恩施建设厅网站南宁网站开发公司
1.把端口号对外暴露,通过ip+端口号进行访问
使用Service里面的NodePort实现
2.NodePort缺陷
在每个节点上都会起到端口,在访问时候通过任何节点,通过节点ip+暴露端口号实现访问
意味着每个端口只能使用一次,一个端口对应一个应用
实际访问中都是使用域名,根据不同域名跳转到不同端口服务中
3.Ingress和Pod关系
pod和ingress通过service关联的
ingress作为统一入口,由service关联一组pod
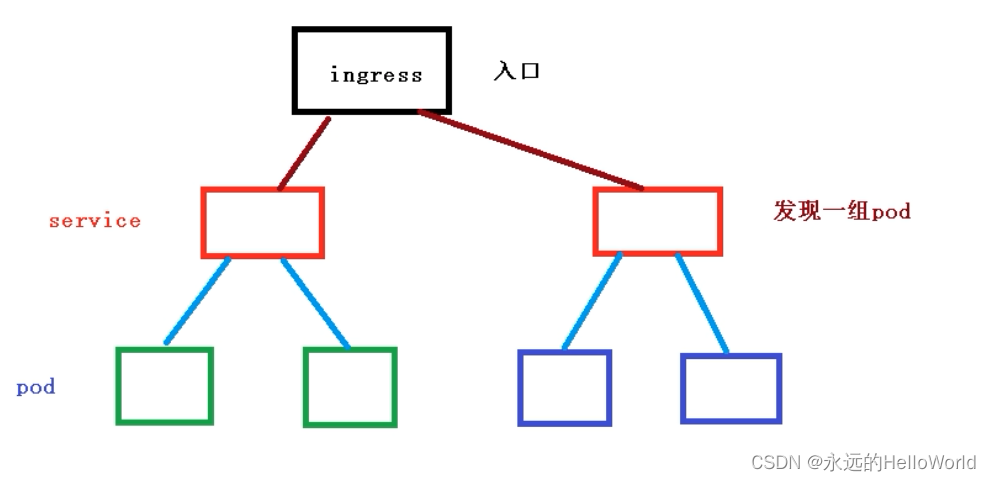
4.ingress工作流程
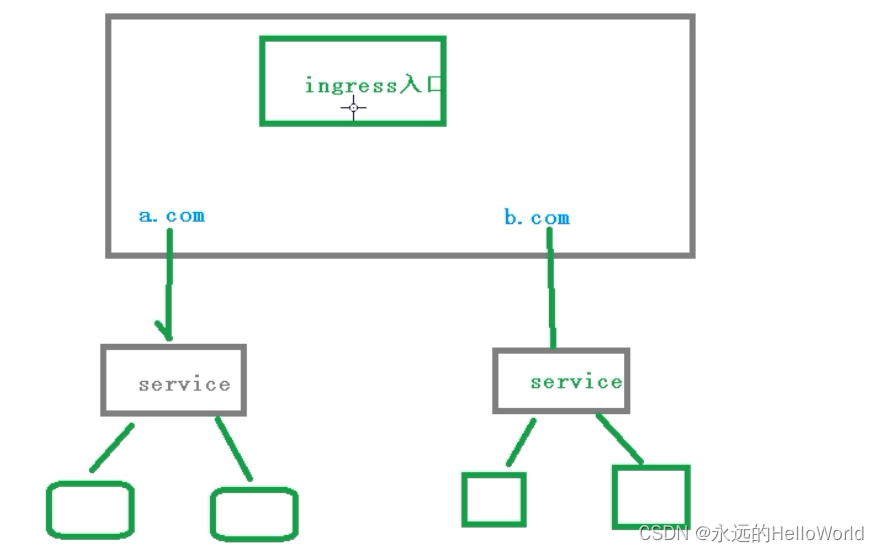
5.使用ingress
(1)创建应用,对外暴露端口使用NodePort
(2)部署ingress Controller
(3)查看ingress controller状态
(4)创建ingress规则