网站模板源码下载浙江省建设厅门户网站
三、信号和槽
1.信号和槽概述
在Qt中,用户和控件的每次交互过程称为一个事件。比如"用户点击按钮”是一个事件,"用户关闭窗口”也是一个事件。每个事件都会发出一个信号,例如用户点击按钮会发出"按钮被点击"的信号,用户关闭窗口会发出"窗口被关闭"的信号。
Qt中的所有控件都具有接收信号的能力,一个控件还可以接收多个不同的信号。对于接收到的每个信号,控件都会做出相应的响应动作。例如,按钮所在的窗口接收到"按钮被点击"的信号后,会做出"关闭自己”的响应动作;再比如输入框自己接收到"输入框被点击"的信号后,会做出"显示闪烁的光标,等待用户输入数据”的响应动作。在Qt中,对信号做出的响应动作就称之为槽。
信号和槽是Qt特有的消息传输机制,它能将相互独立的控件关联起来。比如,"按钮"和"窗口"”本身是两个独立的控件,点击"按钮”并不会对"窗口"造成任何影响。通过信号和槽机制,可以将"按钮"和"窗口"关联起来,实现"点击按钮会使窗口关闭"的效果。
Qt中,谈到信号,也是涉及到三个要素
- 信号源:由哪个控件发出的信号,
- 信号的类型:用户进行不同的操作,就可能触发不同的信号
- 信号的处理方式:槽(slot)=>函数,Qt中可以使用connect这样的函数,把一个信号和一个槽关联起来,后续只要信号触发了,Qt就会自动的执行槽函数
槽本质是回调函数
2.connect函数
connect函数是QObject提供的静态的成员函数
connect函数原型(旧版本)
connect(const QObject *sender, //描述了哪个控件发出了信号const char * signal, //信号的类型const QObject * receiver, //信号处理:哪个对象处理const char * method, //信号处理:怎么进行处理Qt:ConnectionType type = Qt:AutoConnection) //暂时不考虑,很少使用,有默认值示例:
ui->setupUi(this);QPushButton* button = new QPushButton(this);button->setText("关闭");button->move(200,200);connect(button,&QPushButton::clicked,this,&Widget::close);3.自定义槽
自定义一个槽函数,操作过程和自定义一个普通的成员函数没什么区别
以前的槽函数必须放到public/private/protected slots:
protected slots,此处是qt自己扩展的关键字,不是C++标准中的语法
Qt里广泛使用了元编程技术,基于代码生成代码,qmake构建qt项目的时候,就会调用专门的扫描器,扫描代码中特定的关键字,给予关键字自动生成一大堆相关代码
①第一种创建方法
创建按钮,处理机制为自定义函数

声明后,实现自定义函数

②第二种创建方法
先用ui文件拖一个控件
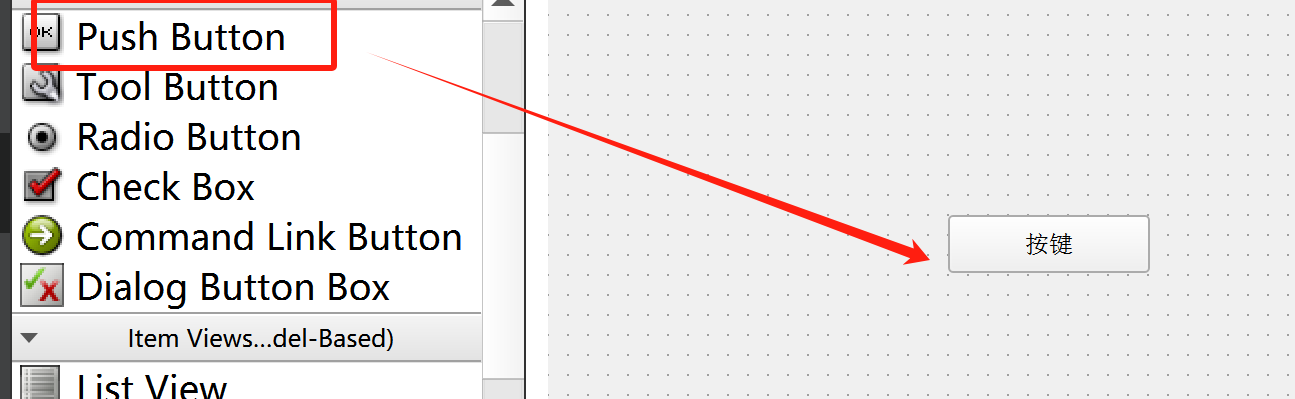
通过ui->pushButton获取到界面上拖进去的这个按钮,然后实现该自定义函数

也可以直接在按钮上右击选择转到槽(更推荐)
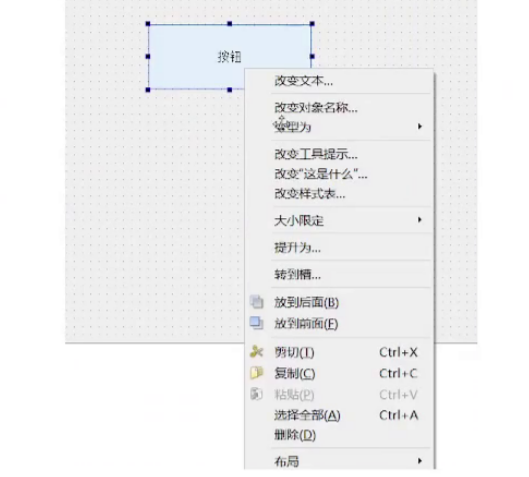
直接生成好一个函数(也完成了声明,且没有connect,因为在qt中,除了通过connect来连接信号槽之外,还可以通过函数名字的方式来自动连接)
on_pushButton_clicked这部分是按钮的objectName,当函数名渡河上述规则后,qt就能自动把信号和槽建立起联系

4.自定义信号
自定义信号比较少见,实际开发中很少会需要自定义信号
自定义槽函数,非常关键,开发中大部分情况都是需要自定义槽函数的
- 信号是一类非常特殊的函数,程序员只要写出函数声明并告诉qt这是一个“信号”即可,在声明的时候,需要在
signal关键字中,这个函数的定义,是在qt编译过程中自动生成的,程序员无法干预,信号在qt中是特殊机制,qt生成的信号函数的实现,要配合qt框架做很多既定的操作 - 作为信号函数,返回值必须是void,有没有参数都可以,甚至可以支持重载,
signals是qt自己扩展出来的关键字,在自定义信号声明前加上,qmake的时候,会调用一些代码的分析/生成工具,扫描到signal关键字的时候,此时,就会自动把下面的函数声明认为是信号,并且给这些信号函数自动生成函数定义


5.带参数的信号和槽
Qt的信号和槽也支持带有参数,同时也可以支持重载,
此处我们要求,信号函数的参数列表要和对应连接的槽函数参数列表一致
一致主要是要求类型,个数可以不一致,但是信号的参数的个数必须要比槽函数的参数个数要多
此时信号触发,调用到槽函数的时候,信号函数中的实参就能够被传递到槽函数的形参当中

QT中如果要让某个类能够使用信号槽,可以在类中定义信号和槽,则必须在类最开始的地方,写下Q_OBJECT宏,能展开成很多额外的代码
6.信号和槽的断开
使用disconnect来断开信号槽的连接
connect和disconnect使用方法很像
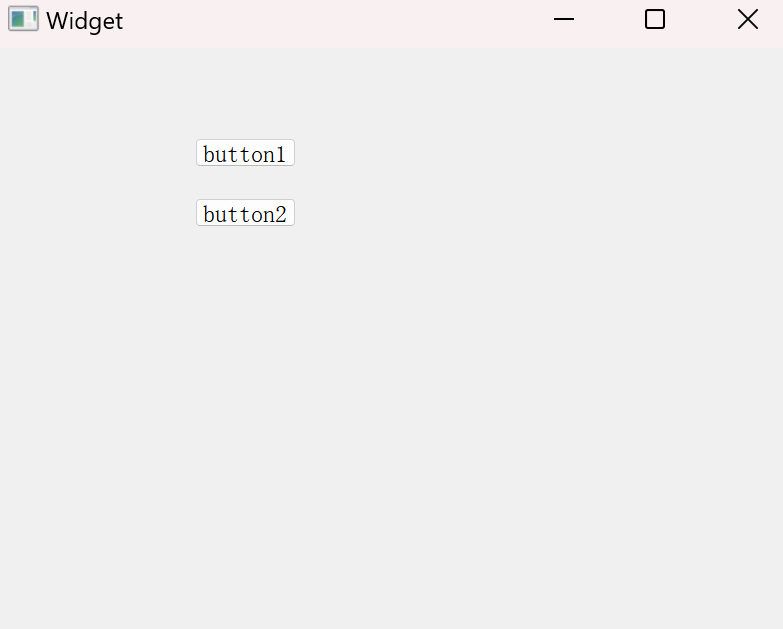
void Widget::on_pushButton_clicked()
{disconnect(ui->pushButton,&QPushButton::clicked,this,&Widget::on_pushButton_2_clicked);connect(ui->pushButton,&QPushButton::clicked,this,&Widget::on_pushButton_clicked);this->setWindowTitle("1");
}void Widget::on_pushButton_2_clicked()
{// 先断开原来的pushButton原来的信号槽disconnect(ui->pushButton,&QPushButton::clicked,this,&Widget::on_pushButton_clicked);// 重新绑定信号槽connect(ui->pushButton,&QPushButton::clicked,this,&Widget::on_pushButton_2_clicked);this->setWindowTitle("2");
}
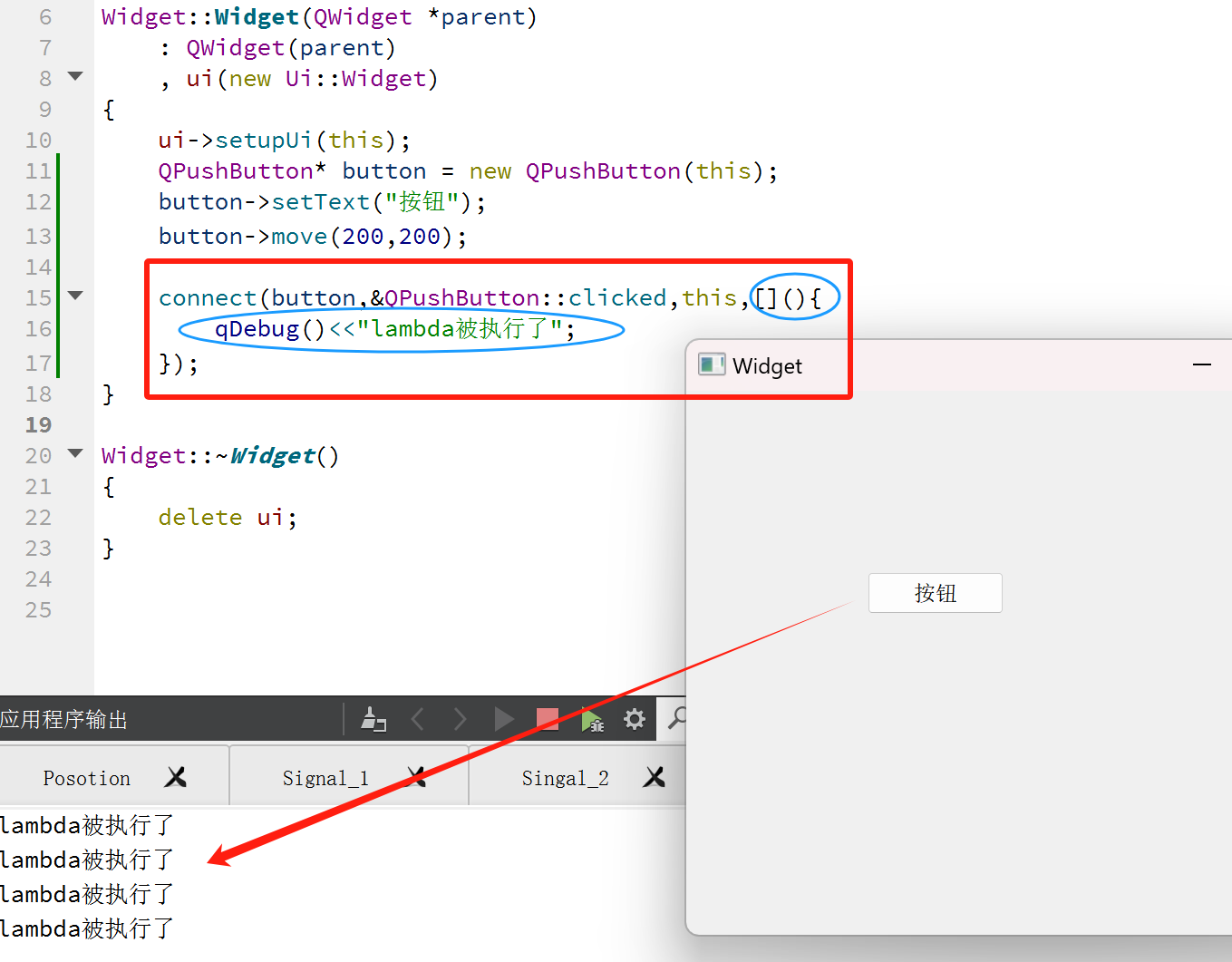
7.lambda表达式定义槽函数
本质是一个匿名函数,主要应用在“回调函数”场景中,一次性使用

为解决上述问题,引入了“变量捕获”语法
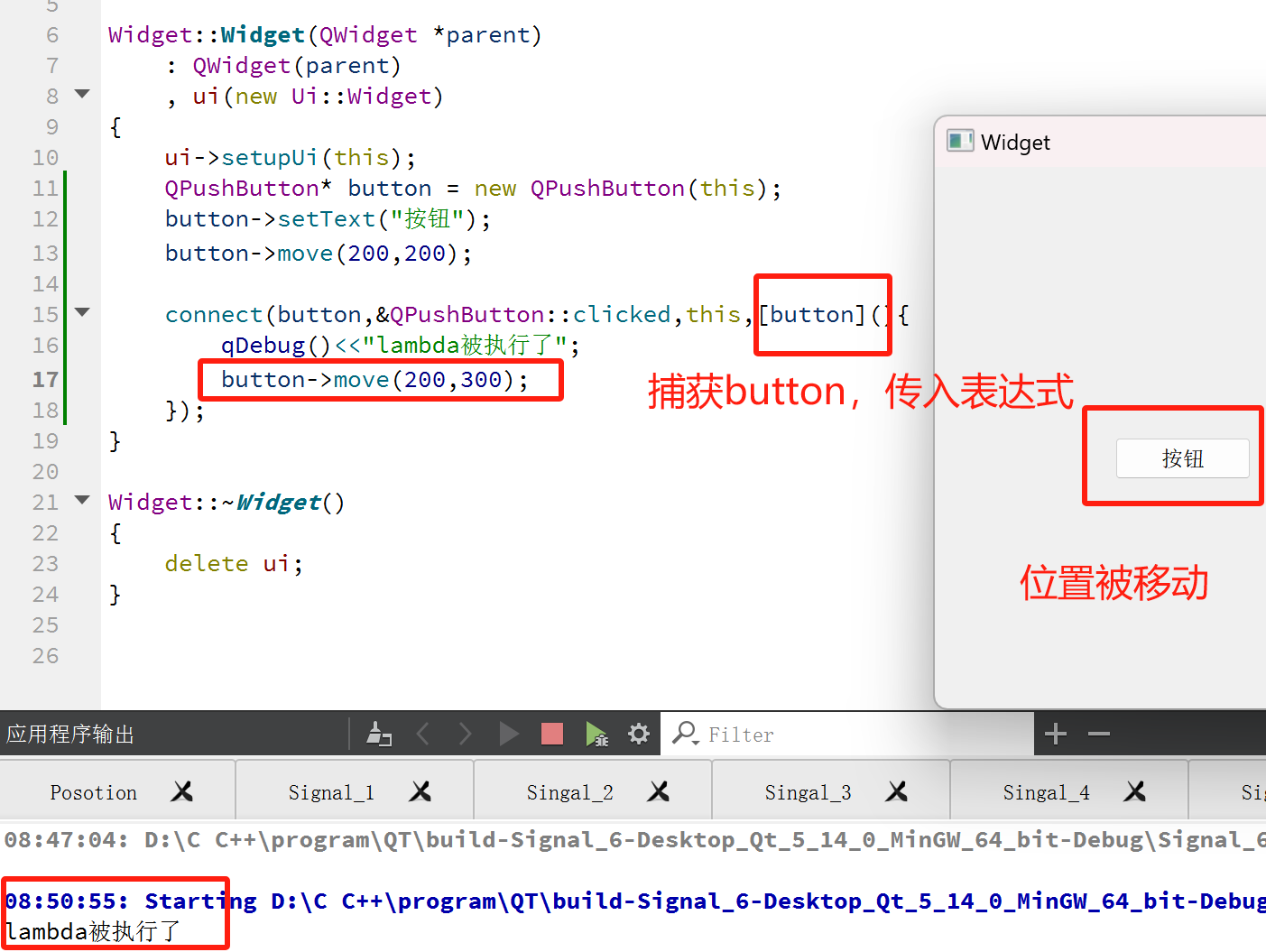
需要多个变量就用逗号隔开,放在方括号中即可
如果想要把上层作用域所有变量名都捕获进来,传入=即可

还可以按照引用的方式来捕获[&],但是qt中很少这么写,捕获到的变量一般都是各种控件的指针,指针变量按照值传递或者引用来传递都无所谓,如果按引用,还得更关注这个引用的变量本身的生命周期
如果对应的槽函数比较简单且一次性使用,就会经常写这种lambda的形式
另外也需要确认捕获到
lambda内部的变量是有意义的:回调函数执行时机是不确定的(用户何时点击按钮是不知道的)如果是像widget对象,他在main函数中,跟随进程结束销毁,但是在访问其他的变量的时候,要确保他在被使用的时候还未被销毁,明确对象生命周期管理
lambda语法是C++11中引入的,如果对于QT5及其更高版本,默认就是按照C++11来编译的,如果使用QT4或者更老的版本,就需要手动在.pro文件中加上C++11的编译选项CONFIG += c++11