怎么创建子网站展馆展示设计公司哪家好
快速设置header:
点击左侧的齿轮,选择User Snippets:
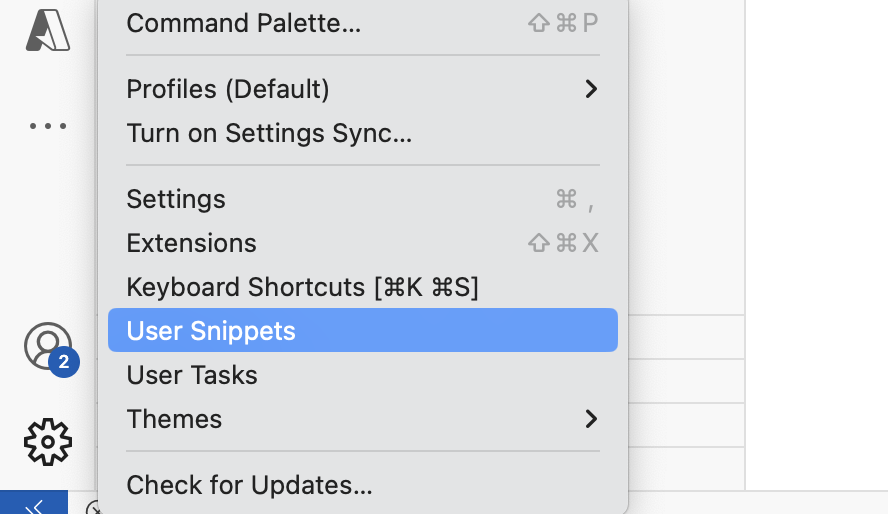
在出现的选择框中输入python,选择python.json

在最外层的{ }内部添加以下内容
"HEADER": {"prefix": "header","body": ["# -*- encoding: utf-8 -*-", "'''","file :$TM_FILENAME","Date : $CURRENT_YEAR/$CURRENT_MONTH/$CURRENT_DATE $CURRENT_HOUR:$CURRENT_MINUTE:$CURRENT_SECOND","Author : yourName","Description: ","'''","","$0"],},"Print to console":{"prefix": "main","body": ["if __name__ == '__main__':"," ...",],"description": "python–main"}设置完成后返回的代码界面:
输入"header" 和"main" 可快速插入代码头文件和main函数,如果不行的话重启下vscode试试。
参考:
vscode配置header指令添加头部注释或KoroFileHeader自动添加头部解释_vs code设置header-CSDN博客
VSCode 配置快速输入Python的Main函数方法_vscode python main-CSDN博客
若有收获,就点个赞吧