网站登录密码忘记了怎么办搜狗关键词优化软件
docker数据卷详细讲解及数据卷常用命令
Docker 数据卷是一种将宿主机的目录或文件直接映射到容器中的特殊目录,用于实现数据的持久化和共享。Docker 数据卷有以下特点:
- 数据卷可以在一个或多个容器之间共享和重用,不受容器的生命周期影响。
- 数据卷可以直接在宿主机上进行修改和管理,不需要通过 Docker 引擎。
- 数据卷可以提供更高的 I/O 性能,比使用联合文件系统的容器更快。
- 数据卷可以采用以下三种方式之一来创建和使用:
- 宿主机数据卷:将宿主机的目录或文件挂载到容器中,可以指定绝对路径或相对路径。
- 命名数据卷:使用 Docker 管理的数据卷,可以指定一个名称,方便查找和引用。
- 数据卷容器:使用一个专门的容器来提供数据卷,其他容器可以通过 --volumes-from 参数来挂载该容器的数据卷。
文章目录
- docker数据卷详细讲解及数据卷常用命令
- 一、数据卷
- 什么是数据卷?
- 如何挂载数据卷?
- 1、在创建容器时,使用-v数据卷名:容器内目录完成挂载
- 2、这个命令表示将nginx容器的/usr/share/nginx/路径下的文件,挂载到本地nginx文件下
- 3、此时,本地的 /var/lib/docker/volumes/html/_data这个路径就是nginx挂载后的文件目录
- 4、进入后,即可查看到这个目录下的文件,此时,在这个目录下对文件的修改,就会映射到nginx容器中的数据,同步变化。
- 数据卷常用命令
- 1、创建数据卷
- 2、查看所有数据卷
- 3、删除指定数据卷
- 4、查看某个数据卷的详情
- 5、清除数据卷
一、数据卷
什么是数据卷?
数据卷是一个虚拟目录,它将宿主机目录映射到容器目录,方便我们操作容器内文件,或者方便迁移容器产生的数据
如何挂载数据卷?
1、在创建容器时,使用-v数据卷名:容器内目录完成挂载
docker run -d --name nginx -p80:80 -v html:/usr/share/nginx/
2、这个命令表示将nginx容器的/usr/share/nginx/路径下的文件,挂载到本地nginx文件下
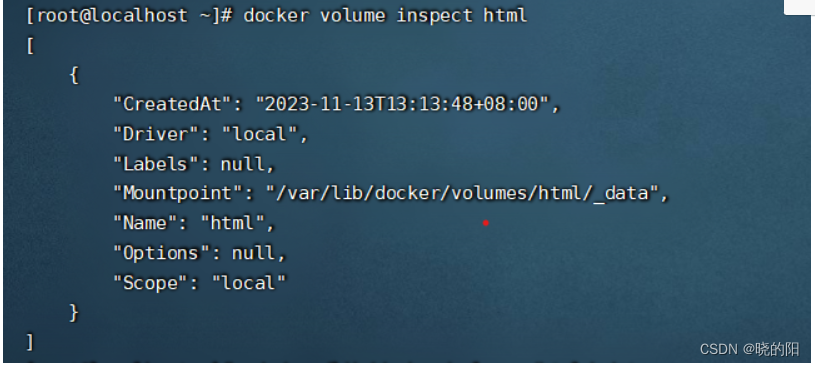
挂载之后,使用这个命令可查看详细信息
docker volume inspect html
3、此时,本地的 /var/lib/docker/volumes/html/_data这个路径就是nginx挂载后的文件目录
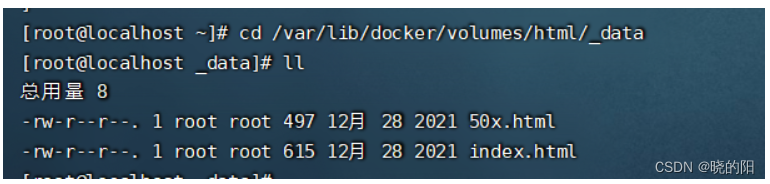
4、进入后,即可查看到这个目录下的文件,此时,在这个目录下对文件的修改,就会映射到nginx容器中的数据,同步变化。
容器创建时,如果发现挂载的数据卷不存在时,会自动创建
数据卷常用命令
1、创建数据卷
docker volume create
2、查看所有数据卷
docker volume ls
3、删除指定数据卷
docker volume rm
4、查看某个数据卷的详情
docker volume inspect
5、清除数据卷
docker volume prune