怎样用自己的服务器做网站自已建设网站流程
流媒体播放器EasyPlayer是TSINGSEE青犀流媒体组件系列中关注度较高的产品,经过多年的发展和迭代,目前已经有多个应用版本,包括RTSP版、RTMP版、Pro版,以及js版,其中js版本作为网页播放器,受到了用户的广泛使用。在功能上,EasyPlayer支持直播、点播、录像、快照截图、MP4播放、多屏播放、倍数播放、全屏播放等特性,具备较高的可用性和稳定性。为了便于用户集成与调用,我们也提供了API接口供大家使用。
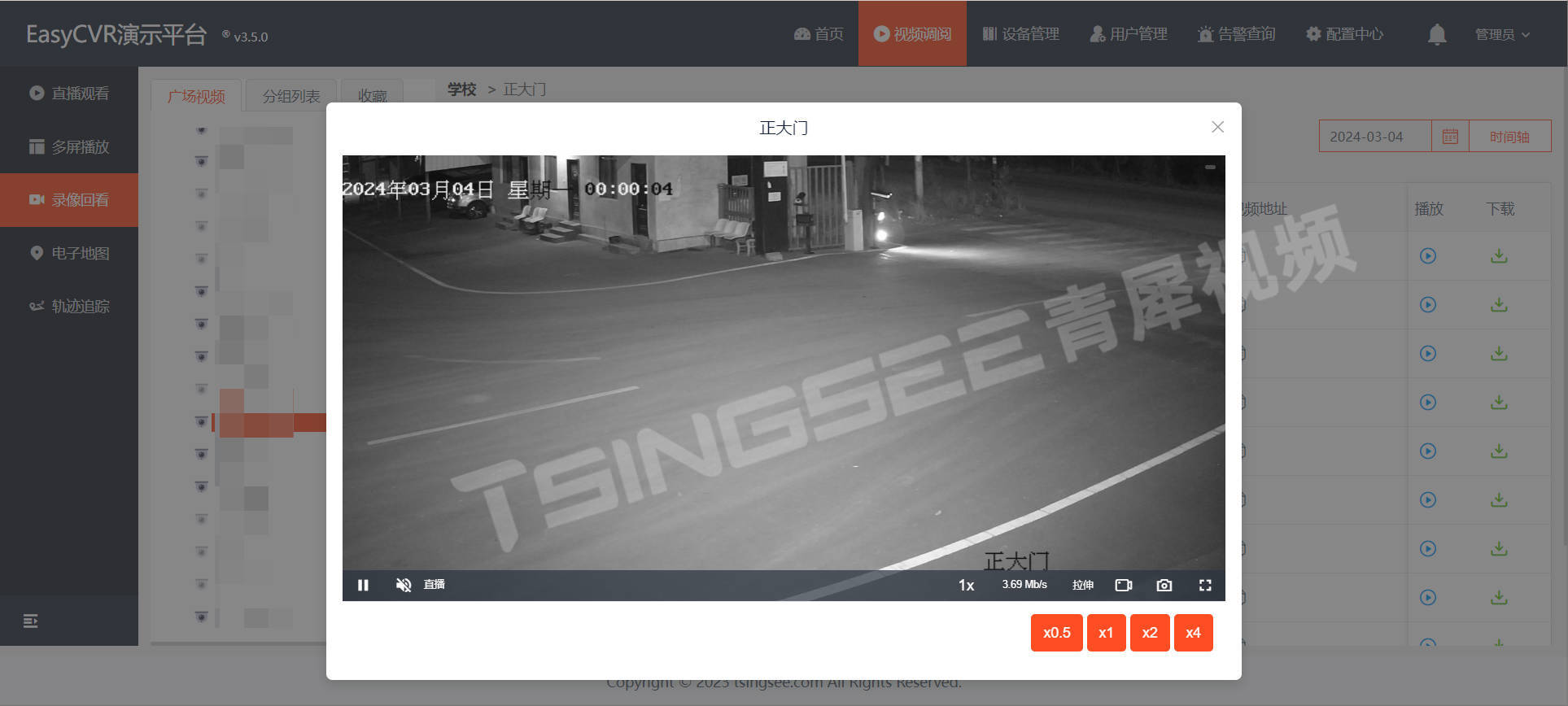
我们在此前的文章中介绍了如何在uniapp框架中集成H.265流媒体视频播放器EasyPlayer.js,感兴趣的用户可以翻阅我们往期的文章进行了解。
今天我们来介绍一下在Uniapp真机中,如何使用无插件流媒体EasyPlayer播放器呢?
因为在uniapp真机中,并不支持document,所以需要通过renderjs实现。

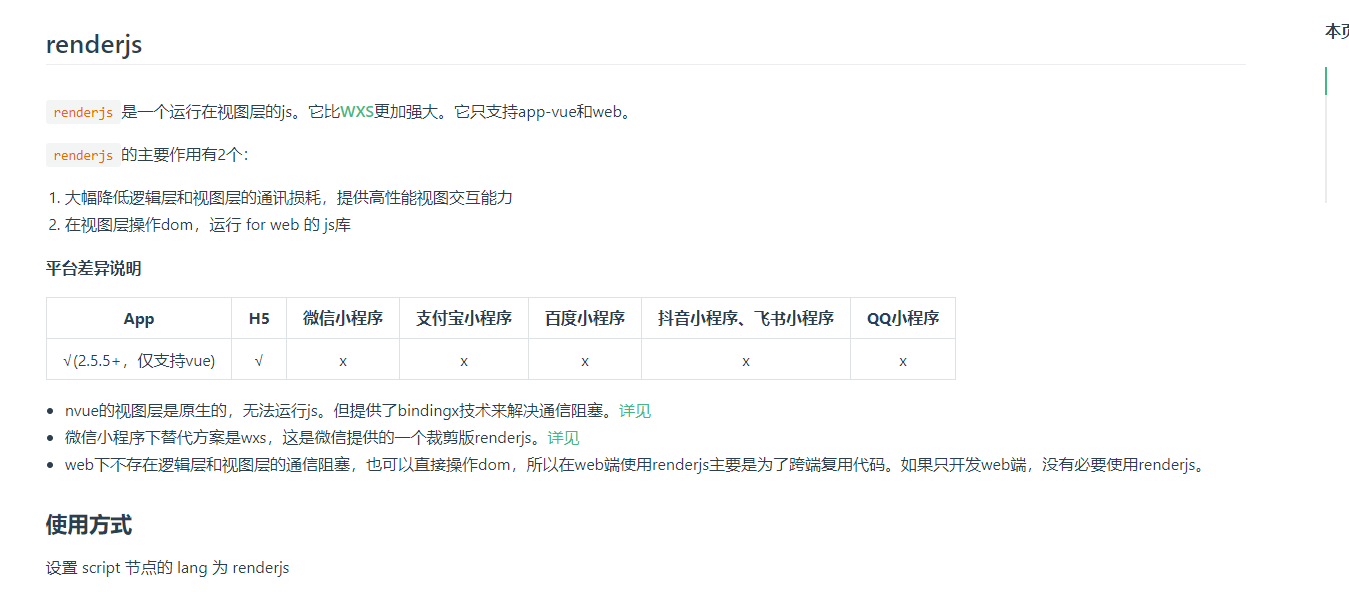
主要代码如图,更多的renderjs使用方法查看官网文档:
renderjs官方文档:https://uniapp.dcloud.net.cn/tutorial/renderjs.html#%E7%A4%BA%E4%BE%8B
注意事项
- 目前仅支持内联使用。
- 不要直接引用大型类库,推荐通过动态创建script方式引用。
- 可以使用vue组件的生命周期(不支持beforeDestroy、destroyed、beforeUnmount、unmounted),不可以使用App、Page的生命周期。
- 视图层和逻辑层通讯方式与WXS一致,另外可以通过this.$ownerInstance获取当前组件的ComponentDescriptor实例。
- 注意逻辑层给数据时最好一次性给到渲染层,而不是不停从逻辑层向渲染层发消息,那样还是会产生逻辑层和视图层的多次通信,还是会卡。
- 观测更新的数据在视图层可以直接访问到。
- APP端视图层的页面引用资源的路径相对于根目录计算,例如:./static/test.js。
- APP端可以使用dom、bomAPI,不可直接访问逻辑层数据,不可以使用uni相关接口(如:uni.request)。
- H5端逻辑层和视图层实际运行在同一个环境中,相当于使用mixin方式,可以直接访问逻辑层数据。
- vue3项目不支持setupscript用法。
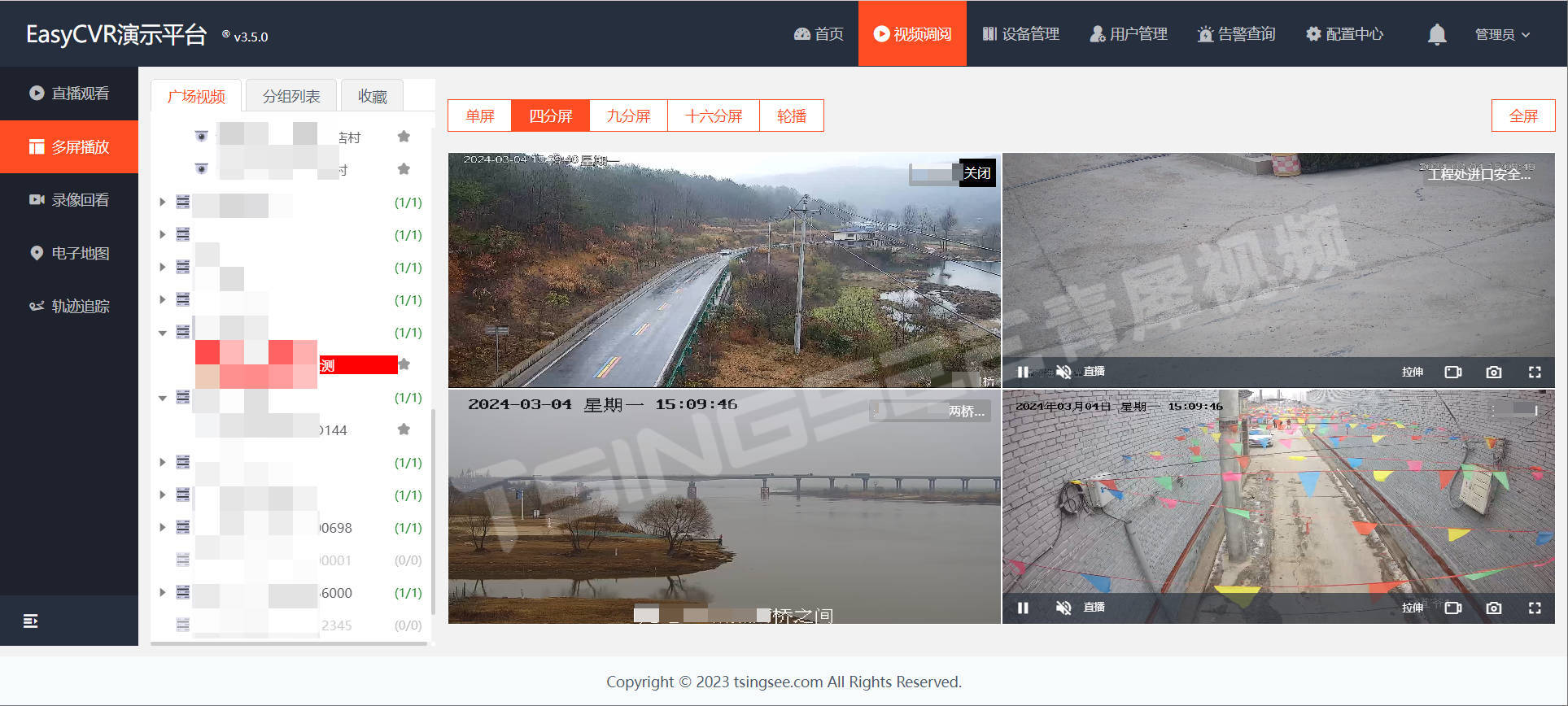
EasyPlayer播放器支持WebSocket-FLV、HTTP-FLV,HLS(m3u8)、WebRTC等格式的视频流,能支持H.264与H.265编码格式,性能稳定、播放流畅,感兴趣的用户可以自行下载测试。