凡科建站官网登重庆seo务
【Unity入门】MonoBehaviour事件函数
大家好,我是Lampard~~
欢迎来到Unity入门系列博客,所学知识来自B站阿发老师~感谢

(一)常用的事件函数
(1)start和update方法
之前我们写的脚本,会默认帮助我们继承于MonoBehaviour类,MonoBehaviour是unity的一个基类,类似于cocos的object
MonoBehaviour是Unity引擎中的一个基类,用于编写游戏对象的脚本,开发者可以通过继承MonoBehaviour类并实现其中的方法来实现游戏对象的交互行为和游戏机制
默认创建的C#脚本会自带两个方法,分别是start和update。我们通知之前的使用知道,start是脚本初始化时候会被调用一次,update会每帧进行调用,而游戏的帧率我们可以通过Application.targetFrameRate来进行设置

这两个方法我们很熟悉,下面会介绍其他三种常见的事件函数
(2)awake方法
Awake方法是MonoBehaviour类中的一个回调方法,在游戏对象被创建时调用,用于初始化游戏对象的属性和状态,在Start方法之前执行
Awake方法的作用一般是进行游戏对象的初始设置,例如获取其他组件的引用、初始化变量、设置默认参数等。在Awake方法中进行这些初始化设置可以保证在Start方法之前完成,从而避免在Start方法中出现未初始化的情况
从上文得知,Awake和Start类似都是会执行一次进行初始化使用。它们的区别在于,Awake在Start之前调用,且哪怕物体是禁用状态,Awake也会执行
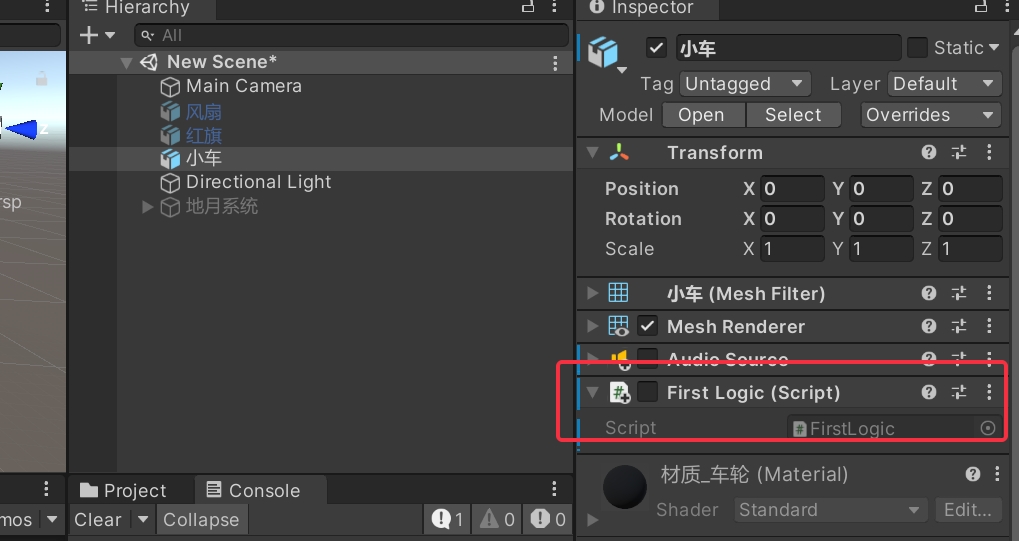
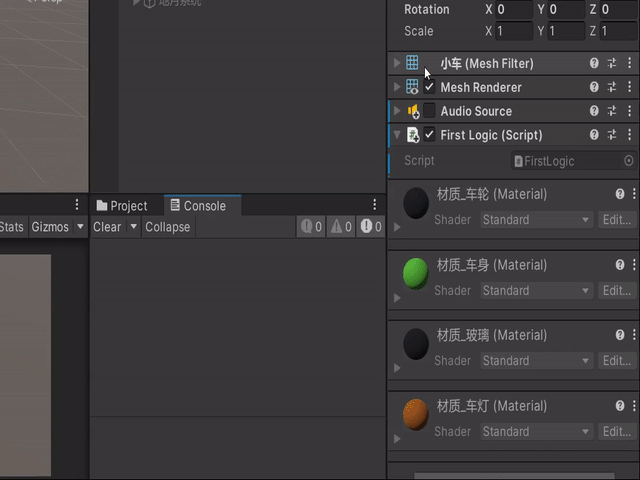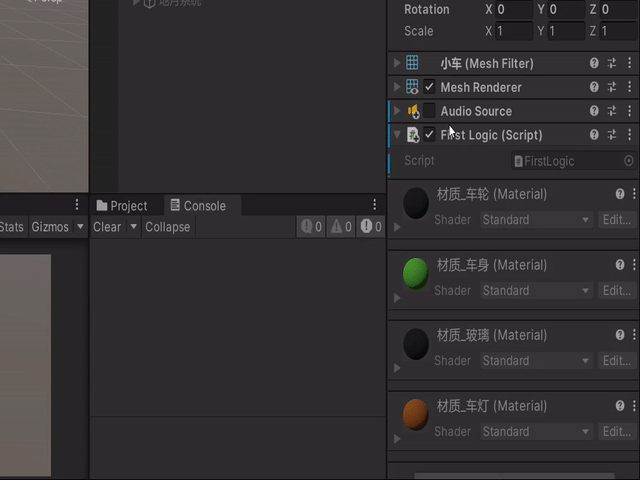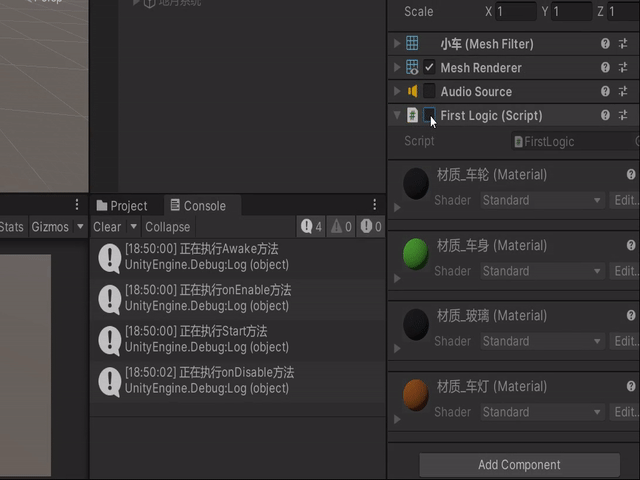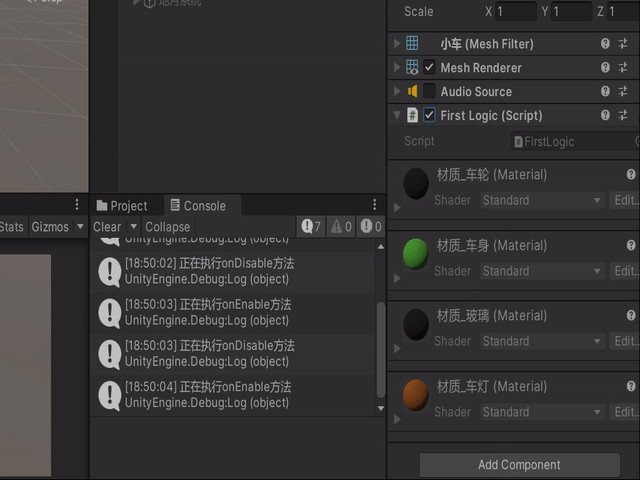
比如小车物体挂载了FirstLogic脚本,我们现在把代码设置禁用状态,设置如下代码
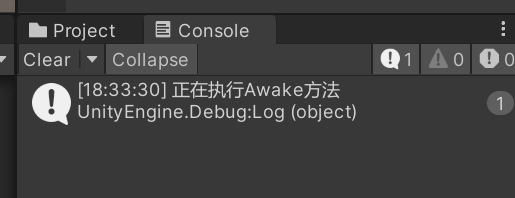
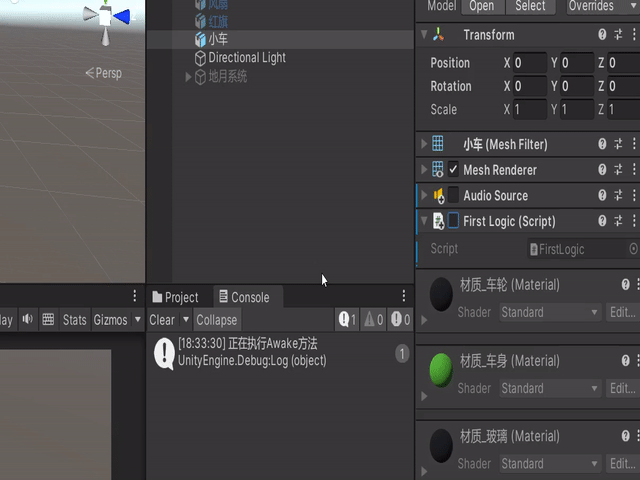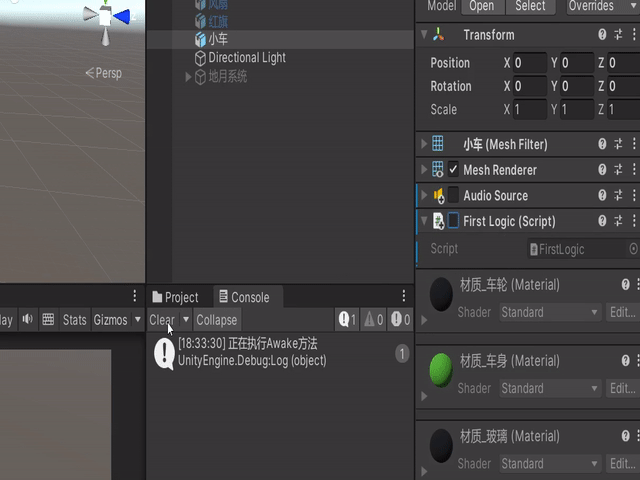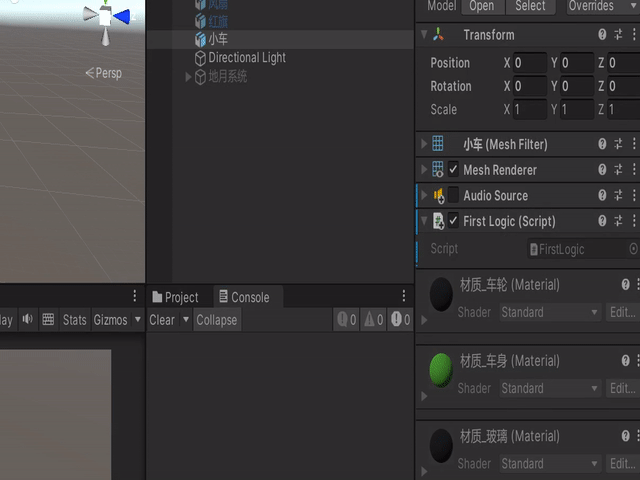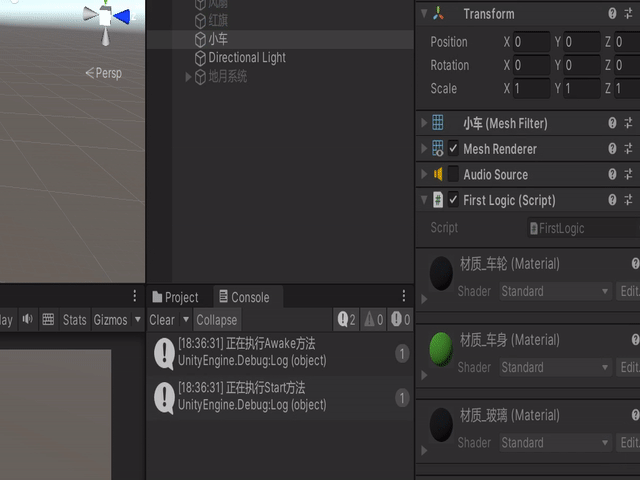
void Awake(){Debug.Log("正在执行Awake方法");}void Start(){Debug.Log("正在执行Start方法");}看看执行结果:
如果我们把代码的勾选项勾上呢,就会出现Awake先比sStart执行的结果
(3)onEnable方法和onDisable方法
onEnable和onDisable方法会分别在脚本启用和禁用的时候调用
需要注意的是,onEnable方法和onDisable方法在游戏对象的生命周期中可能会多次被调用,因此在实现时需要注意避免重复注册和清理等情况

举个栗子,我们加上以下代码:
private void Awake(){Debug.Log("正在执行Awake方法");}private void onEnable(){Debug.Log("正在执行onEnable方法");}private void onDisable(){Debug.Log("正在执行onDisable方法");}void Start(){Debug.Log("正在执行Start方法");}看看结果,只要物体被调用/禁用的时候代码就会执行:
好啦今天就到这里,感谢阅读!!!
点赞,关注!!!
