山西网站建设营销什么价格学设计的基础是什么
目录
一、元数据管理
1.元数据管理有什么用?
2.如何做好元数据管理?
二、数据整合
1.数据整合有什么用?
2.如何做好数据整合?
三、数据治理
1.数据治理有什么用?
2.如何做好数据治理?
四、数据质量管控
1.数据质量管控有什么用?
2.如何做好数据质量管控闭环管理
五、总结
每天面对几十个系统、上千张数据表,你是否也遇到过这些困扰?
业务部门要的报表对不上口径,技术团队查个数据血缘要花三天,新来的同事猜不出业务含义……
数据量爆炸式增长,但数据找不到、看不懂、信不过、用不好的问题却越来越突出。企业不缺数据,缺的是“能用好”的数据。但别慌!搞定数据管理,关键在于打好四个基础:
1.元数据管理: 解释数据的说明书,让你一眼看懂数据是啥、从哪来、谁负责。
2.数据整合: 打通“数据孤岛”,把散落在各处的数据连起来,形成统一视图。
3.数据治理: 为数据明确责任,保障数据安全与合规。
4.数据质量管控: 给数据做检查,确保数据准确、及时、可靠,值得信赖。
这四个环节环环相扣,缺一不可,它们共同构成了企业用好数据的核心四部曲。接下来,就跟大家深入聊聊,如何一步步把这四部曲落到实处,让你的数据资产真正发挥价值!
一、元数据管理
元数据是“关于数据的数据”,是对数据的描述和定义,包括数据的来源、结构、含义、关系等信息,可以帮助我们理解、导航和利用庞大的数据资产。
1.元数据管理有什么用?
元数据管理是通过收集、存储、管理和应用元数据,为数据的全生命周期提供支持,确保数据的可理解性、可追溯性和可用性。
2.如何做好元数据管理?
(1)建立全景式数据视图:利用数据管理平台的扫描功能,自动捕获数据库表结构、ETL脚本血缘关系、API接口定义等信息,检查和捕捉脏数据,确保元数据的实时性和准确性。
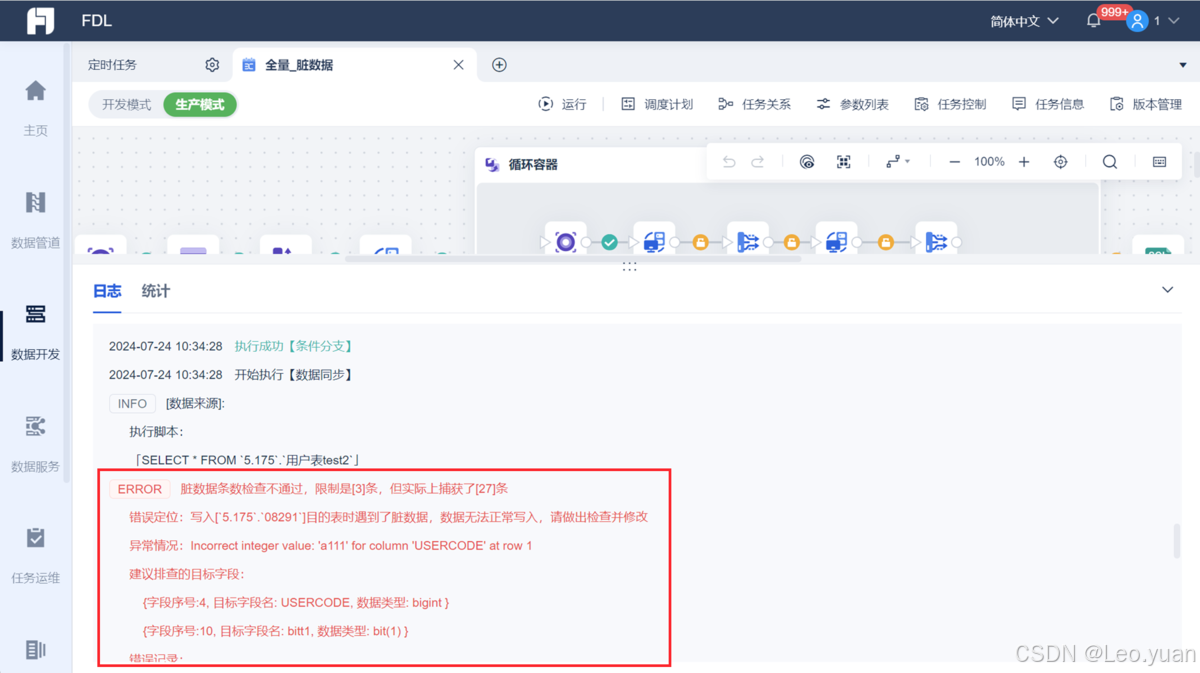
(2)附加业务上下文:为技术字段添加业务术语、定义、责任人、敏感级别等关键业务属性。例如,将“customer_id”字段定义为“活跃用户唯一标识符”,分类为“会员域”,标记为“PII敏感”,并指定负责人为“张三”,这样数据使用者可以快速理解字段的业务含义和重要性。
(3)优化数据搜索:构建一个基于元数据的“数据搜索引擎”,输入关键词或业务需求,即可快速找到相关的数据表、字段,并展示其血缘来源、加工逻辑、质量评分、使用频率和用户评价等信息。
(4)构建血缘图谱:清晰地可视化数据从源系统到目标系统的完整旅程,包括数据的加工处理过程和流向。企业进行数据管理和构建血缘图谱的过程中,选对数据集成与治理工具才能事半功倍,我身边同事都在用的数据集成平台FineDataLink 能够连接多种不同类型的数据来源,包括数据库、文件系统、云存储以及各类业务系统等,都可以进行统一的收集和整合,打破数据孤岛。同时,FineDataLink具备数据清洗和校验的功能,可以自动识别并处理重复数据、缺失值、错误数据等,通过预设的规则和算法对数据进行标准化和规范化处理,确保收集到的数据具有较高的准确性和一致性。
二、数据整合
数据整合是将分散在不同系统、格式和存储介质中的数据进行整合,形成统一的数据视图,以满足企业对数据的分析、共享和应用需求。
1.数据整合有什么用?
它可以打破数据孤岛,实现数据的互联互通,为企业提供一致、准确和完整的数据支持。
2.如何做好数据整合?
(1)虚拟化联邦:利用Denodo、Dremio等数据虚拟化工具,提供统一的SQL接口,实时查询分散在Hive、关系型数据库、对象存储、NoSQL等不同数据源中的数据。这种方式无需物理搬迁数据,轻量敏捷,适合探索性分析和敏捷开发场景。
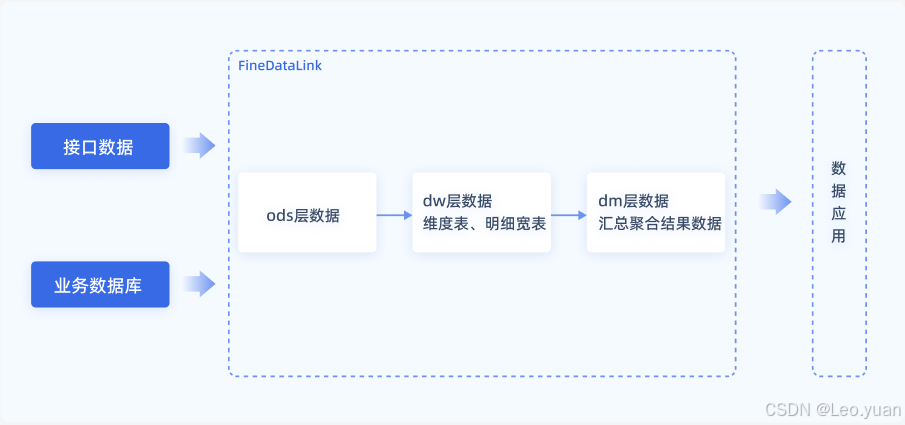
(2)中心化集市 + 按需入湖:将核心共享维度、关键指标、高频使用数据集中存储在数据仓库或数据集市中,而原始数据、低频数据和探索性数据则保留在数据湖中,按需加工后进入集市。
(3)CDC + 流处理:通过变更Kafka、Debezium等数据捕获(CDC)工具,捕获源数据库的变更数据,再利用Flink等流处理引擎进行实时清洗、转换和写入目标数据库。这种方式能够实现关键业务数据的近实时整合,满足风控、实时推荐等对时效性要求较高的业务场景。
(4)优化数据产品接口:制定清晰的数据接口契约,明确数据提供方和消费方的责任和义务。数据提供方需承诺数据的格式、更新频率、服务质量(SLA)和质量基线,消费方则按照契约要求使用数据。契约是数据整合的基础保障,确保数据的稳定供应和正确使用。
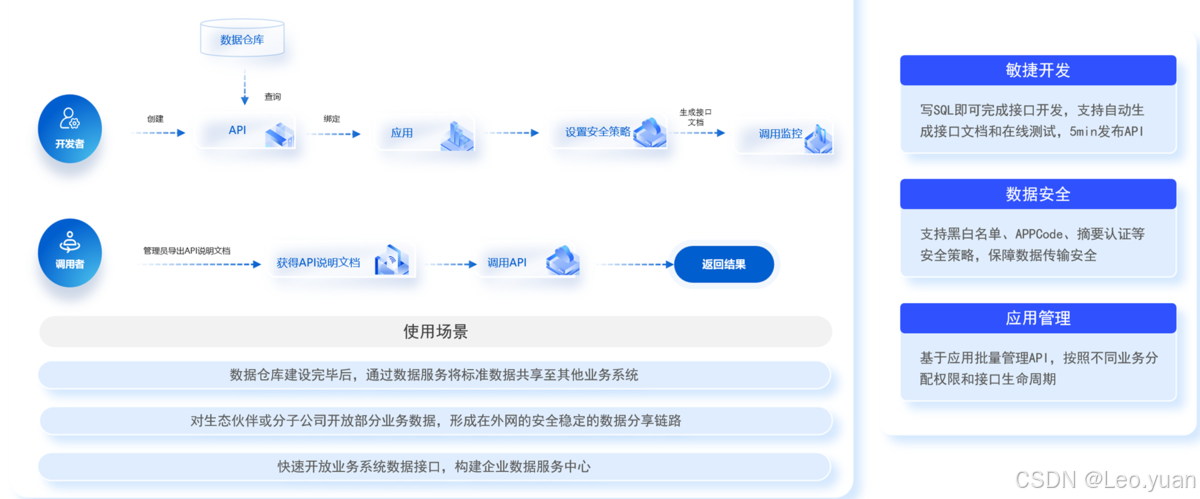
(5)数据服务化:将整合后的数据以数据服务API或数据市场的方式发布,供消费方按需订阅和自助获取。这种方式降低了数据接入成本,提高了数据的复用性和共享效率。
三、数据治理
数据治理是通过建立一套完善的组织架构、政策制度、流程机制和工具平台,对数据的全生命周期进行管理和控制,以确保数据的质量、安全、合规和价值最大化。
1.数据治理有什么用?
它不仅是对数据的管控,更是对数据的赋能,通过明确责任、规范流程、优化资源,为企业创造更大的数据价值。
2.如何做好数据治理?
(1)组织与职责:设立数据治理委员会,负责数据治理的决策和战略规划;明确业务域负责人和技术执行人员的职责,将责任落实到具体的业务域和岗位。
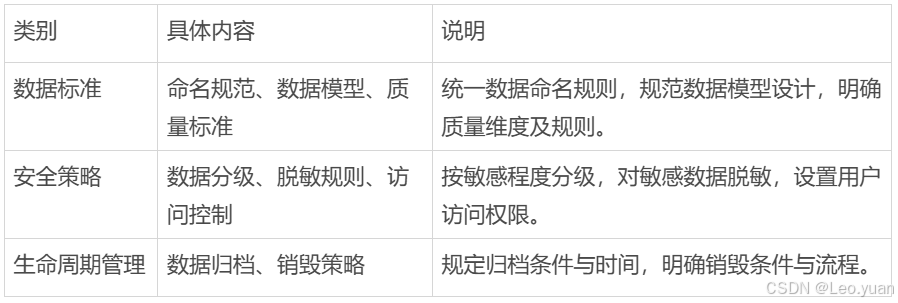
(2)政策与标准:制定数据标准、安全策略、生命周期管理等政策制度,确保数据管理有章可循。
(3)流程与执行:建立数据申请、变更、质量改进、合规审计等流程机制,并通过工具平台实现流程的自动化和轻量化。例如,在数据开发平台中集成数据申请和变更流程,开发者可以在平台上提交申请,系统自动流转审批,提高工作效率。
(4)将治理能力嵌入平台:在数据开发、管理工具中集成自动化的治理功能,如数据标准检查、质量规则配置、敏感数据扫描和脱敏等。开发者在日常工作中无需额外操作,即可自动遵循治理要求,实现“无感治理”。
四、数据质量管控
数据质量管控是通过对数据的完整性、准确性、时效性、一致性、唯一性等质量维度进行监控、分析和改进,确保数据满足业务需求和应用要求的过程。
1.数据质量管控有什么用?
它直接关系到数据的可信度和价值,是数据驱动决策的基础保障。
2.如何做好数据质量管控闭环管理
(1)定义(Define):与业务部门共同明确关键数据的质量维度和具体规则,确定质量指标的阈值和优先级。
(2)测量(Measure):在数据的源头、加工环节和消费端部署质量检查点,自动化监控数据质量规则的执行情况。
(3)分析(Analyze):对质量告警进行根因分析,确定问题是由于数据源头错误、加工逻辑缺陷还是质量规则不合理等原因引起的。
(4)改进(Improve):推动责任方修复数据质量问题,优化数据加工逻辑和质量规则,并建立问题工单跟踪机制,确保问题得到及时解决。
(5)控制(Control):将关键质量规则嵌入数据上线流程,作为数据发布的卡点,确保只有质量达标的数据才能进入生产环境。
五、总结
元数据管理、数据整合、数据治理与数据质量管控,共同构成了企业数据管理的四部曲。清晰准确的元数据是整合、治理和质量工作的基础;有效的整合依赖于治理规则和质量的约束;治理目标的达成离不开元数据支撑和质量的度量;而高质量数据的产生与维持,更是需要前三者的共同保障。四者环环相扣,相互依存。将这四项能力协同推进,建立贯穿数据生命周期的管理体系,才能将海量、无序的数据真正转化为驱动业务增长、支持精准决策、保障合规安全的战略资产。