门户网站建设的步骤前端开发培训机构哪家好
一、目的
本文主要记录物联网设备接入MQTT以及对接服务端SpringBoot整个的交互流程和使用。
二、概念
2.1什么是MQTT?
MQTT是基于TCP/IP协议栈构建的异步通信消息协议,是一种轻量级的发布、订阅信息传输协议。可以在不可靠的网络环境中进行扩展,适用于设备硬件存储空间或网络带宽有限的场景。使用MQTT协议,消息发送者与接收者不受时间和空间的限制。物联网平台支持设备使用MQTT协议接入。
简单来讲:为物联网弱联网设备提供可靠的消息传输,比如传感器、蓝牙、手表等。本文的应用场景是葡萄糖检测仪,实时上传接受推送消息至服务器,服务器推送到设备端通知消息等。
2.2工作原理
当然不能直接使用,下边简单图解一下
MQTT(Message Queuing Telemetry Transport)由IBM于1999年开发的一种基于发布订阅模式"的轻量级的消息传输协议!
发布订阅模式是一种传统的客户端-服务器架构的替代方案,因为一般传统的客户端-服务器是客户端能够直接和服务器进行通信完成消息的传输。发布订阅模式会将发送消息的发布者publisher与接收消息的订阅者subscribers进行分离,publisher与subscribers 并不会直接通信,他们甚至都不清楚对方是否存在,他们之间的交流由第三方组件broker代理。
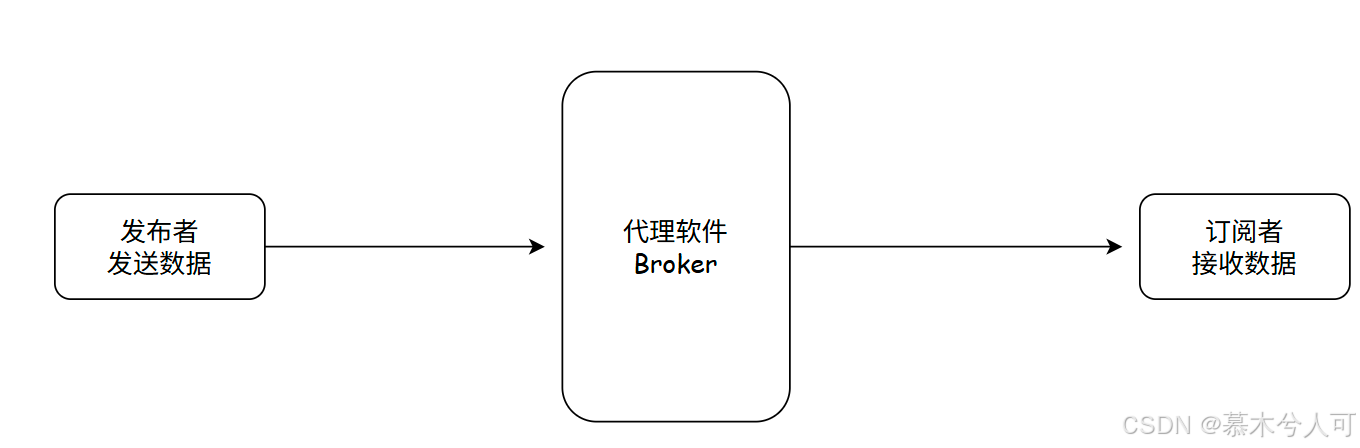
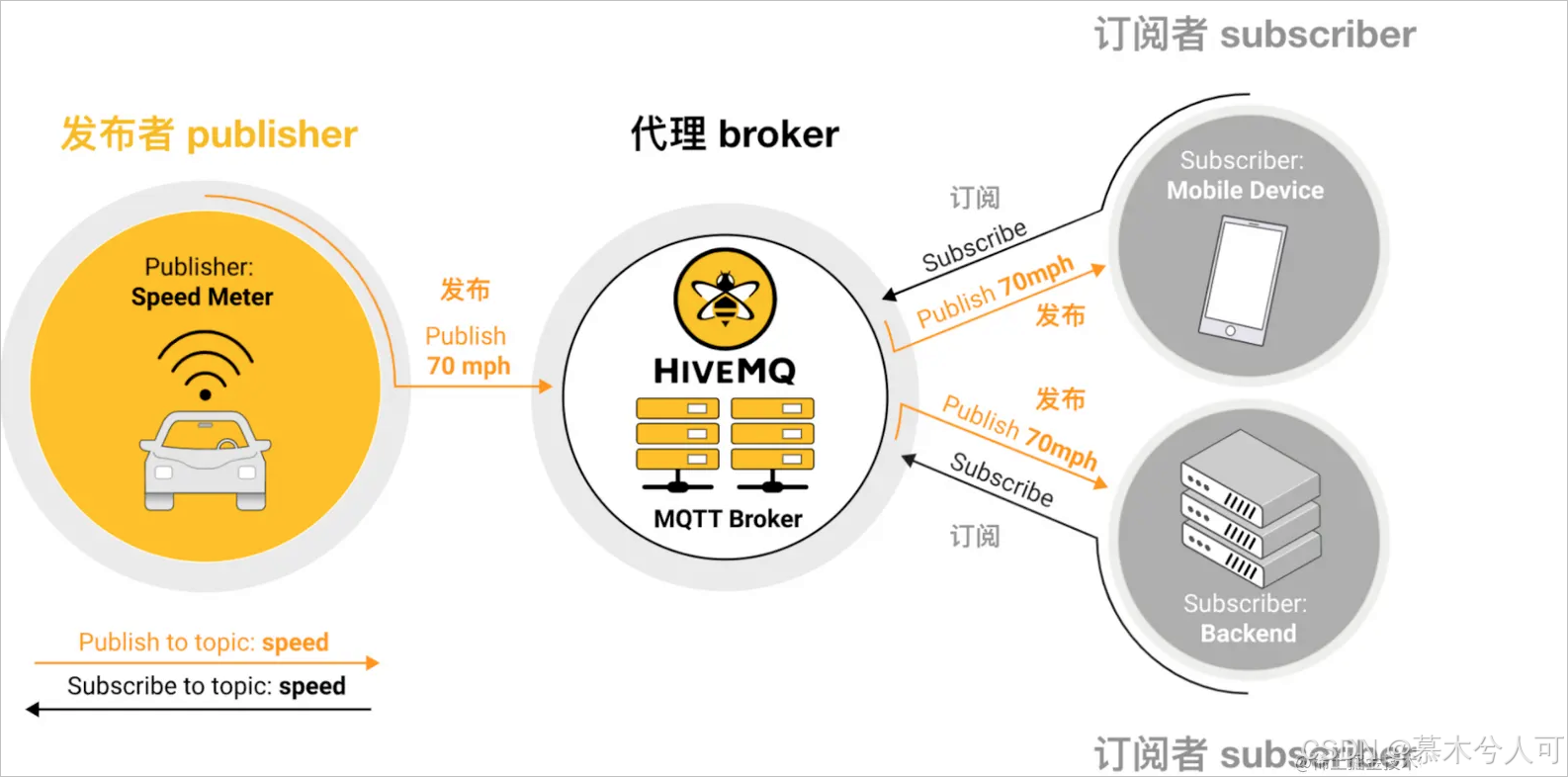
看到这个有没有很熟悉?像不像RabbitMQ的发布订阅?像不像RocketMQ?
没错,其实都是一个套路。
MQTT特殊的是,它只是一种通信协议,如果想要使用它,就需要基于MQTT协议的服务端实现,哎,这个服务端的实现,就类似消息中心的功能,负责消息的中转,甚至还能在客户端崩溃时,缓存接收到的消息(正因为此,它的可靠性是极高的)。
看到中间的 MQTT Broker了吗,这个就是对MQTT协议服务端的实现,负责处理客户端请求的关键组件,包括建立连接、断开连接、订阅和取消订阅等操作,同时还负责消息的转发。
2.3如何使用
如果没有购买云消息队列MQTT,就需要用第三方实现了MQTT的消息代理
2.3.1 EMQX
EMQX,是一款实现了MQTT协议的,开源的MQTT消息代理软件。MQTT定义了消息通讯的规则和流程,而EMQX则是遵循这些规则的软件,使得设备能够依据MQTT协议进行有效通信。在新版本的EMQX中同时支持MQTT3.1.1协议和5.0协议。
下载地址:
官网地址
其他代理软件
2.3.2 EMQX部署
选择EMQX企业版进行部署:企业版
购买云服务器ECS(不想买的话可以用虚拟机安装,也可以去薅免费试用的),安装Docker:
# 移除旧版本docker
sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine# 配置docker yum源。
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 安装 最新 docker
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin# 启动& 开机启动docker; enable + start 二合一
systemctl enable docker --now# 配置加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
运行启动
docker run -d --name emqx-enterprise \-p 1883:1883 -p 8083:8083 \-p 8084:8084 -p 8883:8883 \-p 18083:18083 \-v emqx_data:/opt/emqx/data \-v emqx_log:/opt/emqx/log \-v emqx_etc:/opt/emqx/etc \emqx/emqx-enterprise:5.6.1
常见端口介绍:
| 端口号 | 说明 |
|---|---|
| 1883 | TCP端口 |
| 8083 | WebSocket端口 |
| 8084 | WebSocket Secure 端口 |
| 8883 | SSL/TLS 端口 |
| 18083 | Broker的Dashboard访问端口号 |
下边就可以使用了,至于这个软件的功能,这里不赘述了,有兴趣的可以找我要笔记。
2.4 客户端
2.4.1 运行docker容器模拟消息接收客户端
docker run -e TOPIC="xxx" \-e INSTANCE_ID="mqtt-cn-xx" \-e ENDPOINT="xx" \-e DEVICE_ID="xx" \-e GROUP_ID="您在 Group 管理页面中创建的 Group 的 ID" \-e AK="您访问阿里云的 AccessKey" \-e SK="您访问阿里云的 SecretKey" \registry.cn-hangzhou.aliyuncs.com/aliyun-mq/mqtt
# TOPIC 你创建的Topic
# -e TOPIC="cgm_monitor"
# 设置 MQTT 的主题(Topic)为 cgm_monitor。MQTT 客户端将订阅或发布到这个主题。# -e INSTANCE_ID="mqtt-cn-hic4av7iy01"
# 设置阿里云 MQTT 实例的 ID。这是您在阿里云上创建的 MQTT 实例的唯一标识。# -e ENDPOINT="mqtt-cn-hic4av7iy01.mqtt.aliyuncs.com"
# 设置 MQTT 服务的接入点(Endpoint),即 MQTT 服务器的地址。# -e DEVICE_ID="i3c7bfbe"
# 设置设备 ID。MQTT 客户端会以这个设备身份连接到阿里云 MQTT 服务。# -e GROUP_ID="您在 Group 管理页面中创建的 Group 的 ID"
# 设置设备所属的 Group ID。Group 是阿里云 MQTT 服务中用于管理一组设备的逻辑单元。不懂看下图
先建立topic才能有公网访问地址,也要建Group
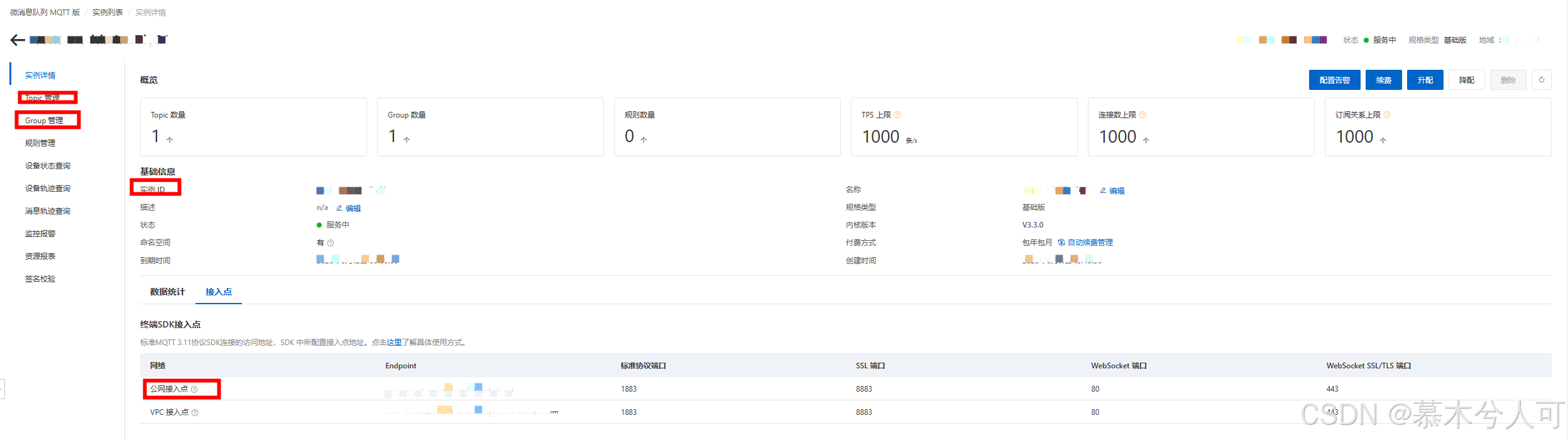
建立topic

建立Group

签名校验得到,Client ID/用户名/密码
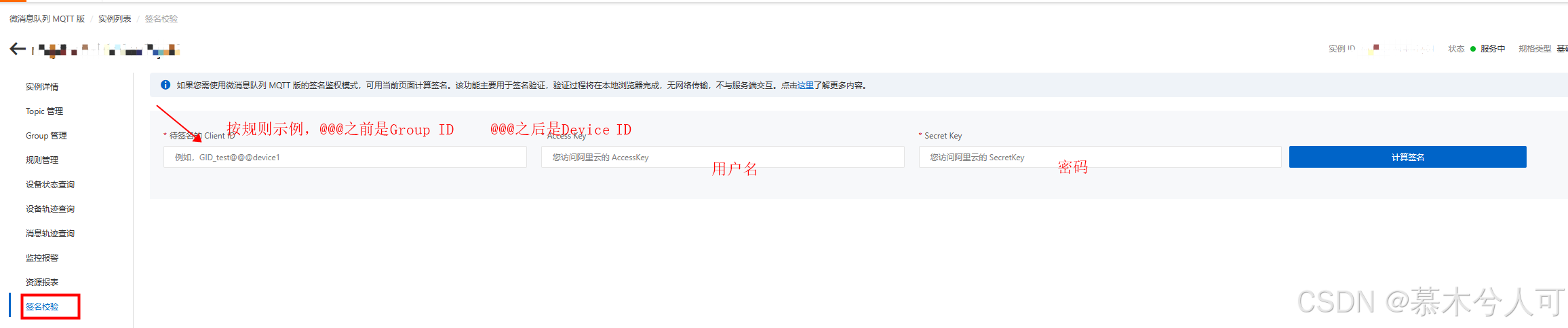
这样 去云服务运行上面这段docker命令,就可以得到一个连接云MQTT的客户端,也就是消费者。
2.4.2 使用MQTTX客户端
MQTTX 简化了使用 MQTT broker 的过程,包括连接,发布与订阅消息主题。无论你使用桌面版,命令行,或是网页版,MQTTX 使每个关键步骤都更加顺滑。
官网地址:MQTTX
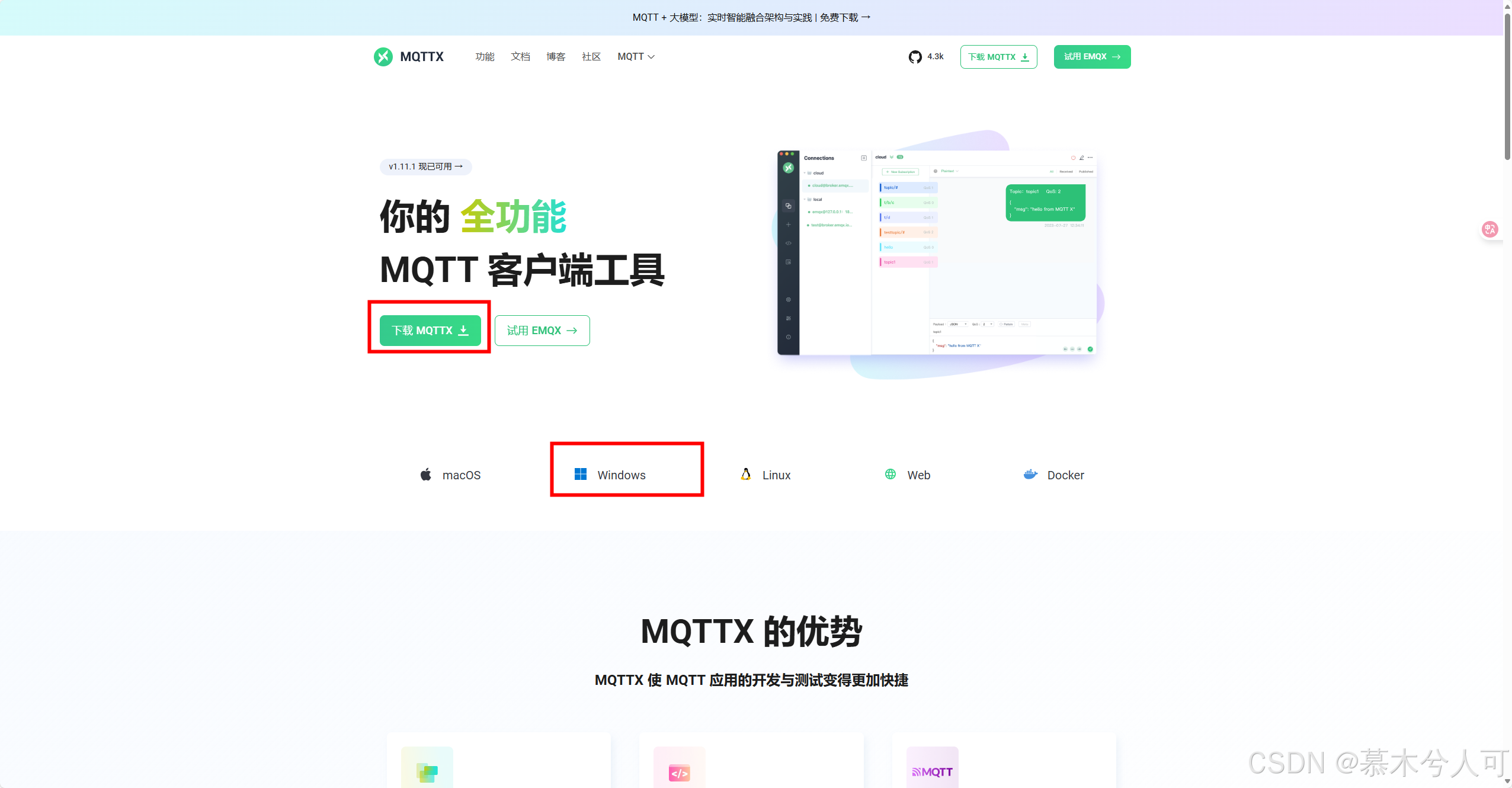
下载后傻瓜式安装就行,下一步直到完成。
可以设置下中文
点击新建连接
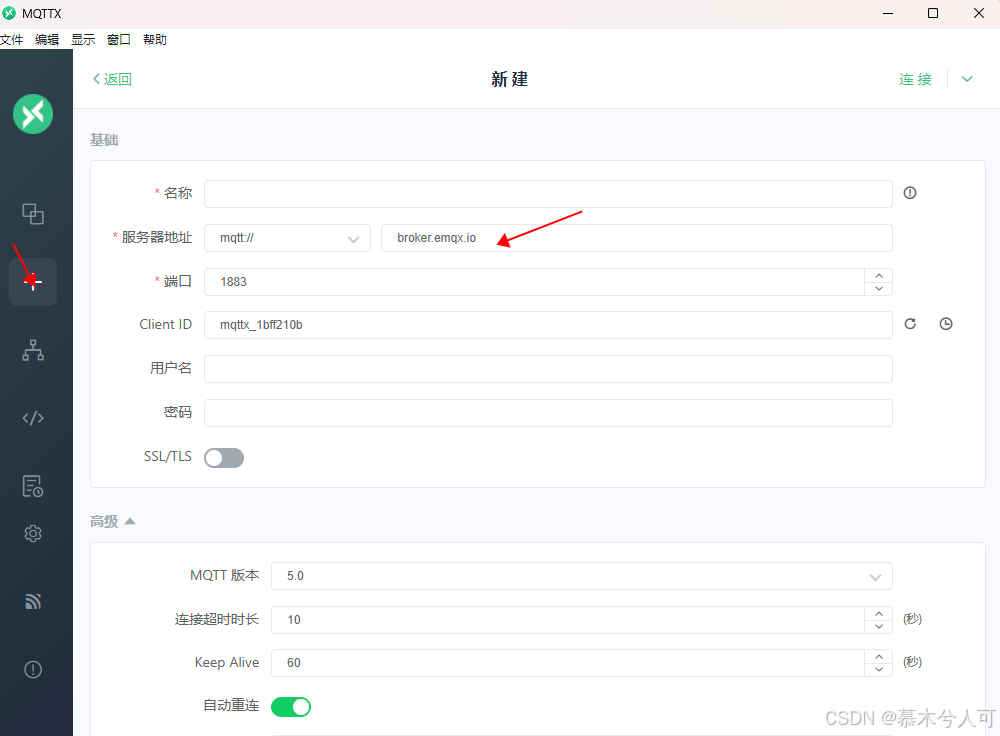
可以参考我的配置:
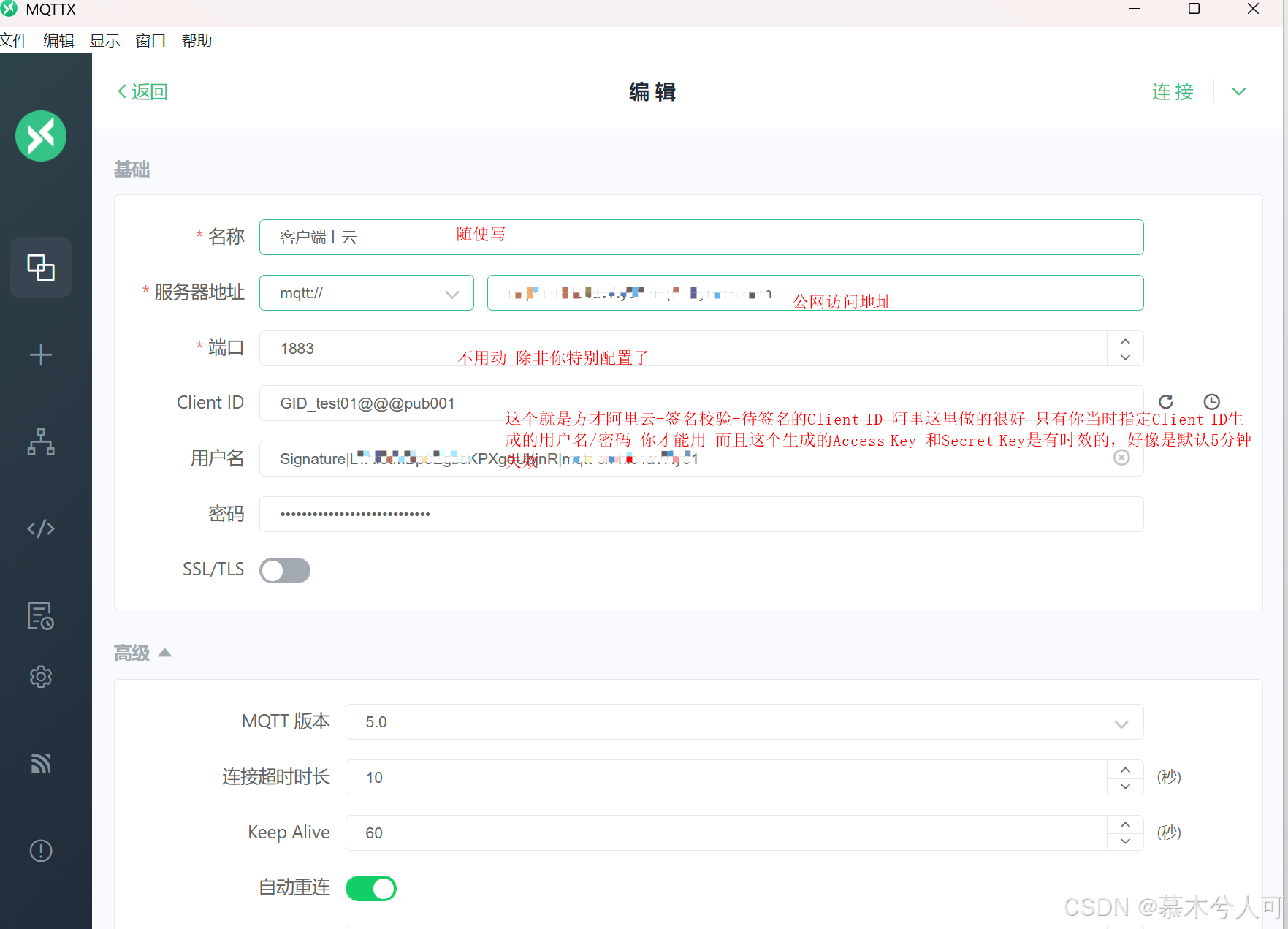
如果用的不是云MQTT,本地自己docker安装的 其实访问更简单,直接界面化Broker那里自己设置用户名/密码。
下边就可以连接了
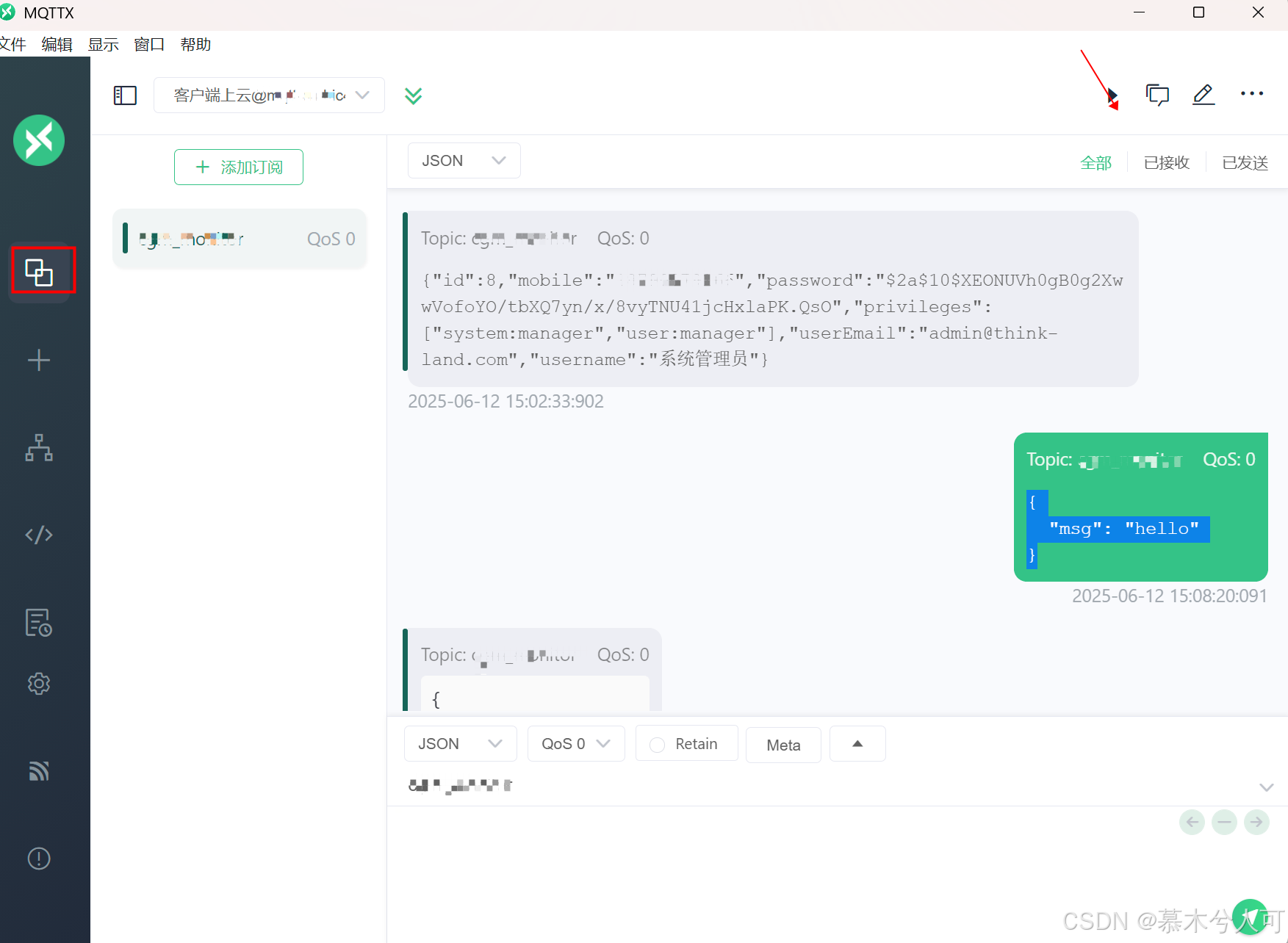
如果你都配置正确,点击连接会出现已连接
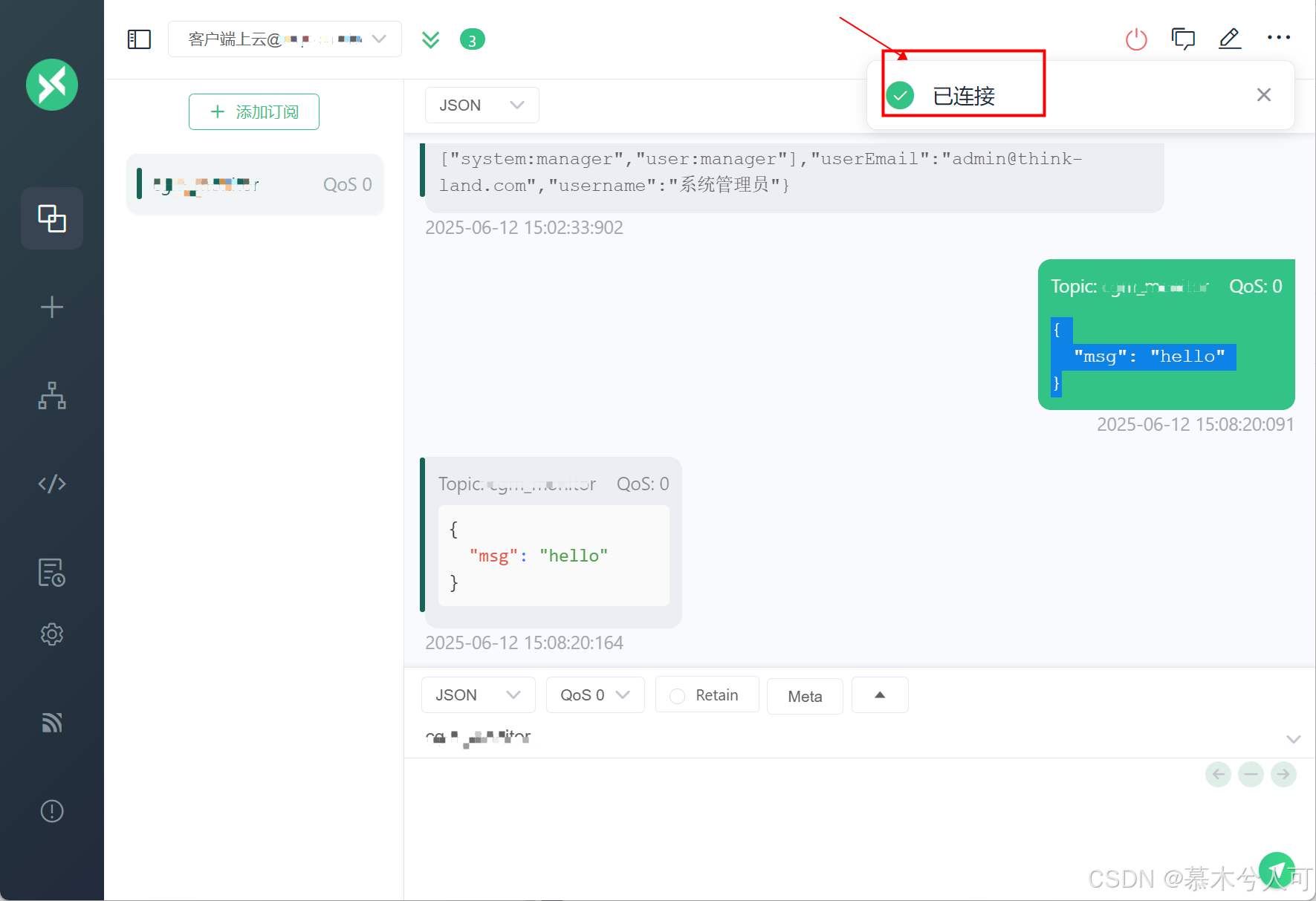
下边演示下在阿里云MQTT控制台,快速体验消息收发:
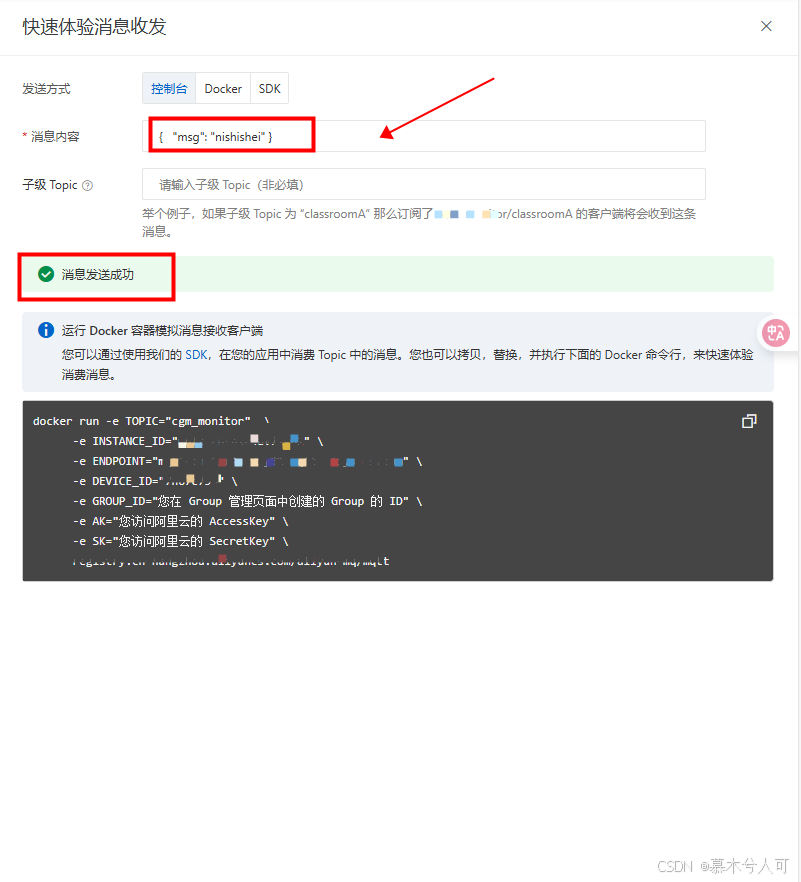
可以看到,已经发送成功了!那么客户端MQTTX有没有收到消息呢?
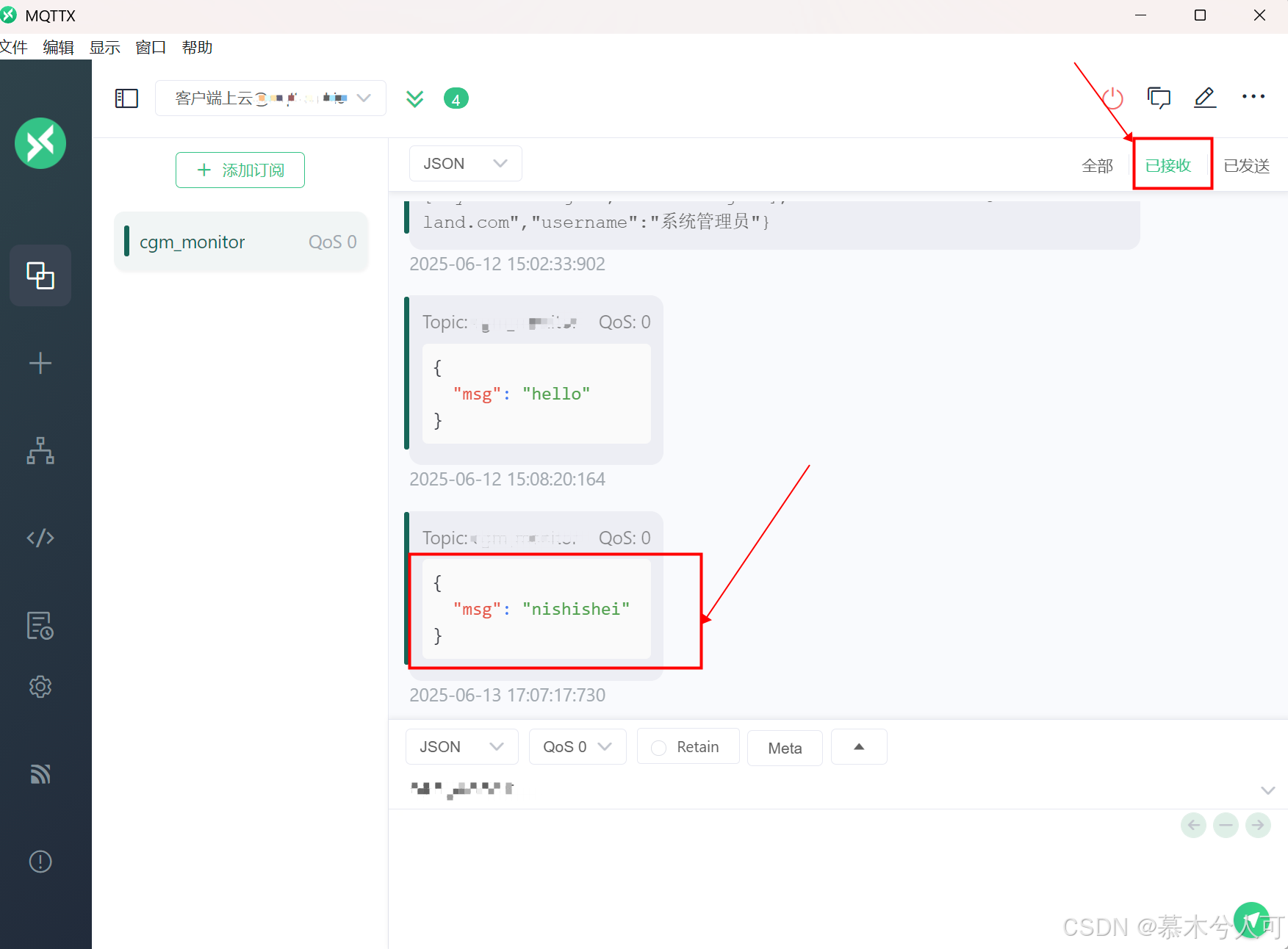
可以看到,确实是收到了!!!如此便成功了!
2.4.3SpringBoot集成MQTT
这里把源码贴在这里,有兴趣的也可以去阿里云官网看,一样的
package com.kiki.app.mqtt.demo;import java.util.concurrent.ExecutorService;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;import com.kiki.app.util.ConnectionOptionWrapper;
import org.eclipse.paho.client.mqttv3.IMqttDeliveryToken;
import org.eclipse.paho.client.mqttv3.MqttCallbackExtended;
import org.eclipse.paho.client.mqttv3.MqttClient;
import org.eclipse.paho.client.mqttv3.MqttException;
import org.eclipse.paho.client.mqttv3.MqttMessage;
import org.eclipse.paho.client.mqttv3.persist.MemoryPersistence;/*** 本代码提供签名鉴权模式下 MQ4IOT 客户端发送消息到 MQ4IOT 客户端的示例,其中初始化参数请根据实际情况修改* 签名模式即使用阿里云账号系统提供的 AccessKey 和 SecretKey 对每个客户端计算出一个独立的签名供客户端识别使用。* 对于实际业务场景使用过程中,考虑到私钥 SecretKey 的隐私性,可以将签名过程放在受信任的环境完成。** 完整 demo 工程,参考https://github.com/AliwareMQ/lmq-demo*/
public class MQ4IoTSendMessageToMQ4IoTUseSignatureMode {public static void main(String[] args) throws Exception {/*** MQ4IOT 实例 ID,购买后控制台获取*/String instanceId = "test001";/*** 接入点地址,购买 MQ4IOT 实例,且配置完成后即可获取,接入点地址必须填写分配的域名,不得使用 IP 地址直接连接,否则可能会导致客户端异常。* */String endPoint = "xxx";/*** 账号 accesskey,从账号系统控制台获取* 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。* 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。* 本示例以把AccessKey ID和AccessKey Secret保存在环境变量为例说明。运行本代码示例之前,请先配置环境变量MQTT_AK_ENV和MQTT_SK_ENV* 例如:export MQTT_AK_ENV=<access_key_id>* export MQTT_SK_ENV=<access_key_secret>* 需要将<access_key_id>替换为已准备好的AccessKey ID,<access_key_secret>替换为AccessKey Secret。*/String accessKey = "xxx";/*** 账号 secretKey,从账号系统控制台获取,仅在Signature鉴权模式下需要设置*/String secretKey = "xxx";/*** MQ4IOT clientId,由业务系统分配,需要保证每个 tcp 连接都不一样,保证全局唯一,如果不同的客户端对象(tcp 连接)使用了相同的 clientId 会导致连接异常断开。* clientId 由两部分组成,格式为 GroupID@@@DeviceId,其中 groupId 在 MQ4IOT 控制台申请,DeviceId 由业务方自己设置,clientId 总长度不得超过64个字符。*/String clientId = "GID_test01@@@pub001";/*** MQ4IOT 消息的一级 topic,需要在控制台申请才能使用。* 如果使用了没有申请或者没有被授权的 topic 会导致鉴权失败,服务端会断开客户端连接。*/final String parentTopic = "xxx";/*** MQ4IOT支持子级 topic,用来做自定义的过滤,此处为示意,可以填写任何字符串,具体参考https://help.aliyun.com/document_detail/42420.html?spm=a2c4g.11186623.6.544.1ea529cfAO5zV3* 需要注意的是,完整的 topic 参考 https://help.aliyun.com/document_detail/63620.html?spm=a2c4g.11186623.6.554.21a37f05ynxokW。*/final String mq4IotTopic = parentTopic + "/" + "testMq4Iot";/*** QoS参数代表传输质量,可选0,1,2,根据实际需求合理设置,具体参考 https://help.aliyun.com/document_detail/42420.html?spm=a2c4g.11186623.6.544.1ea529cfAO5zV3*/final int qosLevel = 0;ConnectionOptionWrapper connectionOptionWrapper = new ConnectionOptionWrapper(instanceId, accessKey, secretKey, clientId);final MemoryPersistence memoryPersistence = new MemoryPersistence();/*** 客户端使用的协议和端口必须匹配,具体参考文档 https://help.aliyun.com/document_detail/44866.html?spm=a2c4g.11186623.6.552.25302386RcuYFB* 如果是 SSL 加密则设置ssl://endpoint:8883*/final MqttClient mqttClient = new MqttClient("tcp://" + endPoint + ":1883", clientId, memoryPersistence);/*** 客户端设置好发送超时时间,防止无限阻塞*/mqttClient.setTimeToWait(5000);final ExecutorService executorService = new ThreadPoolExecutor(1, 1, 0, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());mqttClient.setCallback(new MqttCallbackExtended() {@Overridepublic void connectComplete(boolean reconnect, String serverURI) {/*** 客户端连接成功后就需要尽快订阅需要的 topic*/System.out.println("connect success---------------------------------------------------");executorService.submit(new Runnable() {@Overridepublic void run() {try {final String topicFilter[] = {mq4IotTopic};final int[] qos = {qosLevel};mqttClient.subscribe(topicFilter, qos);} catch (MqttException e) {e.printStackTrace();}}});}@Overridepublic void connectionLost(Throwable throwable) {throwable.printStackTrace();}@Overridepublic void messageArrived(String s, MqttMessage mqttMessage) throws Exception {/*** 消费消息的回调接口,需要确保该接口不抛异常,该接口运行返回即代表消息消费成功。* 消费消息需要保证在规定时间内完成,如果消费耗时超过服务端约定的超时时间,对于可靠传输的模式,服务端可能会重试推送,业务需要做好幂等去重处理。超时时间约定参考限制* https://help.aliyun.com/document_detail/63620.html?spm=a2c4g.11186623.6.546.229f1f6ago55Fj*/System.out.println("receive msg from topic " + s + " , body is " + new String(mqttMessage.getPayload()));}@Overridepublic void deliveryComplete(IMqttDeliveryToken iMqttDeliveryToken) {System.out.println("send msg succeed topic is : " + iMqttDeliveryToken.getTopics()[0]);}});mqttClient.connect(connectionOptionWrapper.getMqttConnectOptions());for (int i = 0; i < 10; i++) {MqttMessage message = new MqttMessage("hello mq4Iot pub sub msg".getBytes());message.setQos(qosLevel);/*** 发送普通消息时,topic 必须和接收方订阅的 topic 一致,或者符合通配符匹配规则*/mqttClient.publish(mq4IotTopic, message);/*** MQ4IoT支持点对点消息,即如果发送方明确知道该消息只需要给特定的一个设备接收,且知道对端的 clientId,则可以直接发送点对点消息。* 点对点消息不需要经过订阅关系匹配,可以简化订阅方的逻辑。点对点消息的 topic 格式规范是 {{parentTopic}}/p2p/{{targetClientId}}*/final String p2pSendTopic = parentTopic + "/p2p/" + clientId;message = new MqttMessage("hello mq4Iot p2p msg".getBytes());message.setQos(qosLevel);mqttClient.publish(p2pSendTopic, message);}Thread.sleep(Long.MAX_VALUE);}
}有需要的同学,可以私聊找我要源码!!!