网站建设培训公司排名泰州网站建设托管

前言
Compose 的语法简洁、代码效率非常高,这主要得益于 Compose Compiler 的一系列编译期魔法,帮开发者生成了很多样板代码。但编译期插桩也阻碍了我们对于 Compose 运行原理的认知,想要真正读懂 Compose 就必须先了解它的 Compiler。本系列文章将带大家揭开 Compose Compiler 的神秘面纱。
Compose 是一个 Kotlin Only 框架,所以 Compose Compiler 的本质是一个 KCP(Kotlin Compiler Plugin)。在研究 Compose Compiler 源码之前,先要铺垫一些 Kotlin Compiler 以及 KCP 的基础知识
Kotlin 编译流程
Kotlin 是一门跨平台语言,Kotlin Compiler 可以将 Kt 源码编译成多个平台的目标代码:JS、JVM 字节码,甚至 LLVM 机器码。但无论编译成何种目标代码,其编译过程都可以分为两个阶段:
- Frontend(编译器前端):对源代码分析得到 AST (抽象语法树)以及符号表,并完成静态检查
- Backend(编译器后端):基于 AST 等前端产物,生成平台目标代码
简而言之:前端负责源码的解析和检查,后端负责目标代码的生成

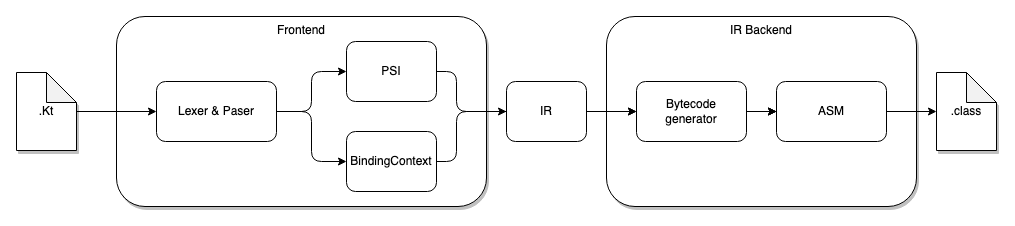
如上,以 Kotlin/JVM 为例:
- Frontend 处理中,Kt 源文件经过词法、语法和语义分析(Lexer&Paser)生成 PSI 以及对应的 BindingContext。
- Backend 处理中,基于 PSI 和 BindingContext 先生成 JVM 字节码,然后通过 ASM 将字节码二进制化生成 class 文件
不同目标平台的编译流程中 Frontend 的处理流程都一样,只是在 Backend 中生成不同的目标代码
K1 编译器:PSI & BindingContext
PSI 全称 Program Structure Interface, 可以将它理解为 JetBrains 专用的 AST(标准 AST 之上有一些扩展)。PSI 可以用于编译过程中的语法静态检查,PSI 也用于 IntelliJ 系列 IDE 的静态检查,我们在编写代码过程中能实时提示语法错误就是靠它。因此 PSI 有助于编译和编写阶段复用静态检查逻辑。我们在开发 IDE Plugin 或者编写 Detekt 静态检查用例时都有机会使用到 PSI。
- PSI: https://plugins.jetbrains.com/docs/intellij/psi-elements.html
- Detekt: https://github.com/detekt/detekt
在 IDE 中通过 PsiViewer 插件可以实时看到源码对应的 PSI,以下面代码为例:
fun main() {println("Hello, World!")
}
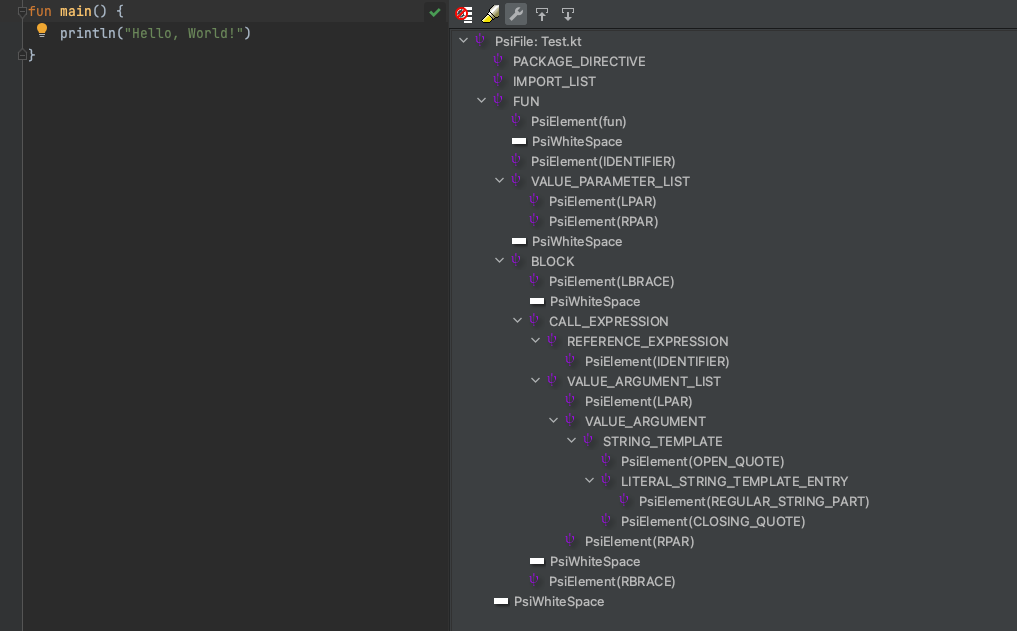
上图是 PsiViewer 中的输出结果,可以看到它体现了以下树形结构:
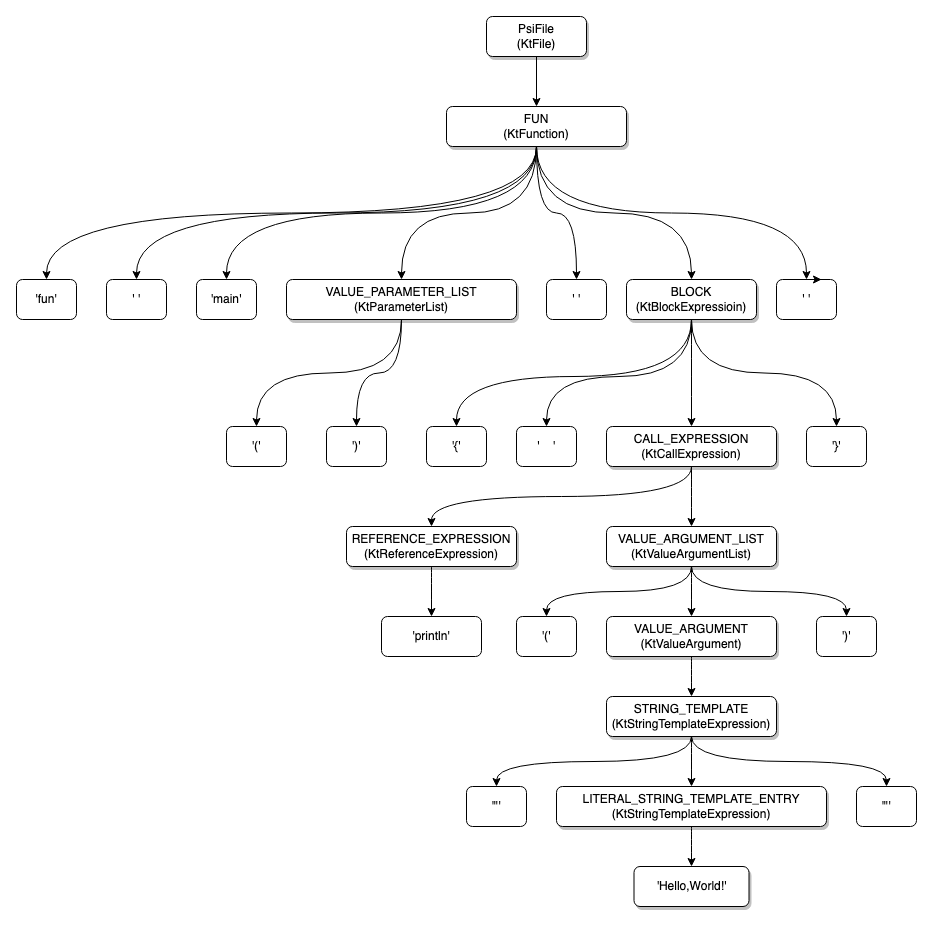
PSI 树的节点是源码经分析后的语法元素,例如一个特殊符号,一个字符串等,这都是一个个 PsiElement。PsiElement 仍然缺少了基于上下文的语义信息,比如对于一个 KtFunction,它的参数信息,修饰符信息等等,这就需要 BindingContext 的辅助了。
BindingContext 相当于 PSI 配套的符号表,PsiElement 经语义分析后得到对应的 Descriptor (描述符)并记录到 BindingContext 中,BindingContext 可以快速索引到 PSI 节点对应的 Descriptor。Descriptor 包含我们需要的语义信息,例如 FunctionDescriptor 可以获取 TypeParameters,isInline 等信息。
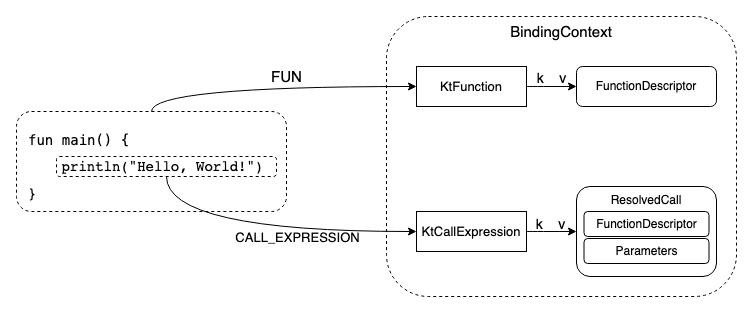
BindingContext 结构类似一个 Map<Type, Map<key, Descriptor> ,第一个 Map 的 key 代表 PSI 节点类型,第二个 Map 的 key 是 PsiElement 实例,Value 是其对应的 Descriptor。KtFunction 为 key 可以获取对应的 FunctionDescriptor;KtCallExpression 获取对应的 ResolvedCall,这里面包含了调用方法的 FunctionDescriptor 以及传入的 Parameters。
K2 编译器:FIR & IR
通过上面的介绍我们知道,Kotlin Compiler 的 Frotend 产物是 PSI 以及 BindingContext,Backend 将基于它们直接输出目标代码。由于 Backend 耦合了目标代码生成逻辑,一些编译期的处理和优化逻辑难以多平台复用。例如我们都知道的 suspend 函数在编译期会生成额外的代码,而我们希望这些 codegen 逻辑得以复用,为此 Kotlin 开发了新一代编译器,取名为 K2 。
K2: https://blog.jetbrains.com/zh-hans/kotlin/2021/10/the-road-to-the-k2-compiler/
K2 编译器的最大特点是引入了 IR(Intermediate Representation,中间表达)。IR 是连接前后端的中间产物, 它与平台无关,类似 suspend 这类编译期优化可以面向 IR 实现并跨平台复用。
K2 中使用新的基于 IR 的 Backend 替代旧有的基于 PSI 和 BindingContext 的 Backend。Kotlin 1.5 开始 Kotlin/JVM 默认启用新的 IR Backend,1.6 开始 Kotin/JS IR Backend 成了标配。下图是引入 IR Backend 的编译流程。
IR 也是一颗树形数据结构,但它的抽象表达更加“低级”,更贴近 CPU 架构。IrElement 带有多种语义信息,例如 FUN 的 visibility,modality 以及 returnType 等等,不必像 PsiElement 那样需要通过查询 BindingContext 获取这些信息。
前面 Hello World 的例子,其对应的 IR 树打印如下:
FUN name:main visibility:public modality:FINAL <> () returnType:kotlin.UnitBLOCK_BODYCALL 'public final fun println (message: kotlin.Any?): kotlin.Unit [inline] declared in kotlin.io.ConsoleKt' type=kotlin.Unit origin=nullmessage: CONST String type=kotlin.String value="Hello, World!"
除了新的 IR Backend,K2 也更新了 Frontend,主要变化是使用 FIR (Frontend IR)替代了 PSI 与 BindingContext。1.7.0 起我们可以使用到 K2 的新前端。

综上可见: K2 相对于 K1 的主要变化引入了 FIR Frontend 和 IR Backend。
IR 可以由 FIR 转化而来,它们都是树型结构,那么这两者又有什么区别呢?可以从以下三个方面进行区分:
| FIR | IR | |
|---|---|---|
| 目标不同 | FIR 整合了 PSI 与 BindingContext 信息,更快速地查找描述符信息,它的首要目标是提升前端静态分析以及检查的性能 | 性能不是 IR 的考虑,它的数据结构的出发点不是为了提升后端编译速度,而是服务于不同后端之间的编译逻辑共享,降低不同平台支持新语言特性的成本 |
| 结构不同 | FIR 仍然是一颗 AST,只是增强了一些符号信息,加速静态分析 | IR 不仅是一颗 AST,它提供了更丰富的基于上下文的语义信息,比如我可以知道某个代码块中的某个变量是临时变量还是成员变量,而 FIR 难以做到 |
| 能力不同 | 虽然 FIR 也可以处理一些简单的脱糖和代码生成工作,但整体上仍然是服务于前端,不能对 AST 大幅度修改 | IR 具有丰富的 Godegen API,可以更加灵活地对树形结构进行 add/remove/update,实现任意编译期的魔改需求 |
KCP(Kotlin Compiler Plugin)
KCP 允许我们在上述 Kotlin 编译过程中,通过增加扩展点以实现各种编译期魔改。Kotlin
的不少语法糖都是基于 KCP 实现的,比如大家熟知的 No-arg、All-open、kotlinx-serialization 等等。
KCP 也可以像 KAPT 那样在编译期进行注解处理,但它相对于 KATP 更具优势:
-
KCP 在 Kotlin 编译过程中进行,而 KAPT 需要在正式编译之前增加额外的预编译环节,因此 KCP 的性能更好。KSP(Kotlin Symbol Processing)也是基于 KCP 实现的,这也是为什么 KSP 的性能更好的原因
-
KAPT 主要是用来生成新代码,难以针对原有代码逻辑做修改。KCP 可以针对 Bytecode 或者 IR 做任意修改,能力更强大。
KCP 的开发步骤
KCP 虽然功能强大但是开发难度较高,开发一个完整的 KCP 要涉及多个步骤:
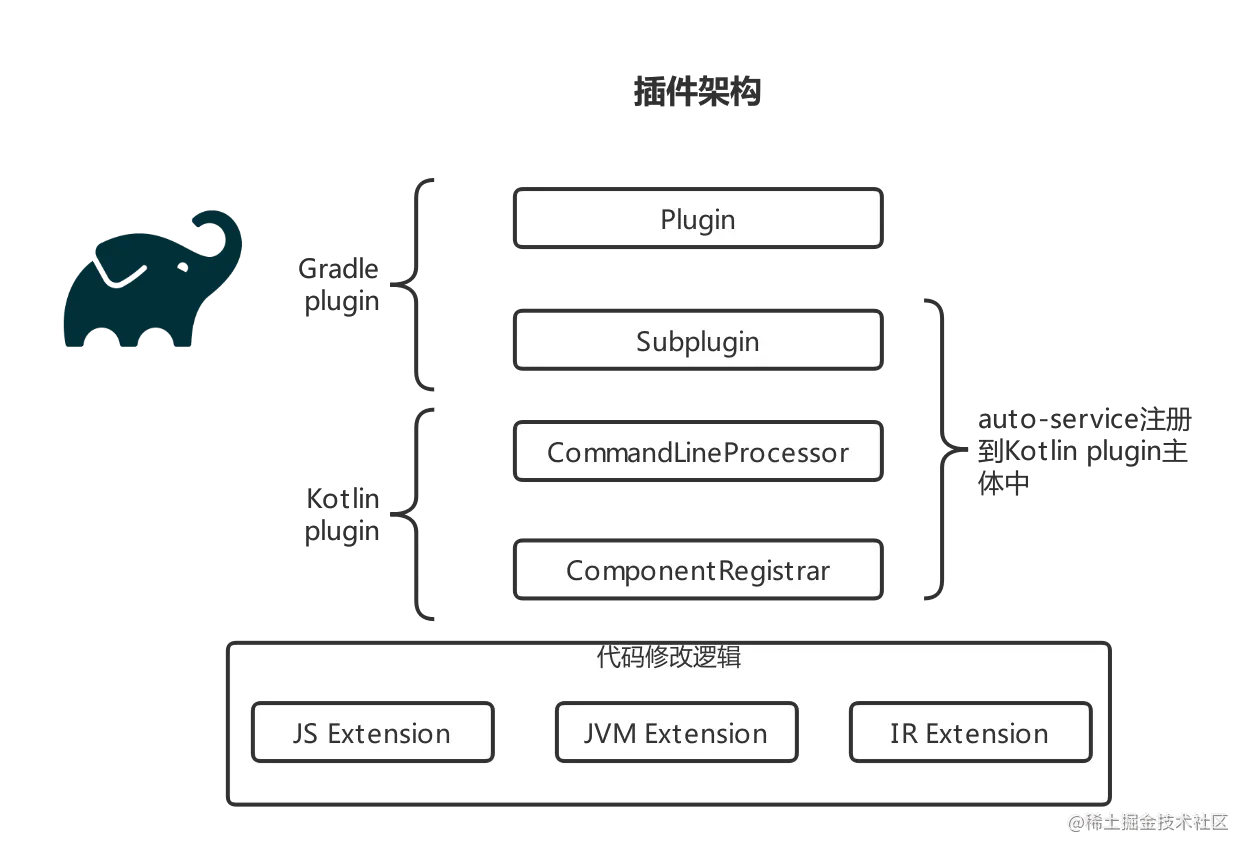
-
Gradle Plugin:
- Plugin:KCP 是通过 Gradle 配置的,需要定义一个 Gradle 插件,并在 Gradle 中配置 KCP 所需的编译参数。
- Subplugin: 建立从 Gradle Plugin 到 Kotlin Plugin 的连接,并将 Gradle 中配置的参数传递给 Kotlin Plugin
-
Kotlin Plugin:
- CommandLineProcessor:KCP 的入口,定义 KCP 的 id、解析命令行参数等
- ComponentRegister:注册 KCP 中的 Extension 扩展点。它与 CommandLineProcessor 一样都是通过 SPI 调用,需要添加 auto-service 注解
- XXExtension:这是实现 KCP 逻辑的地方。Kotlin 提供了许多类型的 Extension 供我们实现。编译器会在前端、后端的各个编译环节中调用 KCP 注册的对应类型的 Extension。例如 ExpressionCodegenExtension 可用来修改 Class 的 Body;ClassBuilderInterceptorExtension 可以修改 Class 的 Definition 等等
随着 Kotlin Compiler 从 K1 升级到 K2,KCP 也提供了面向 K2 的 Extension。
以 No-arg 为例 ,No-arg 通过为 Class 添加注解自动生成无参构造函数。No-arg 源码中存在 K1、K2 两套 Extension,可以兼容不同 Kotlin 版本的使用:
- No-arg: https://kotlinlang.org/docs/no-arg-plugin.html
- source:https://cs.android.com/android-studio/kotlin/+/master:plugins/noarg/
-
NoArg K1:
- CliNoArgDeclarationChecker:NoArg 不能作用于 Inner Class,这里使用基于 PSI 的前端检查逻辑检查是否是 Inner Class
- CliNoArgExpressionCodegenExtension:继承自 ExpressionCodegenExtension,基于 PSI 和对应的 Descriptor 以 JVM 字节码的形式在 Class Body 中添加无参构造函数
-
NoArg K2:
- FirNoArgDeclarationChecker:新的 K2 前端,可基于 FIR 检查 InnerClass
- NoArgIrGenerationExtension:继承自 IrGenerationExtension ,基于 IR 添加无参构造函数
以 Backend Extension 为例,体会以下具体实现上的区别:
- CliNoArgExpressionCodegenExtension 中的处理:
// 1. 基于 descriptor 获取 class 信息
val superClassInternalName = typeMapper.mapClass(descriptor.getSuperClassOrAny()).internalName
val constructorDescriptor = createNoArgConstructorDescriptor(descriptor)
val superClass = descriptor.getSuperClassOrAny()// 2. 通过 Codegen 直接生成无参构造函数对应的字节码
functionCodegen.generateMethod(JvmDeclarationOrigin.NO_ORIGIN, constructorDescriptor, object : CodegenBased(state) {override fun doGenerateBody(codegen: ExpressionCodegen, signature: JvmMethodSignature) {codegen.v.load(0, AsmTypes.OBJECT_TYPE)if (isParentASealedClassWithDefaultConstructor) {codegen.v.aconst(null)codegen.v.visitMethodInsn(Opcodes.INVOKESPECIAL, superClassInternalName, "<init>","(Lkotlin/jvm/internal/DefaultConstructorMarker;)V", false)} else {codegen.v.visitMethodInsn(Opcodes.INVOKESPECIAL, superClassInternalName, "<init>", "()V", false)}if (invokeInitializers) {generateInitializers(codegen)}codegen.v.visitInsn(Opcodes.RETURN)}
})
- NoArgIrGenerationExtension 中的处理:
// 1. 基于 IrClass 获取 Class 信息
val superClass =klass.superTypes.mapNotNull(IrType::getClass).singleOrNull { it.kind == ClassKind.CLASS }?: context.irBuiltIns.anyClass.owner
val superConstructor =if (needsNoargConstructor(superClass))getOrGenerateNoArgConstructor(superClass)else superClass.constructors.singleOrNull { it.isZeroParameterConstructor() }?: error("No noarg super constructor for ${klass.render()}:\n" + superClass.constructors.joinToString("\n") { it.render() })// 2. 基于 irFactory 等 IR API 创建构造函数
context.irFactory.buildConstructor {startOffset = SYNTHETIC_OFFSETendOffset = SYNTHETIC_OFFSETreturnType = klass.defaultType
}.also { ctor ->ctor.parent = klassctor.body = context.irFactory.createBlockBody(ctor.startOffset, ctor.endOffset,listOfNotNull(IrDelegatingConstructorCallImpl(ctor.startOffset, ctor.endOffset, context.irBuiltIns.unitType,superConstructor.symbol, 0, superConstructor.valueParameters.size),IrInstanceInitializerCallImpl(ctor.startOffset, ctor.endOffset, klass.symbol, context.irBuiltIns.unitType).takeIf { invokeInitializers }))
}
NoArgIrGenerationExtension 是一个 IrGenerationExtension,这是专门用来更新 Ir 的扩展点,可以看到里面已经没有了对字节码的操作,取而代之使用 IR 中的各种 buildXXX API。
Compose Compiler 的代码生成也是依靠 IrGenerationExtension 实现的,所以:即使最早版本的 Compose 也要求 Kotlin 版本大于 1.5.10,就是因其 Compiler 只支持 IR Backend Extension。
Compose Compiler
Compose Compiler 本质上是一个 KCP,在了解了 KCP 的基本构成之后,我们知道 Compose Compiler 的核心在于 Extension
Compose Compiler: https://cs.android.com/androidx/platform/frameworks/support/+/androidx-main:compose/compiler/compiler-hosted/
直接找到 ComposeComponentRegistrar,查看注册了哪些 Extension:
class ComposeComponentRegistrar : ComponentRegistrar {//...StorageComponentContainerContributor.registerExtensioproject,ComposableCallChecker())StorageComponentContainerContributor.registerExtensioproject,ComposableDeclarationChecker())StorageComponentContainerContributor.registerExtensioproject,ComposableTargetChecker())ComposeDiagnosticSuppressor.registerExtension(project,ComposeDiagnosticSuppressor())@Suppress("OPT_IN_USAGE_ERROR")TypeResolutionInterceptor.registerExtension(project,@Suppress("IllegalExperimentalApiUsage")ComposeTypeResolutionInterceptorExtension())IrGenerationExtension.registerExtension(project,ComposeIrGenerationExtension(configuration = configuration,liveLiteralsEnabled = liveLiteralsEnabled,liveLiteralsV2Enabled = liveLiteralsV2EnabledgenerateFunctionKeyMetaClasses = generateFuncsourceInformationEnabled = sourceInformationEintrinsicRememberEnabled = intrinsicRememberEdecoysEnabled = decoysEnabled,metricsDestination = metricsDestination,reportsDestination = reportsDestination,))DescriptorSerializerPlugin.registerExtension(project,ClassStabilityFieldSerializationPlugin())//...
}
- ComposableCallChecker:检查是否可以调用 @Composable 函数
- ComposableDeclarationChecker:检查 @Composable 的位置是否正确
- ComposeDiagnosticSuppressor:屏蔽不必要的编译诊断错误
- ComposeIrGenerationExtension:负责 Composable 函数的代码生成
- ClassStabilityFieldSerializationPlugin:分析 Class 是否稳定,并添加稳定性信息
这里的各种 Checker 是 Frontend Extension ,目前仍然是基于 K1 实现的,而位于 Backend 的 ComposeIrGenerationExtension 则面向 K2,这也是 Compose 代码生成的核心,会在本系列的后续文章中重点介绍。
参考
-
Writing Your First Kotlin Compiler Plugin
https://resources.jetbrains.com/storage/products/kotlinconf2018/slides/5_Writing%20Your%20First%20Kotlin%20Compiler%20Plugin.pdf -
Kotlin Compiler Internals In 1.4 and beyond
https://docs.google.com/presentation/d/e/2PACX-1vTzajwYJfmUi_Nn2nJBULi9bszNmjbO3c8K8dHRnK7vgz3AELunB6J7sfBodC2sKoaKAHibgEt_XjaQ/pub?slide=id.g955e8c1462_0_190