番禺网站排名优化公司网站建设开发报告论文
前边我们提过,免费的数据一般来自于爬虫,获取难度和维护成本都比较高,其实不太适合小白用户。所以非必要情况下,我们尽量不用这种方式来获取数据。

我自己用的比较多的是tushare,一般来说有它也就够了,大概500块钱就可以开通绝大多数常用的权限,很多时候我懒得自己写爬虫,实在是因为花费那么多时间去写脚本和维护,这些时间成本都远远不止500块了。
我们做量化,应该把最多的精力放到投研上,其他环节怎么方便、稳定怎么来。当然,有些数据可能tushare没有或者更新不及时,那么我们用爬虫来抓一下也是有必要的。
今天我们的目标是写一个脚本,把A股的股票列表和基本信息拿到,写入到我们的数据库中,然后再配置一个每天更新的定时任务。
一、获取股票基本信息
从交易所用爬虫抓取数据会比较麻烦,所以这里我们用tushare提供的数据接口来获取股票的基本信息。从下图可以看到,这里提供的信息已经是比较全了。
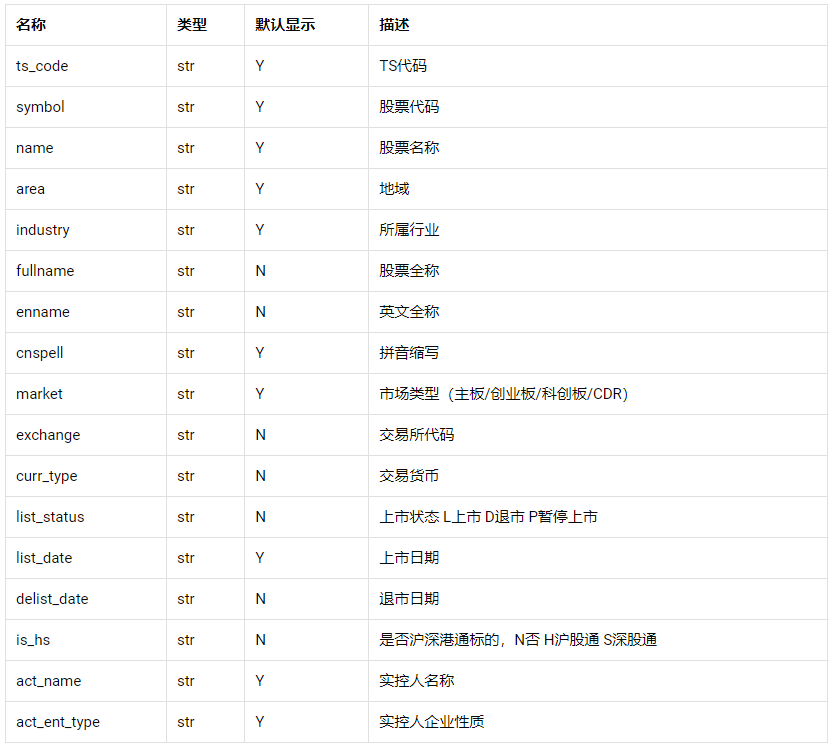
考虑我们是维护一个本地数据库长期来用,所以我们最好还是把所有字段都抓取下来。另外为了避免在回测时出现问题,我们把历史退市的股票也加进来。
如果你是第一次使用tushare,那么可以像我这样写代码。

然后我们打印出来看下数据情况。
可以看到,一共有5637行数据,有些公司在部分字段存在缺失,不过都被我们填充为空字符串了,不会影响我们往数据库里写入。
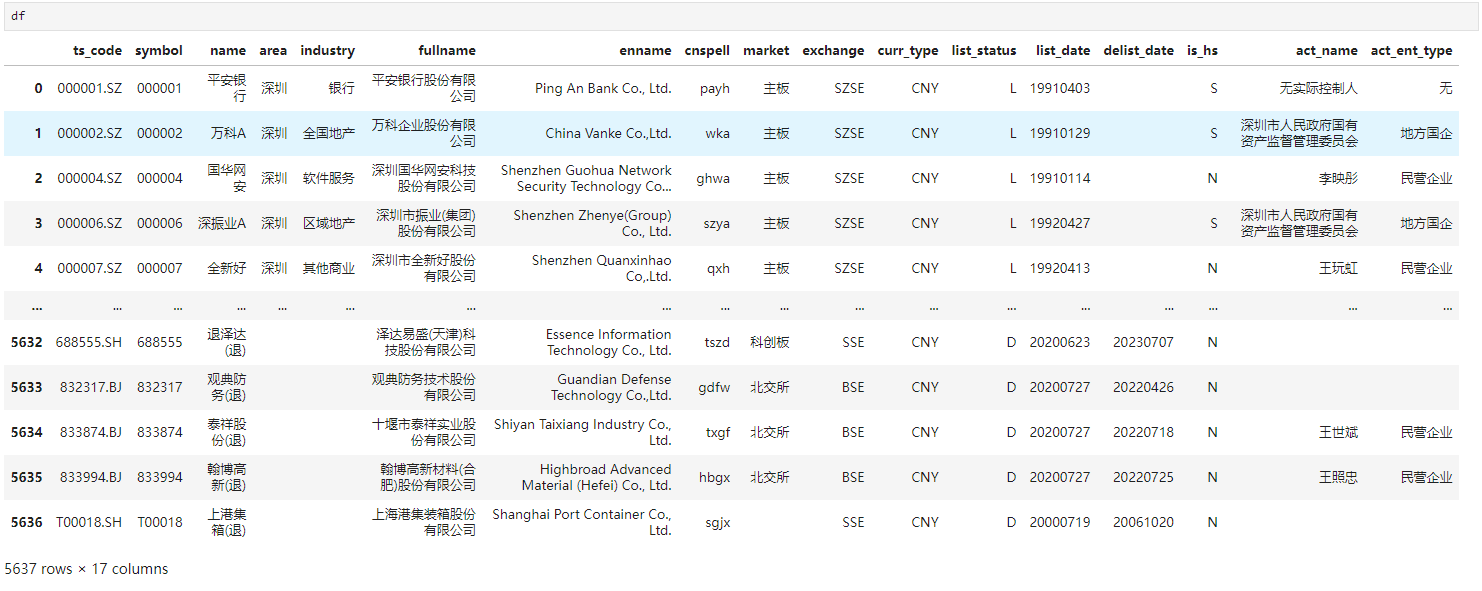
二、基本探查
首先我们可以看到A股历史上有286家退市股,目前仍有5351家公司在正常上市状态。
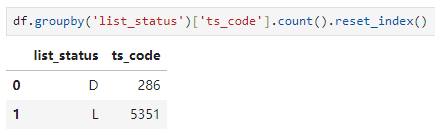
然后我们看到这里把所有仍在上市的公司划分到了111个行业中,其中公司数量最多的五个行业分别是电气设备、元器件、软件服务、专用机械和化工原料。
上市公司数量排名前五的省级地区分别是浙江、江苏、北京、广东和上海。南北差异可以说是极大了。
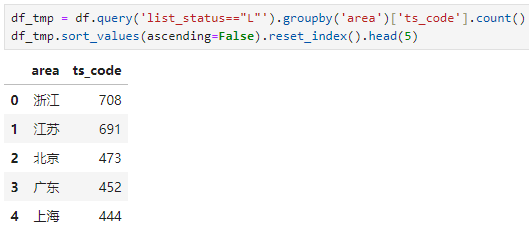
沪深主板股票数量最多,达到3173家,之后是创业板、科创板和北交所。
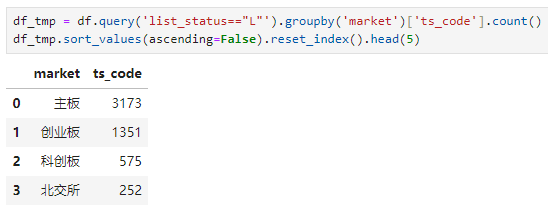
深交所股票2833家,上交所股票2266家,北交所252家。
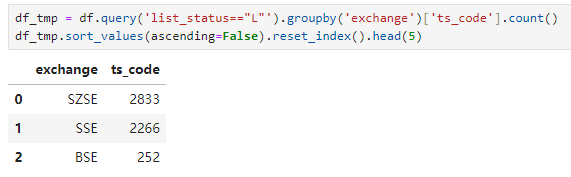
有1434家股票是深港通标的,1342家股票是沪港通标的。
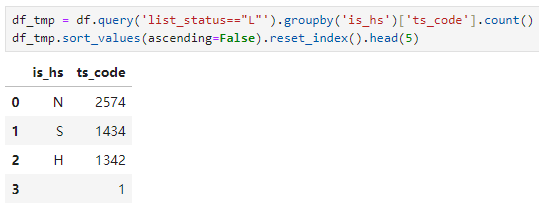
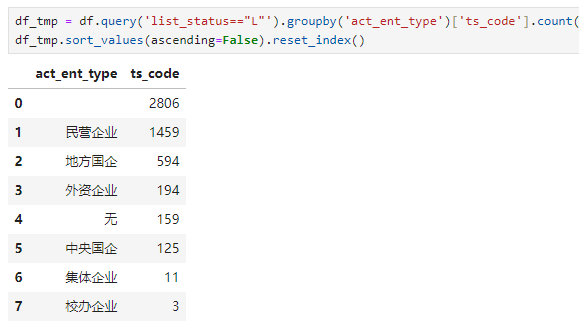
有2806家公司没有标识企业类型。除此之外,1459家民营企业占大头,地方国企594家其次。外资企业有194家,央企有125家。
三、创建数据表
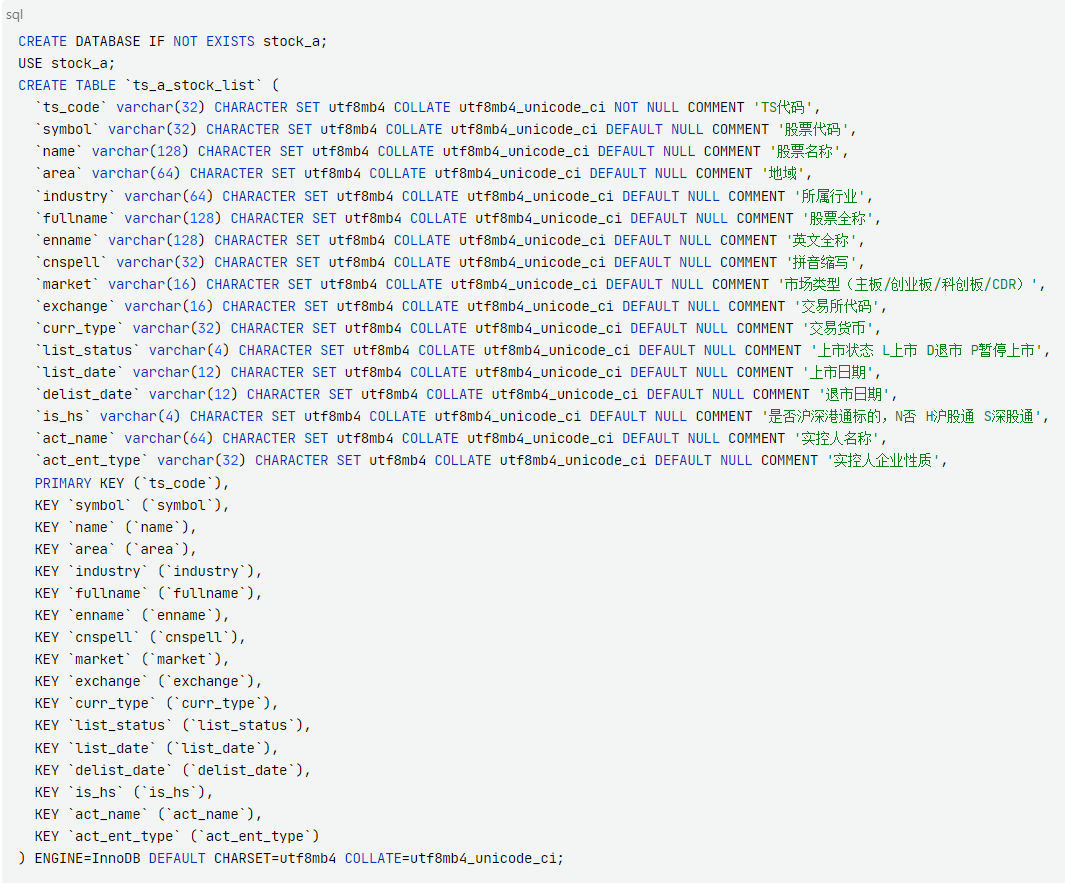
我们连接上在前边几节课中创建好的MySQL实例,然后在命令行中执行如下语句,把数据表创建好。
这里我先创建了一个数据库叫stock_a,然后又在这个数据库下边创建了一张表叫ts_a_stock_list,用来存储我们刚才获取到的数据。
这里老Q用的是自己搭建的DBGate工具来执行SQL,大家也可以选择自己喜欢的工具,比如官方提供的MySQL WorkBench、Navicat等,也可以直接在命令行中执行。如果有不懂的朋友,可以留言或者私信咨询老Q。
实际上,我们在Python中也可以执行这个语句,但是为了不给大家引入新的困难,我们先不讲这个方式。
四、写入数据
这里我们要编写两个函数,分别用于获取MySQL连接对象以及向MySQL中写入数据。如果没有特殊要求,就用老Q的代码就行,只需要根据你的实际情况调整下MySQL的访问IP、端口以及用户和密码。
写函数之前我们记得先把用到的库给导入进来。



然后我们执行下述代码:

可以看到如下输出,这就代表写入成功了。
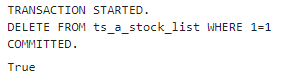
打开我们的数据库管理工具,也能看到的确有数据了,好了,第一次写入就搞定了,是不是还挺简单的?
五、写数据更新脚本
首先我们创建一个文件夹,起名叫tushare_data,用来存储所有我们获取tushare数据的脚本。
然后我们把刚才编写的get_mysql_con和write_to_db两个函数写入一个名为tools.py的文件中,这样以后我们就可以直接导入它来使用了,不需要每次都复制粘贴。然后我们再创建一个新的函数get_ts_api,用来获取token。

接下来我们在同一个目录下创建一个新的文件夹,起名叫stock_a,用来存储A股相关的数据脚本,然后在这个目录中创建一个Python文件,起名ts_a_stock_list.py,和我们的表名保持一致,这样未来会比较好管理。
然后我们在这个文件中写入如下代码,记得把数据库相关信息像上边一样结合自己实际情况调整。

六、配置定时任务
这里我以青龙面板为例,如果你的系统是Windows,可以参考上一节课的内容来配置。
我们按照如下顺序,把刚才提到的文件夹和脚本都创建好。
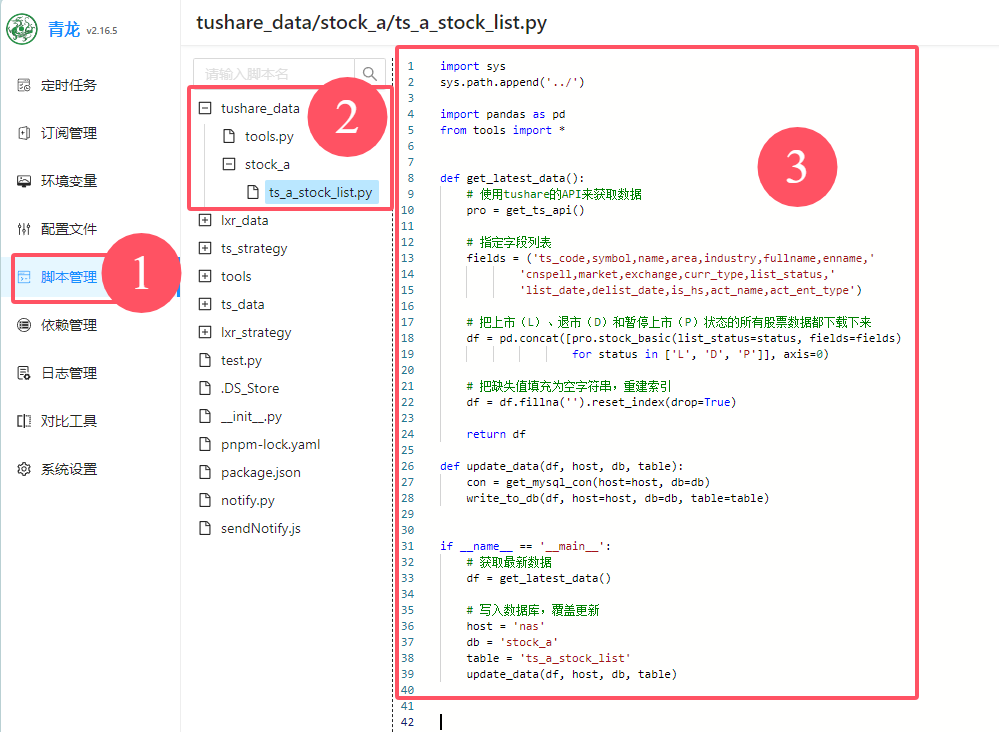
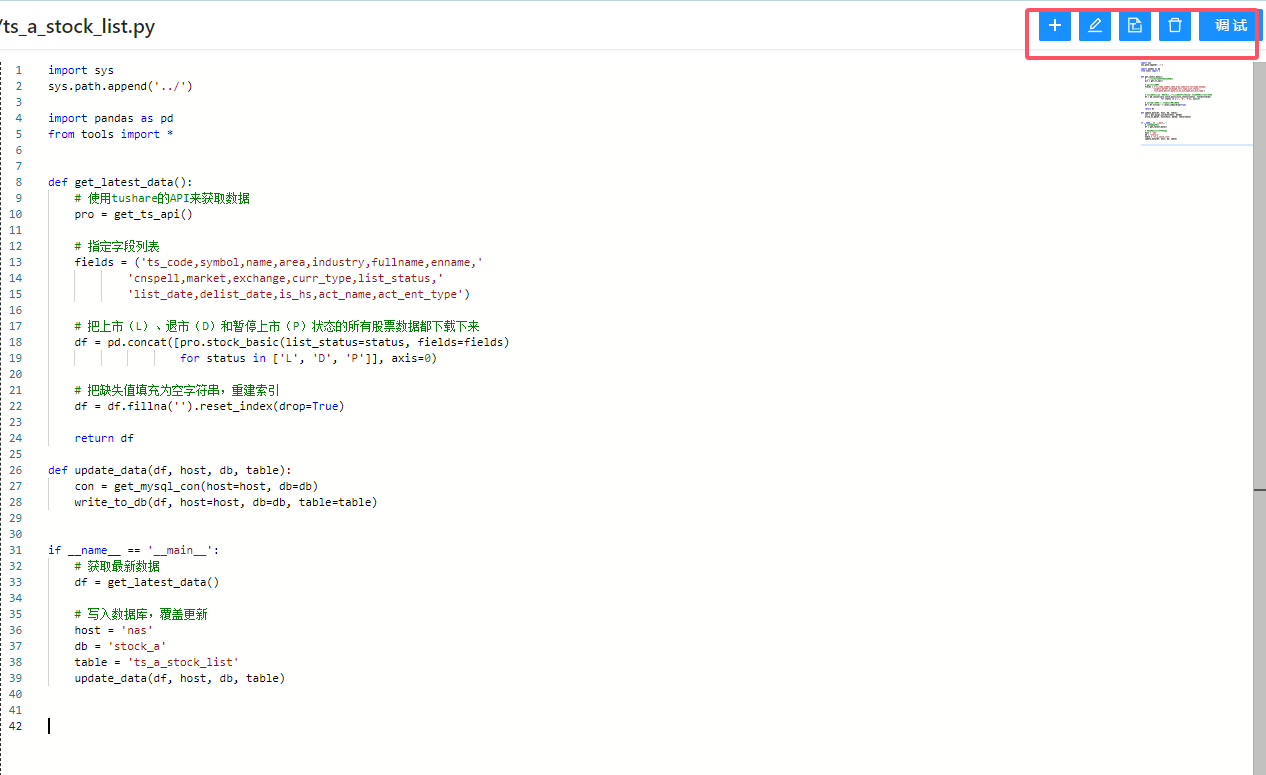
这里右上角有一些按钮,比如创建文件夹或脚本、编辑脚本等。我们把脚本创建完成后,点击调试。
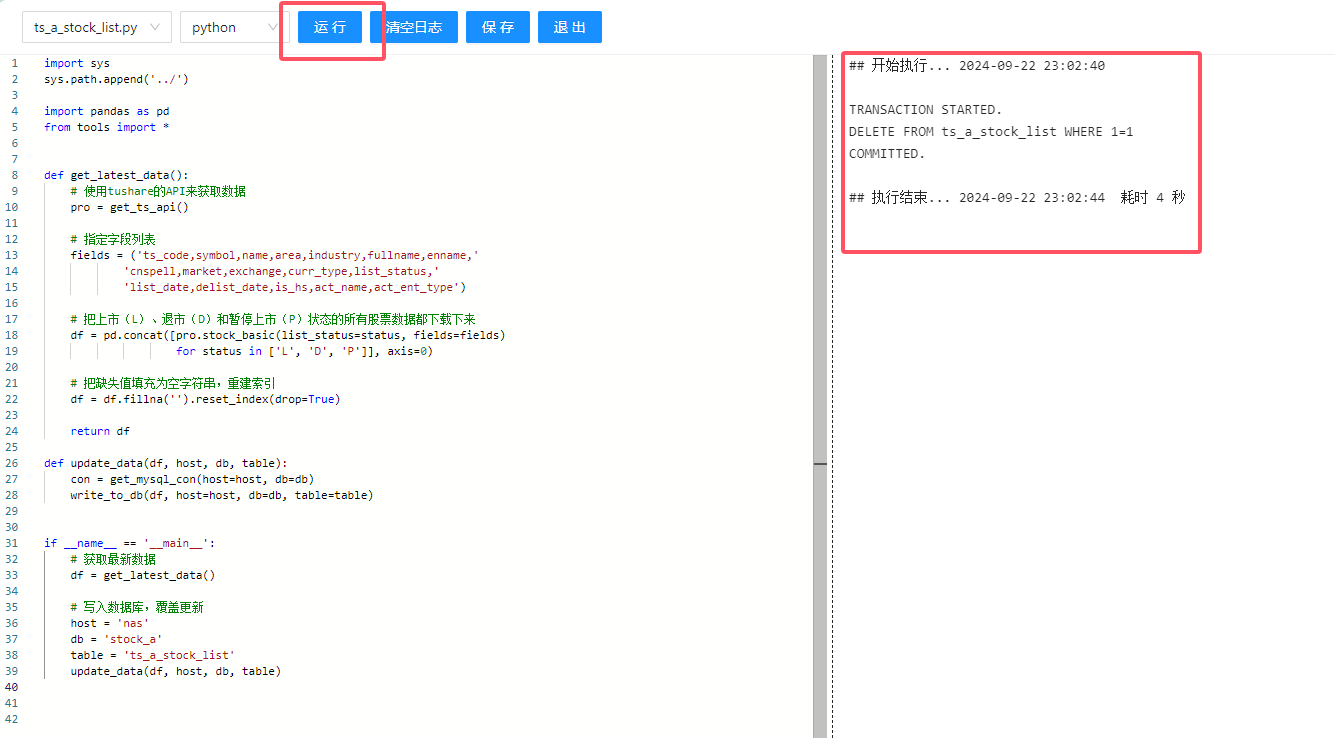
点击运行,可以看到右侧的执行日志中打印出来了我们想要的结果,这代表我们的脚本执行成功了。点击退出回到上一个界面。
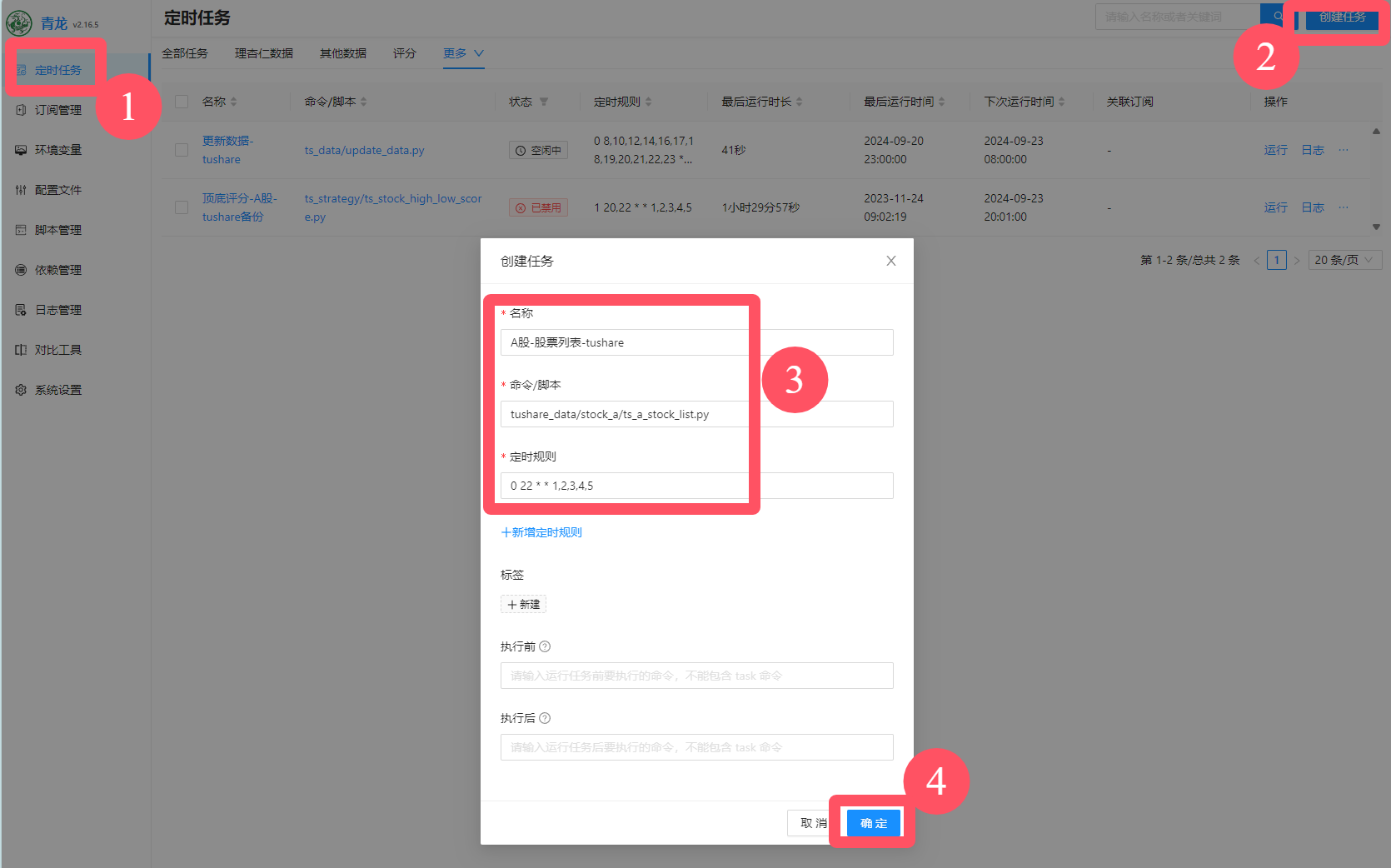
我们在首页点击定时任务,点击右上角创建任务,然后按照下图进行配置。我这里是指定了每周一到周五的晚上10点执行这个脚本来更新数据。
好了,我们已经成功获取了A股股票列表和基本信息数据并且存储到了数据库中,还配置了定时任务来定期更新。是不是没大家想象的那么复杂?
跟着老Q,我们一步步打开量化世界的大门!