做网站3年3万深圳创业贷款
Ubuntu 12.04增加右键命令:在终端中打开
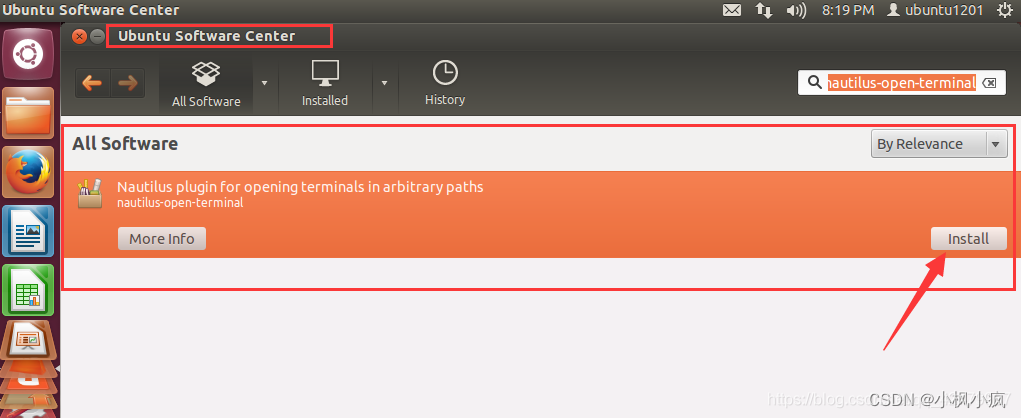
软件中心:搜索nautilus-open-terminal安装
用快捷键Ctrl+T打开命令行输入:
sudo apt-get install nautilus-open-terminal重新加载文件管理器
nautilus -q或注销再登录即要使用
Ubuntu 12.04增加右键命令:在终端中打开
软件中心:搜索nautilus-open-terminal安装
用快捷键Ctrl+T打开命令行输入:
sudo apt-get install nautilus-open-terminal重新加载文件管理器
nautilus -q或注销再登录即要使用