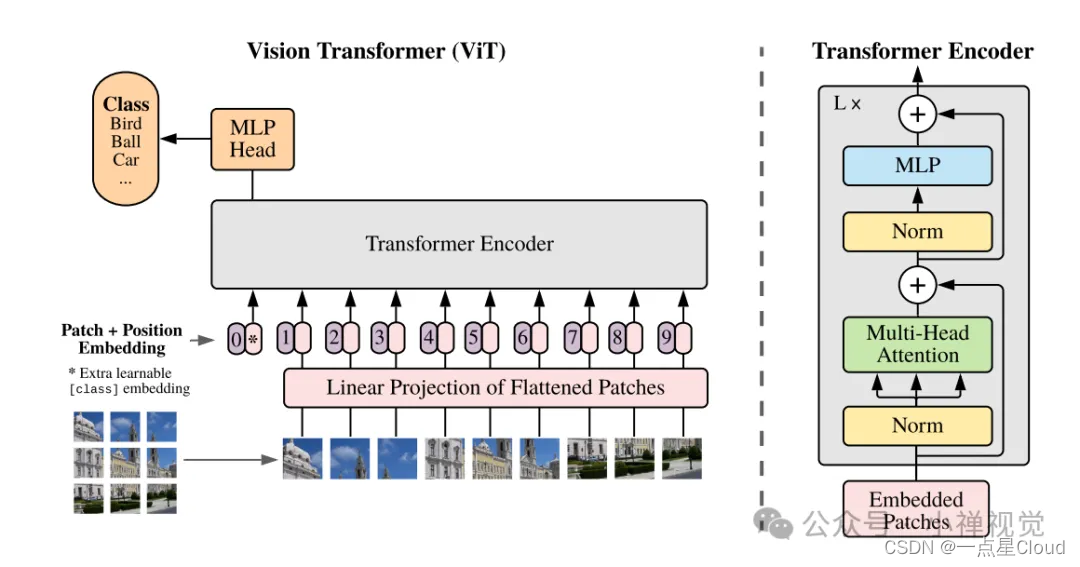
图中展示了一个基于Transformer的图像分割模型的架构。模型首先使用卷积层提取图像特征,然后将特征输入到Transformer中进行处理。在Transformer中,通过自注意力机制捕捉不同区域之间的关系,最后输出分割结果。
总的来说,Transformer在图像分割中的应用前景广阔,它提供了一种新的视角来处理图像分割问题,有望推动这一领域的进一步发展。
之前写过一篇“这么受欢迎的Transform到底解决了什么问题?”其中,详细介绍了Transform的发展大家可以看看。
四、语义分割模型的挑战与改进
虽然,目前很多深度神经网络模型在公开数据集上取得了显著的成功,但在真实环境中的应用仍面临挑战。主要困难在于标注数据集的质量和数量不足。深度学习模型需要大量的训练数据来调整参数,以达到良好的泛化效果。然而,对于图像的标注来说,这不仅耗时耗力,而且需要人为对每个像素进行手动标注,数据集的标注过程具有很高的主观性,难以保证精度和准确度。
弱监督学习的图像标注为这一问题提供了一种可能的解决方案,是未来研究的重点。它包括不完全监督、不确切监督和不准确监督三种形式。在不完全监督的情况下,训练数据集中只有部分数据被标注;不确切监督则意味着数据集中的标签是粗粒度的,可能包含错误;而不准确监督则涉及到标签的不精确性。在这些情况下,关键在于如何在训练过程中补充缺失的监督信息,以提高模型的性能。