源码网站代理深圳网站设计公司排名前十强
提到的C++、数据结构与算法、操作系统、计算机网络和数据库技术等确实是计算机科学中非常重要的基础知识领域,对于软件开发和计算机工程师来说,它们是必备的核心知识。掌握这些知识对于开发高性能、可靠和安全的应用程序非常重要。
Python作为一种脚本语言,在某些场景下确实可以作为加分项或辅助工具使用。它具有易学易用的特点,并且在数据处理、科学计算、机器学习等领域具有广泛的应用。对于一些快速原型开发、数据分析和自动化脚本等任务,Python可以提高开发效率。
然而,选择学习哪些技术和语言取决于你的个人兴趣、职业目标和所在行业的需求。如果你对C++后台开发感兴趣,并且想在该领域深入发展,那么深入学习C++、数据结构与算法、操作系统等是很重要的。同时,也要根据具体岗位要求和行业趋势来补充其他相关技术,如计算机网络和数据库技术。
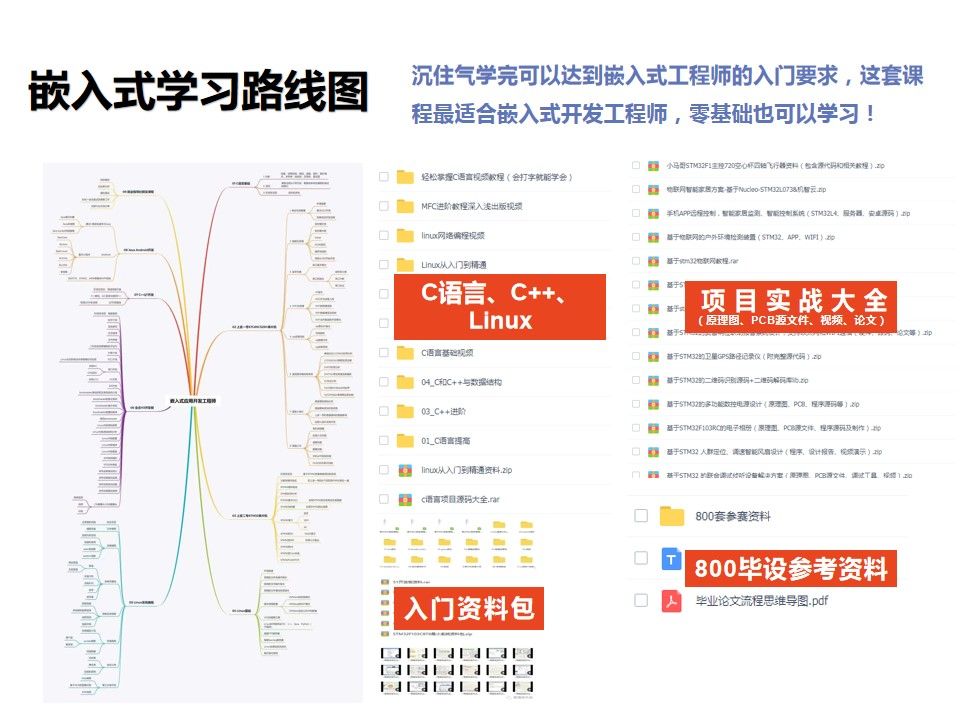
面试准备确实需要通过了解面试问题、面试经验和实际工作经验来提升自己的技能。每个人的情况和面试要求都有所不同,因此需要根据自己的实际情况进行有针对性的准备。刚好,我这里有上位机入门,学习线路图,各种项目,需要留个6。不断学习和提升自己的技能,扩展自己的知识广度和深度,对于在面试和工作中更好地展示自己的能力是非常重要的。
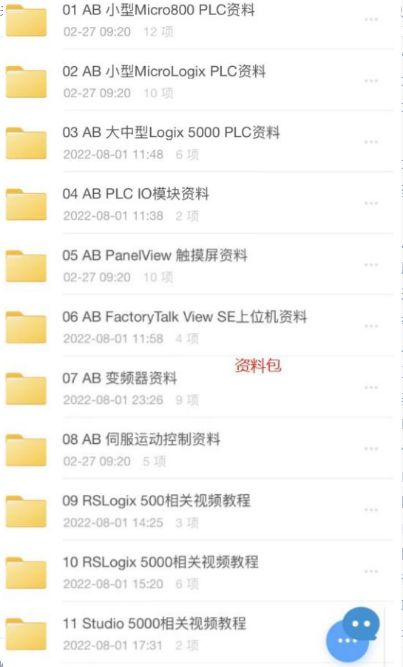
正好看我这一套保姆式嵌入式休息资料,里面包含了编程教学、数据处理、毕设800套和语言类教学,非常的全面、放下一个6,免费发给你。