网站制作 技术郑州市建设工程信息网官网
Rust基础拾遗
- 前言
- 1.所有权与移动
- 1.1 所有权
- 2.引用
- 3.特型与泛型
- 简介
- 3.1 使用特型
- 3.2 特型对象
- 3.3 泛型函数与类型参数
- 4.实用工具特型
- 5.闭包
前言
通过Rust程序设计-第二版笔记的形式对Rust相关重点知识进行汇总,读者通读此系列文章就可以轻松的把该语言基础捡起来。
1.所有权与移动
谈及内存管理,我们希望编程语言能具备两个特点:
- 希望内存能在我们选定的时机及时释放,这使我们能控制程序的内存消耗;
- 在对象被释放后,我们绝不希望继续使用指向它的指针,这是未定义行为,会导致崩溃和安全漏洞。
Rust 通过限制程序使用指针的方式出人意料地打破了这种困局。悬空指针、重复释放、使用未初始化的内存等。
Rust 程序中的缺陷不会导致一个线程破坏另一个线程的数据,进而在系统中的无关部分引入难以重现的故障。
相关问题:
看看所有权在概念层和实现层分别意味着什么?
如何在各种场景中跟踪所有权的变化?
哪些情况下要改变或打破其中的一些规则,以提供更大的灵活性?
1.1 所有权
拥有对象意味着可以决定何时释放此对象:当销毁拥有者时,它拥有的对象也会随之销毁。
变量拥有自己的值,当控制流离开声明变量的块时,变量就会被丢弃,因此它的值也会一起被丢弃。例如:
fn print_padovan() {let mut padovan = vec![1,1,1]; // 在此分配for i in 3..10 {let next = padovan[i-3] + padovan[i-2];padovan.push(next);}println!("P(1..10) = {:?}", padovan);
} // 在此丢弃
变量 padovan 的类型为 Vec<i32>。在内存中,padovan 的最终值如图所示。
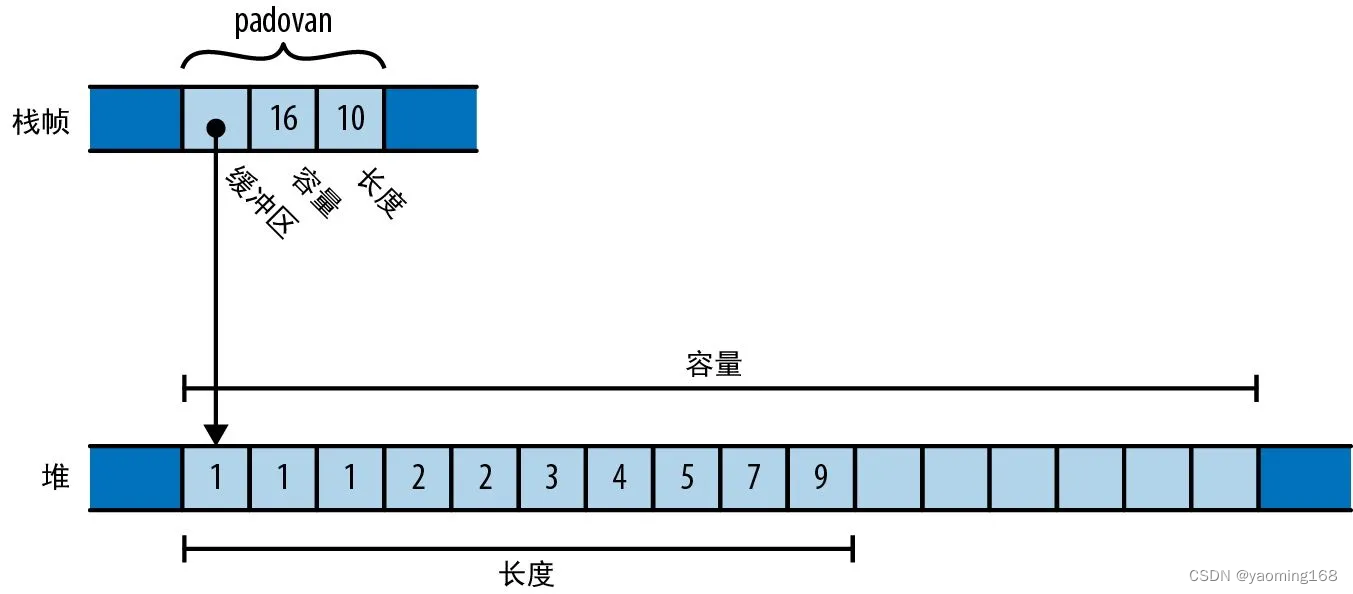 跟C++ std::string 非常相似,不过缓冲区中的元素都是 32 位整数,而不是字符。
跟C++ std::string 非常相似,不过缓冲区中的元素都是 32 位整数,而不是字符。
2.引用
3.特型与泛型
简介
本章展示特型的用法、工作原理,以及如何定义你自己的特型。
标准库提供的公共特型。之后的闭包、迭代器、输入 / 输出和并发。特型和泛型在所有这些主题中都扮演着核心角色。
Rust 通过两个相关联的特性来支持多态:特型和泛型。
特型是 Rust 体系中的接口或抽象基类。
为什么向类型添加特型不需要额外的内存?
如何在不需要虚方法调用开销的情况下使用特型?
泛型是 Rust 中多态的另一种形式。
泛型和特型紧密相关:泛型函数会在限界中使用特型来阐明它能针对哪些类型的参数进行调用。
3.1 使用特型
特型代表着一种能力,即一个类型能做什么。
- 实现了 std::io::Write 的值能写出一些字节。
- 实现了 std::iter::Iterator 的值能生成一系列值。
- 实现了 std::clone::Clone 的值能在内存中克隆自身。
- 实现了 std::fmt::Debug 的值能用带有 {:?} 格式说明符的 println!() 打印出来。
特型方法类似于虚方法。
3.2 特型对象
在 Rust 中使用特型编写多态代码有两种方法:特型对象和泛型。
在 Rust 中,引用是显式的:
let mut buf: Vec<u8> = vec![];
let writer: &mut dyn Write = &mut buf; // 正确
对特型类型(如 writer)的引用叫作特型对象。
特型对象的内存布局
在内存中,特型对象是一个胖指针,由指向值的指针和指向表示该值类型的虚表的指针组成。
C++ 也有这种运行期类型信息,叫作虚表或 vtable。
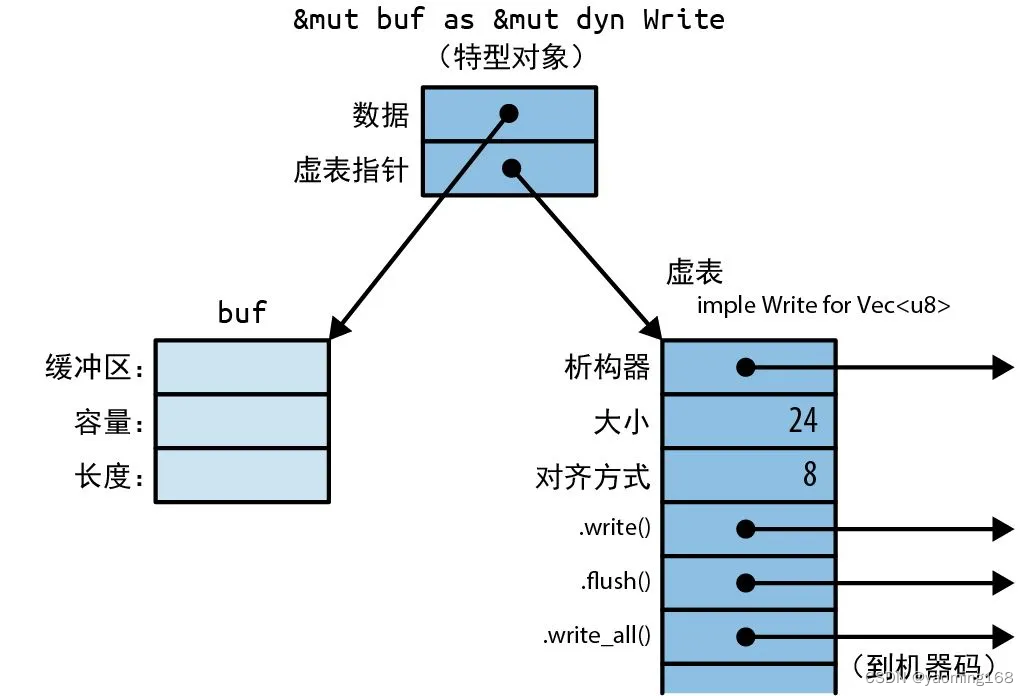 在 C++ 中,虚表指针或 vptr 是作为结构体的一部分存储的,而 Rust 使用的是胖指针方案。结构体本身只包含自己的字段。这样一来,每个结构体就可以实现几十个特型而不必包含几十个 vptr 了。甚至连 i32 这样大小不足以容纳 vptr 的类型都可以实现特型。
在 C++ 中,虚表指针或 vptr 是作为结构体的一部分存储的,而 Rust 使用的是胖指针方案。结构体本身只包含自己的字段。这样一来,每个结构体就可以实现几十个特型而不必包含几十个 vptr 了。甚至连 i32 这样大小不足以容纳 vptr 的类型都可以实现特型。
3.3 泛型函数与类型参数
4.实用工具特型
5.闭包
fn sort_cities(cities: &mut Vec<City>) {cities.sort_by_key(|city| -city.population);
}
|city| -city.population 就是闭包。它会接受一个参数 city 并返回 -city.population。Rust 会从闭包的使用方式中推断出其参数类型和返回类型。
闭包相关问题:
Rust 的闭包与匿名函数有何不同?
如何将闭包与标准库方法一起使用?
闭包如何“捕获”其作用域内的变量?
如何编写自己的以闭包作为参数的函数和方法?
何存储闭包供以后用作回调?
Rust 闭包是如何实现的,以及它们为什么比你预想的要快?