智慧团建网站入口pc端浙江杭州软件公司排名

前言
为了模拟各种P6测试,我常常会安装各种不同版本的p6系统,无论是P6服务,亦或是P6客户端工具Professional,在今天操作p6使用时,无意识到安装在本地的P6 数据库(21.12)出现了与Professional软件版本(22.12)不匹配问题,由此记录下我解决该问题的过程。
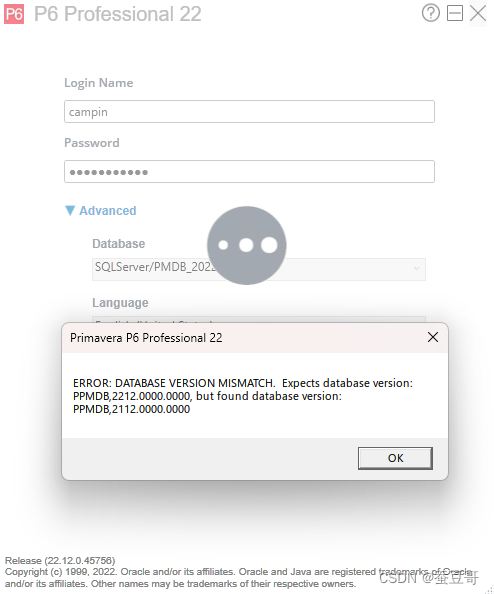
要解决以上问题无非两种思路,但我总不走寻常路,选择了第二种。
- 重新降级安装Professional 22.12 > 21.12
- 升级P6数据库 21.12 > 22.12
解决方案
在此之前先要确定自己的详细版本,是否是企业版(即EPPM还是PPM)
好在检查之后,得到的结果是PPMDB ,21,12 ..... 及PPM,没有企业WEB应用套件
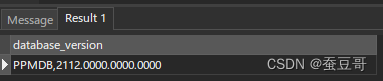
作为对比,我拿出其他平台安装的安装EPPM,结果是PMDB打头

鉴于数据安全的需要,请在执行修改数据库前及时做好备份工作
确认是PPM应用后,我找到了 PPM 22.12 套件应用程序,需要说明的是,在2020年后,Oracle已将 Database程序包已不作为Professional Application的一部分,必须是单独获取,这里解压了V1032888
选择安装P6数据库的应用程序 dbsetup,选择如下的安装选项 > 升级已存在的数据库
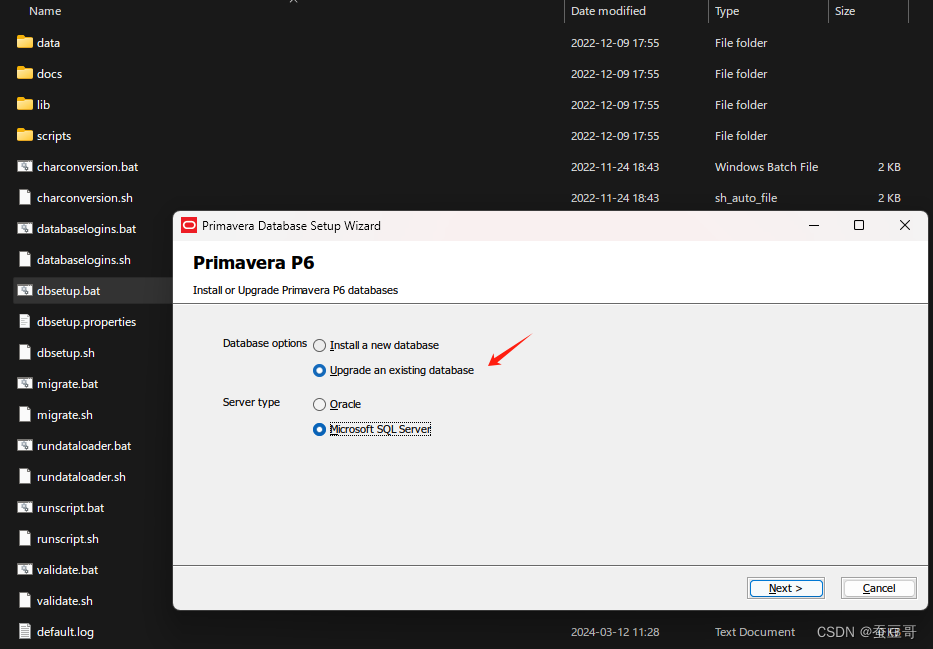
以上升级的数据库是MSSSQL,因此数据库服务的类型是 Mcroserver SQL Server,如果是Oracle Dtatabase,请选择Oracle即可
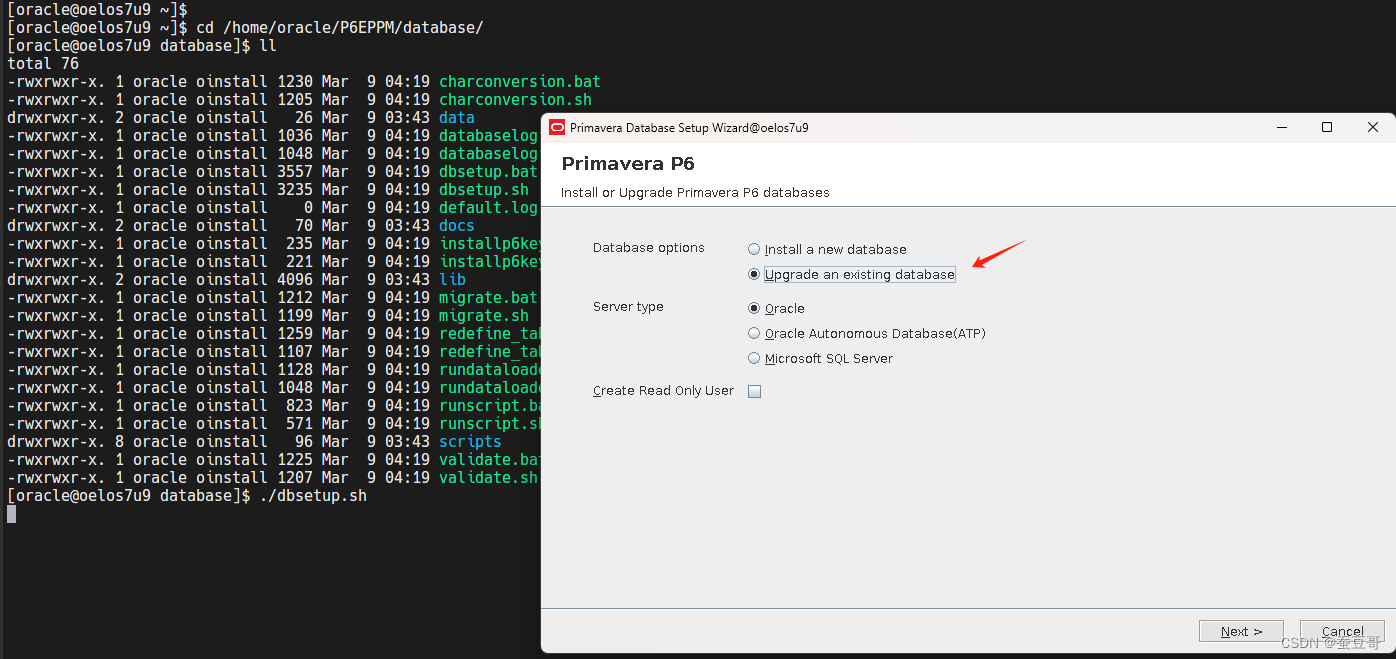
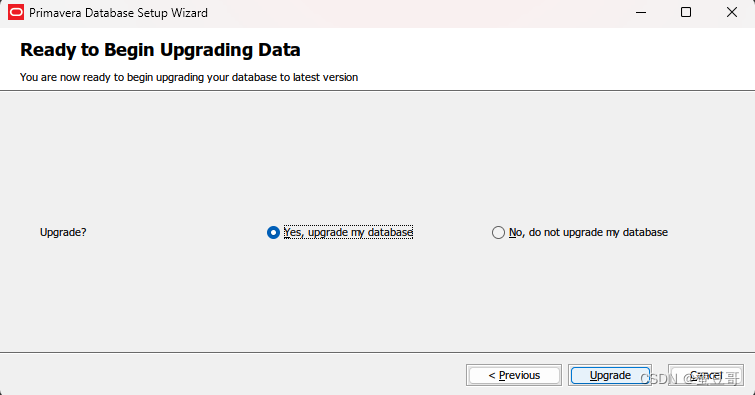
输入连接信息后,下一步,确认升级即可,整个过程很快,一会便完成
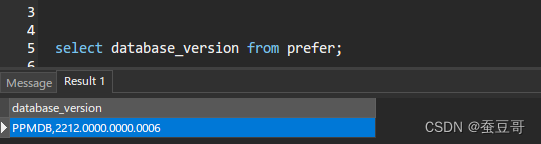
再次检验数据表版本,可以看到,其版本值已更新到PPM的22.12
接下来重新退回到P6 Professional操作登录即可。