网页设计中优秀的网站网页软件下载
文章目录
- 前言
- 1. 本地部署ComfyUI
- 2. 下载 Flux.1 模型
- 3. 下载CLIP模型
- 4. 下载 VAE 模型
- 5. 演示文生图
- 6. 公网使用 Flux.1 大模型
- 6.1 创建远程连接公网地址
- 7. 固定远程访问公网地址
前言
在这个AI技术日新月异的时代,图像生成模型已经成为了创意工作者和开发者手中的神器。如果你对如何快速上手并利用这些黑科技感兴趣,那么今天的内容绝对会让你大开眼界!
Flux.1 是由 Black Forest Labs 推出的一款免费开源图像生成模型,通过 ComfyUI 这个用户友好的界面,你不仅能够轻松调用这款神器,还能在创意的海洋中畅游。Black Forest Labs 的创始人 Robin Rombach 曾是 Stability AI 的核心成员之一,团队中的许多人都来自 Stable Diffusion 的原始开发团队。这简直就是生成式模型界的梦之队!
那么,如何在本地部署安装 ComfyUI 并搭建 Flux.1,并结合 Cpolar 内网穿透工具实现远程生图呢?别急,跟着我们的步伐,一步步揭开这个神秘面纱吧!

【视频教程】
最近爆火的Flux.1 AI生图模型Windows电脑本地安装与使用保姆级教程
1. 本地部署ComfyUI
本篇文章测试环境:Win11专业版,8GB显存
进入到官方Github中,下载最新版ComfyUI
ComfyUI Github:GitHub - comfyanonymous/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface.
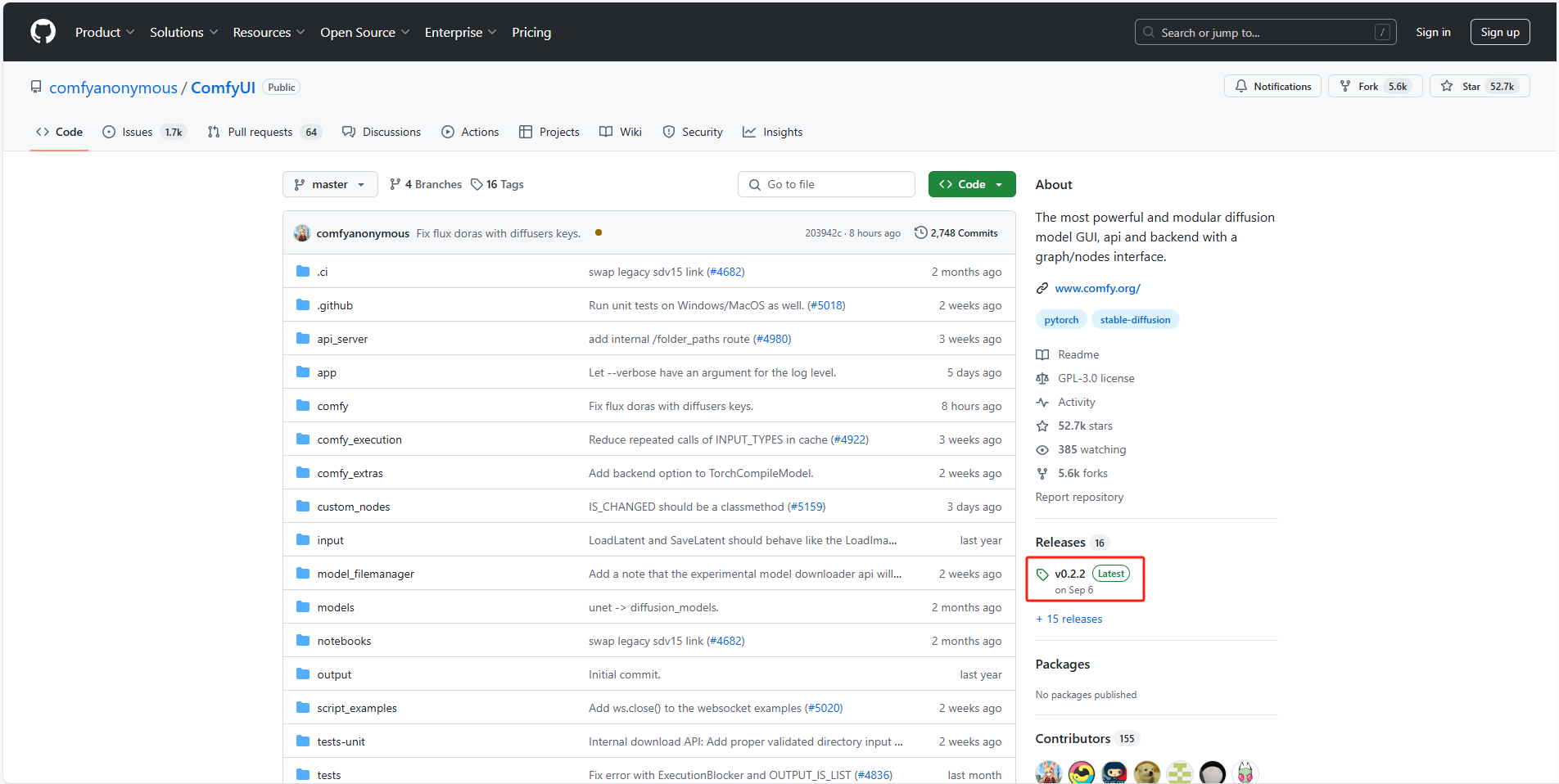
找到免安装版本
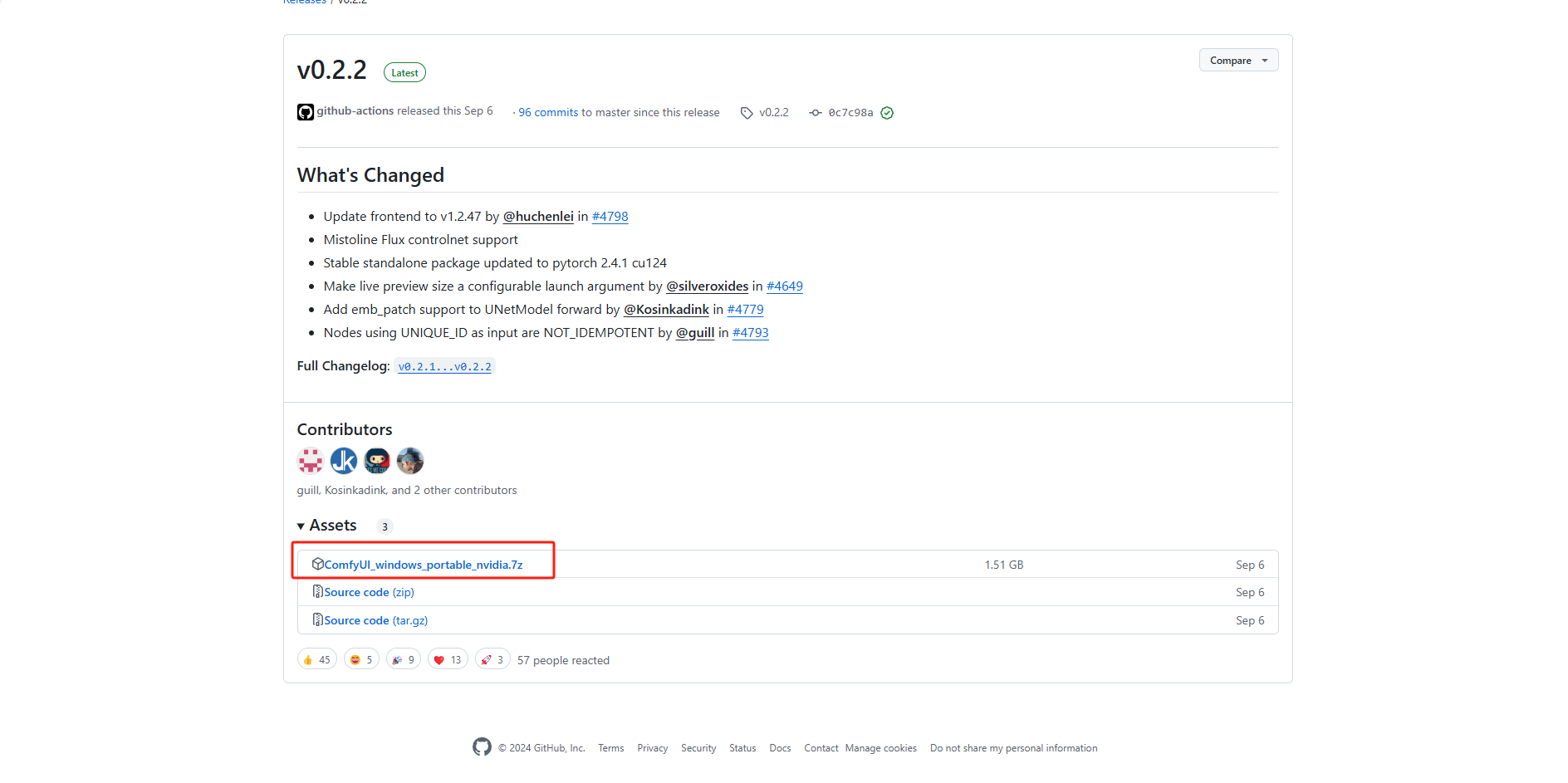
解压保存到本地打开,进入到根目录下,有 run_cpu、run_nvidia_gpu
第一个是通过CPU进行解码的,第二个是通过Nvidia显卡进行解码的,速度会更快
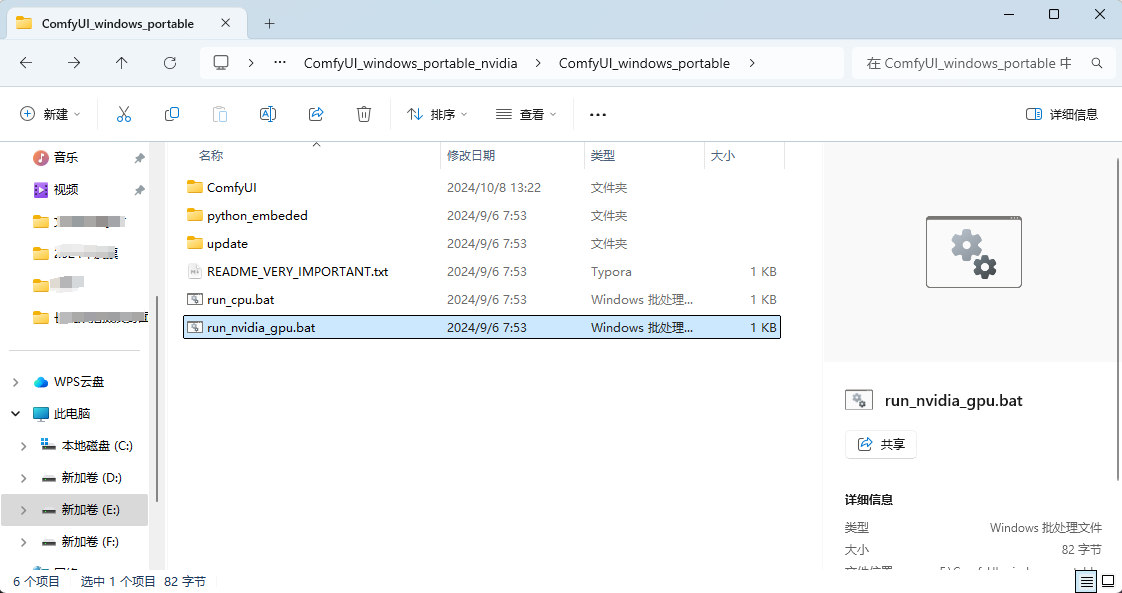
双击打开这两个其中哪个脚本都可以,运行脚本
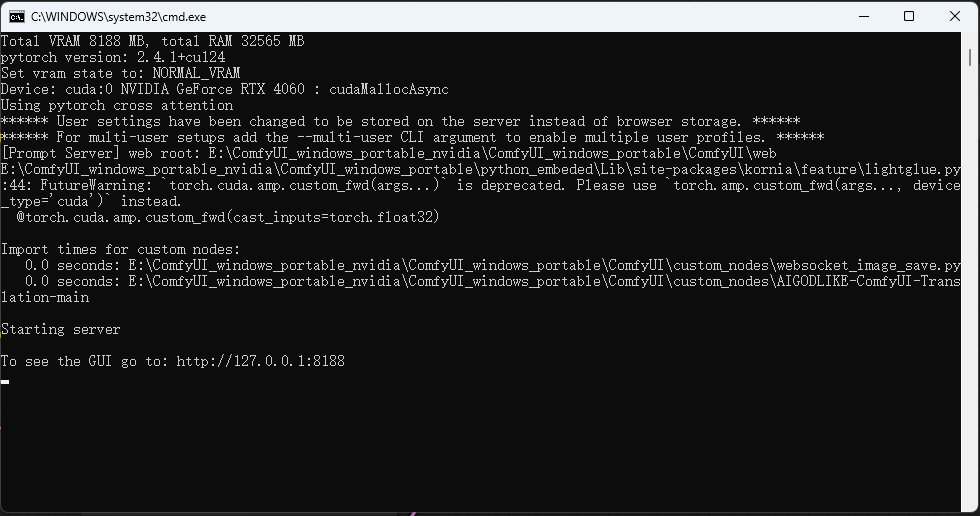
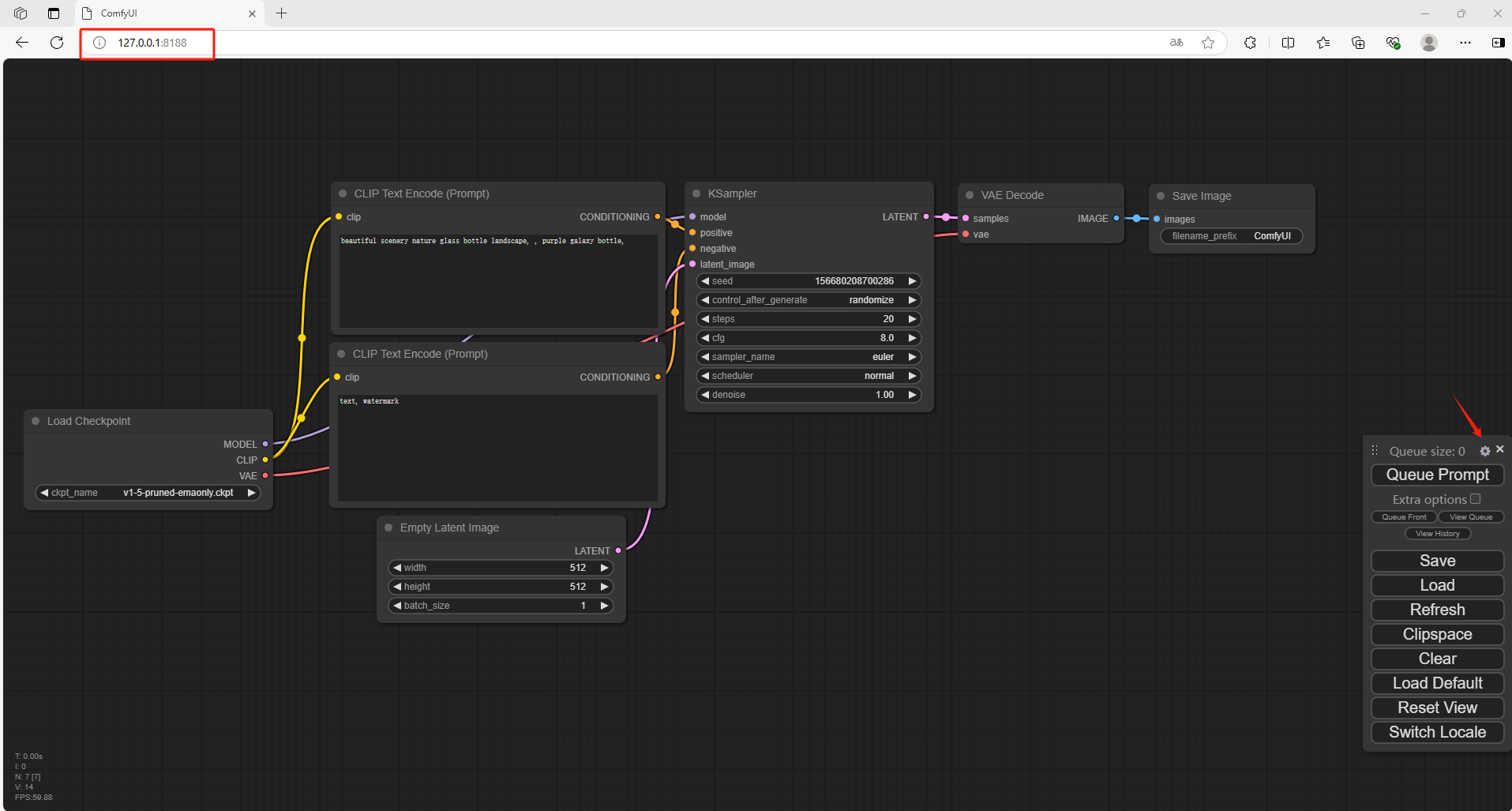
打开一个新的浏览器输入 http://127.0.0.1:8188
可以看到进入到了ComfyUI当中,但是默认情况下是英文,需要设置成中文
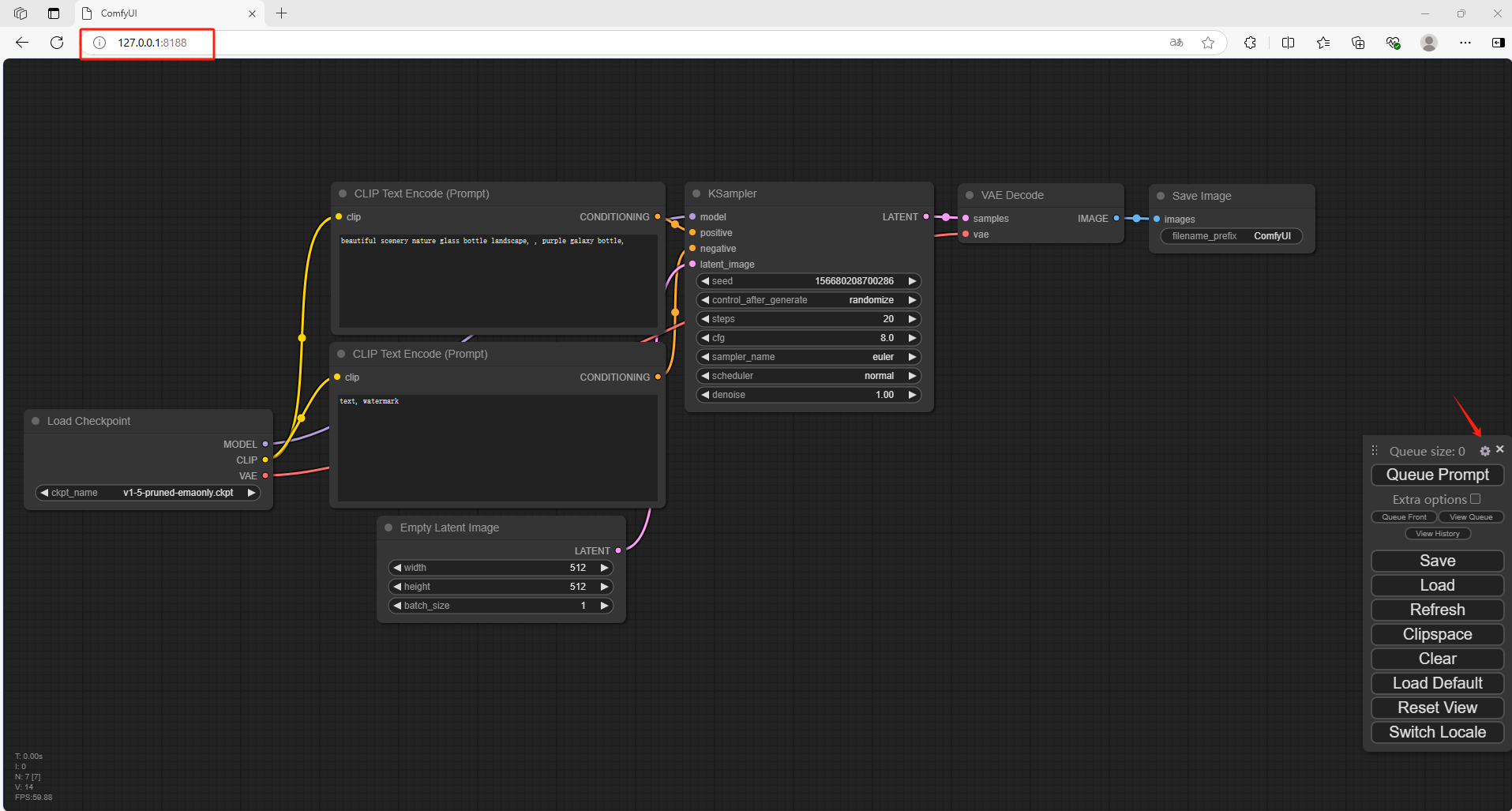
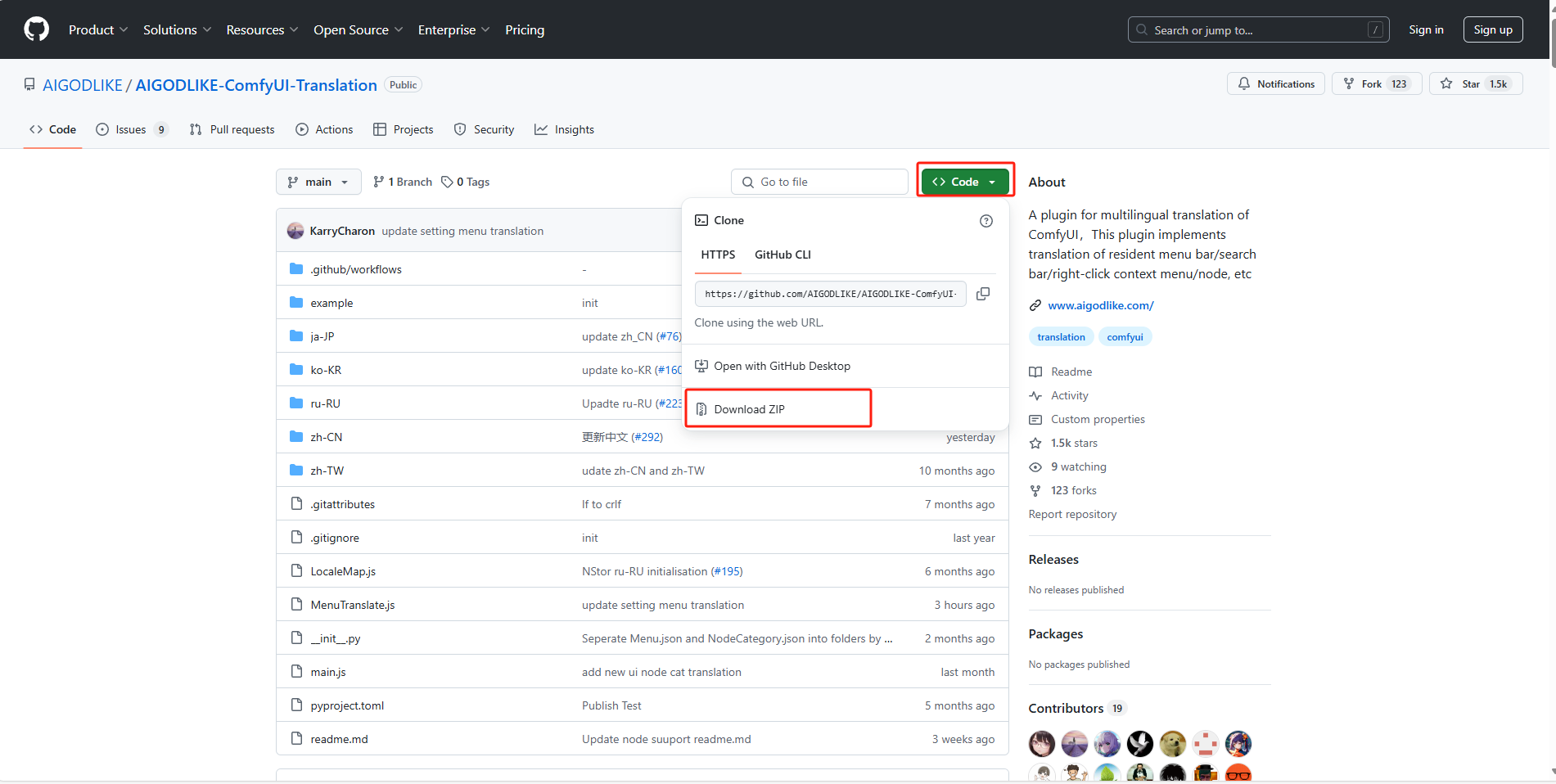
下载中文语言包,点击链接:GitHub - AIGODLIKE/AIGODLIKE-ComfyUI-Translation: A plugin for multilingual translation of ComfyUI,This plugin implements translation of resident menu bar/search bar/right-click context menu/node, etc
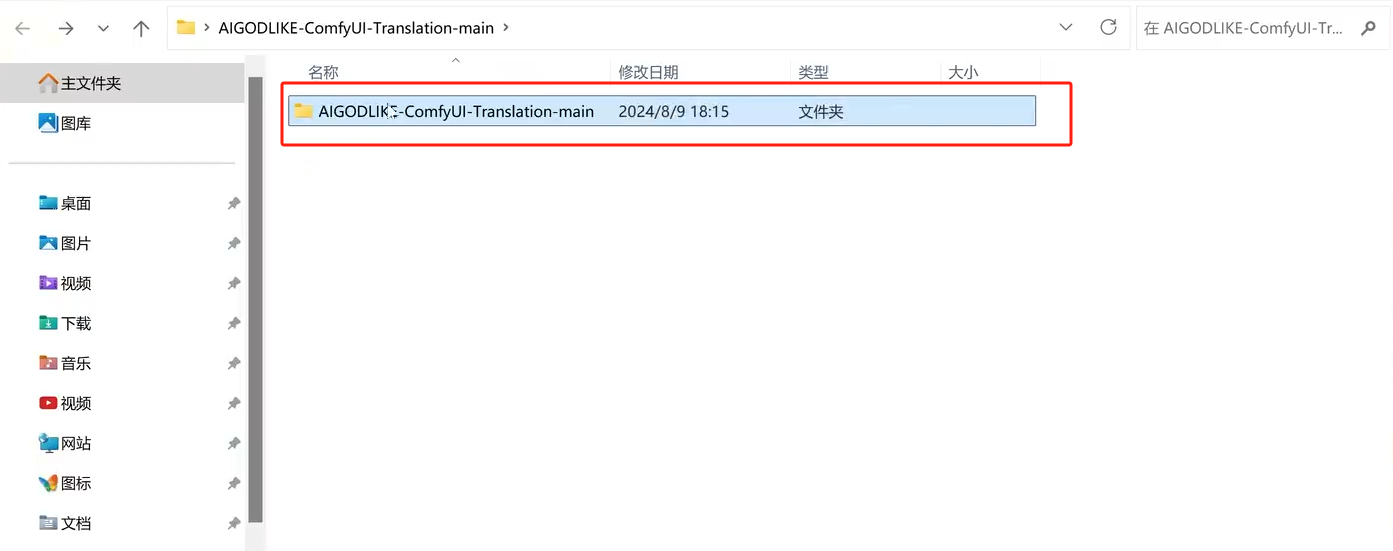
下载压缩包并解压到本地
解压后,进入到根目录,把这个文件放到ComfyUI \ custom_nodes 目录中
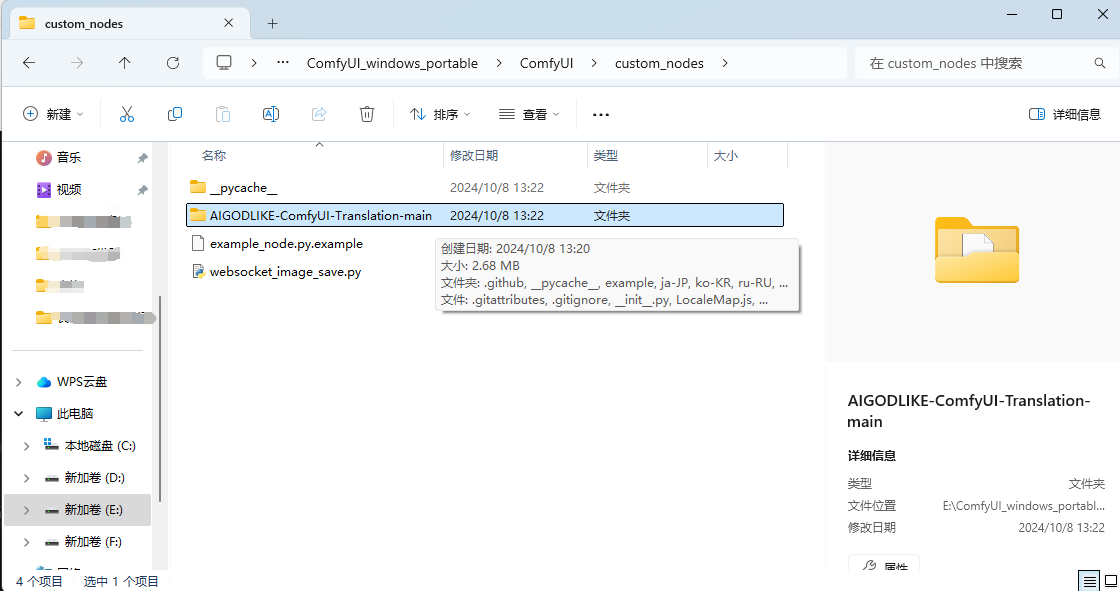
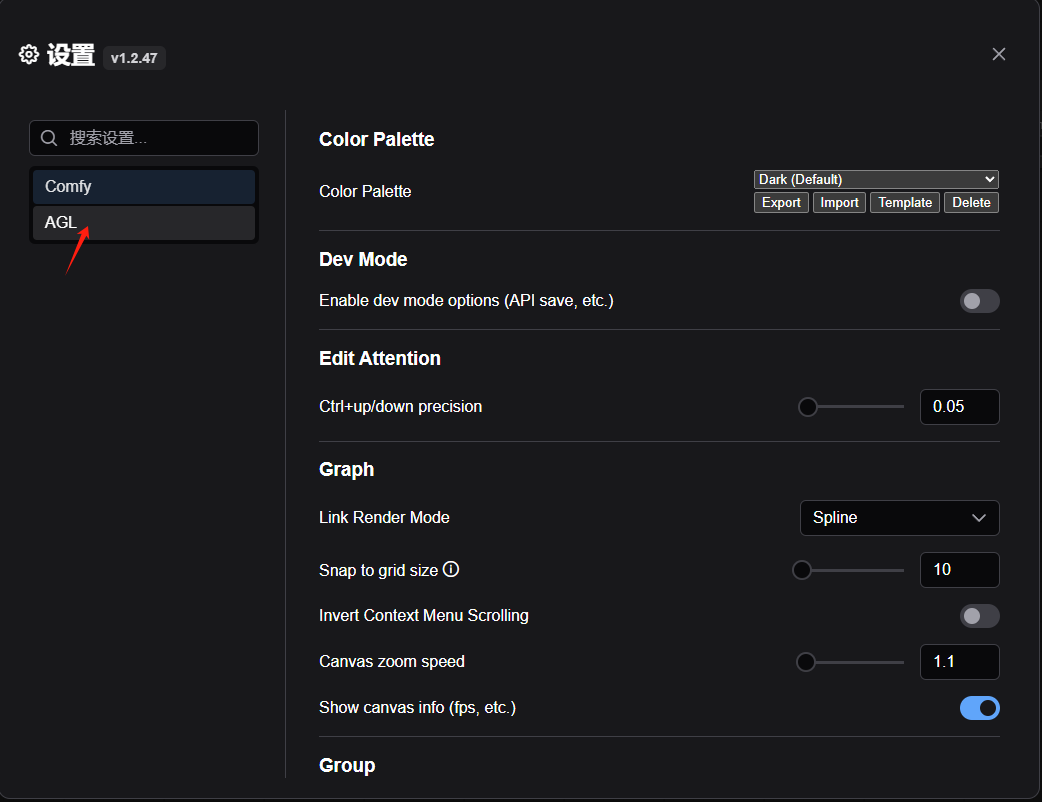
回到 Comfy UI 中,点击设置,选择语言为中文
2. 下载 Flux.1 模型
FLUX 模型有四个可选,FLUX.1 [dev] 、FLUX.1 [dev] fp8、FLUX.1 [schnell]、FLUX.1 [schnell] fp8;
- FLUX.1 [dev] :官方版本满配版,最低显存要求24G;下载地址: https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main
- FLUX.1 [dev] fp8:大佬优化 [dev] 后版本,建议选择此版本,最低 12G 显存可跑;下载地址: https://huggingface.co/Kijai/flux-fp8/blob/main/flux1-dev-fp8.safetensors
- FLUX.1 [schnell]:4步蒸馏模型,大多数显卡可跑。 下载地址: https://hf-mirror.com/black-forest-labs/FLUX.1-schnell/tree/main
- FLUX.1 [schnell] fp8:优化 版本,适应更低的显卡配置。下载地址: https://huggingface.co/Kijai/flux-fp8/blob/main/flux1-schnell-fp8.safetensors
这里下载第3种,4步蒸馏模型,大多数显卡可跑。
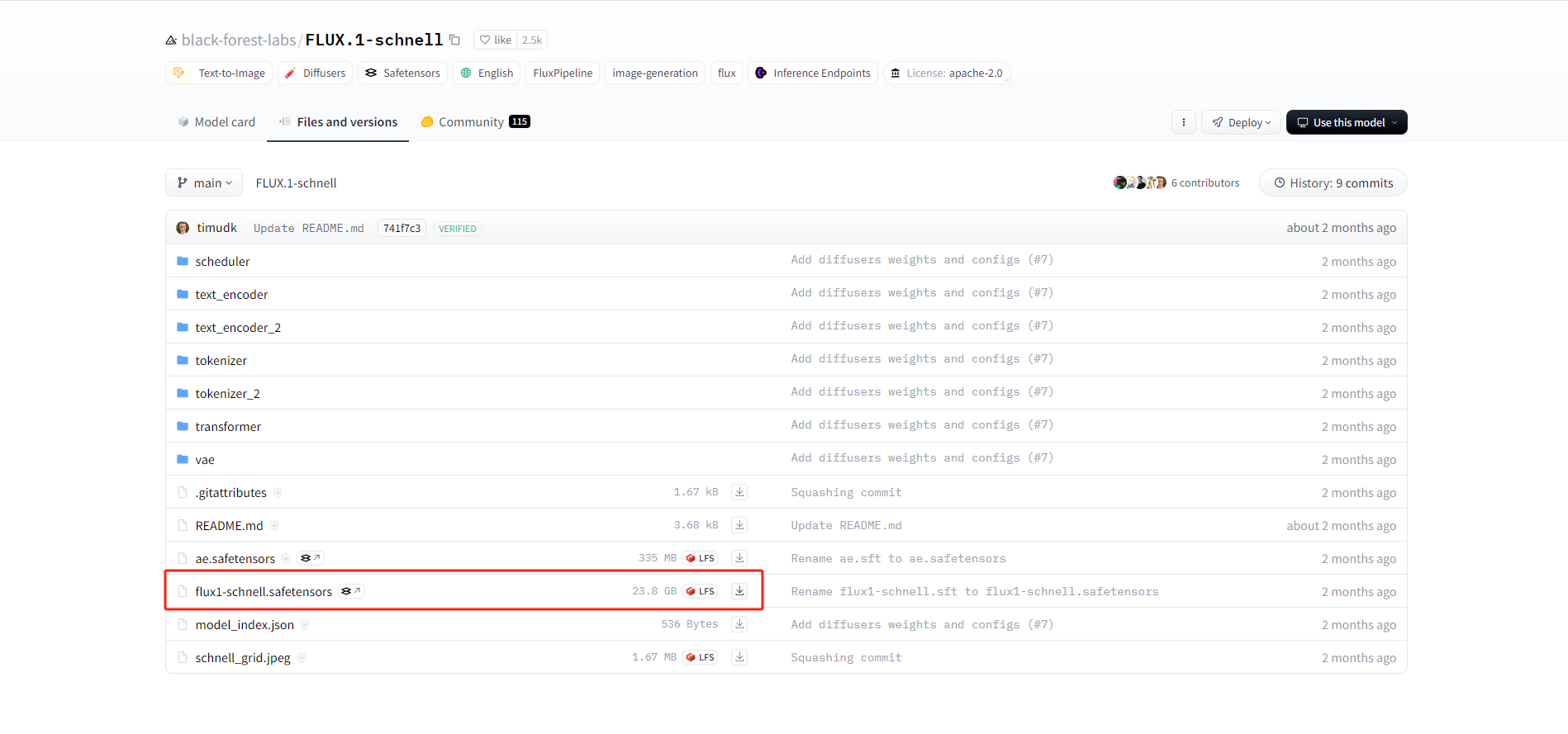
无论下载上面的哪个模型,都存放在这个:ComfyUI/models/unet/ 目录下
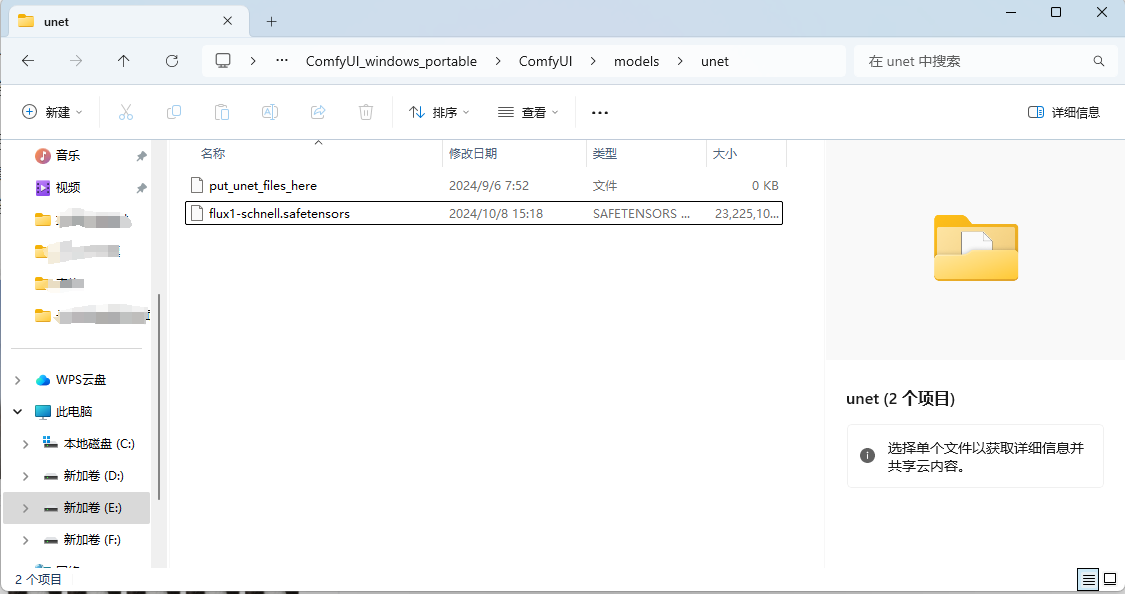
3. 下载CLIP模型
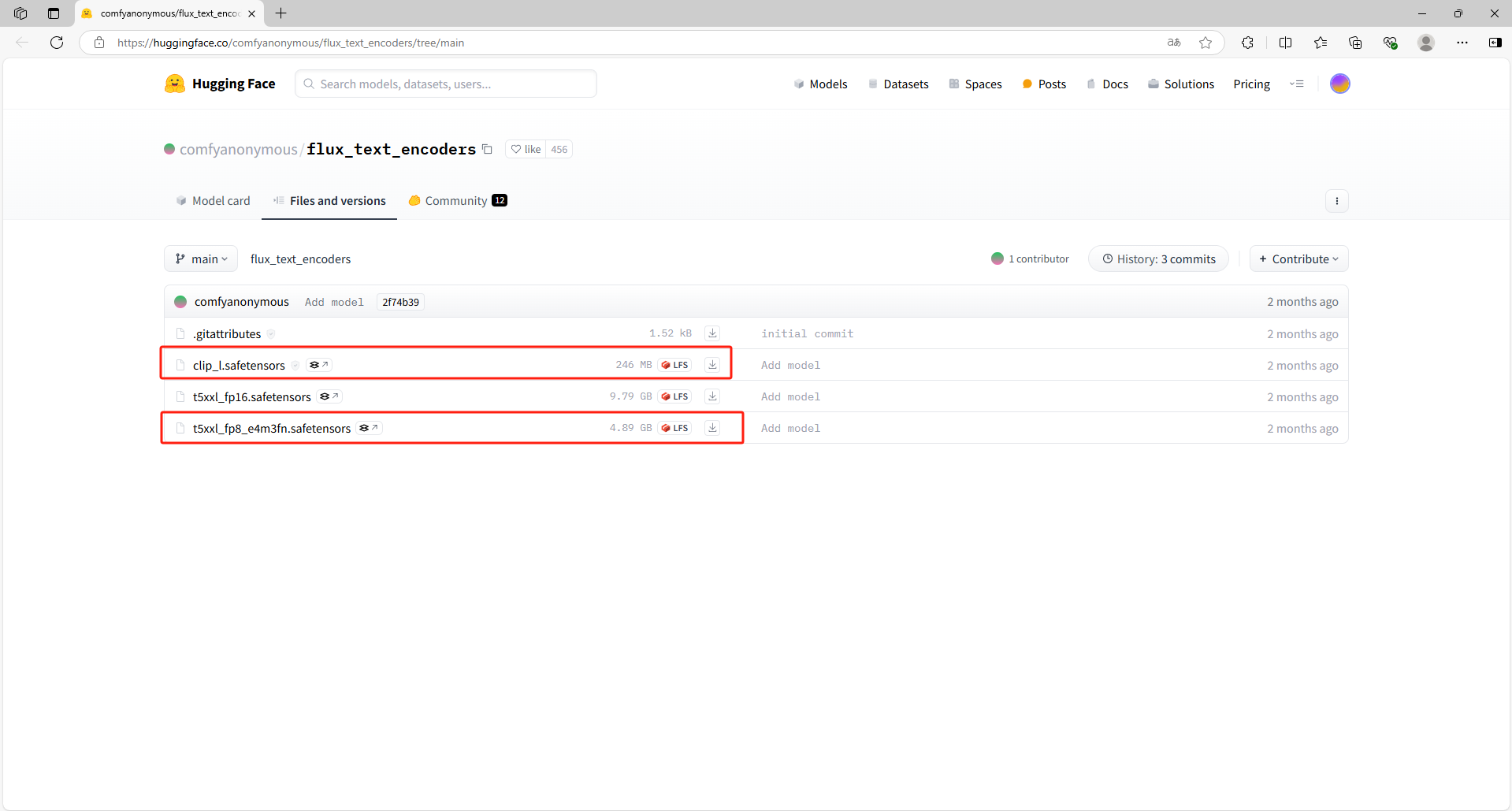
点击地址下载CLIP: https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main
下载 t5xxl_fp16.safetensors 或 t5xxl_fp8_e4m3fn.safetensors (建议选择fp8 版本,如果你显存超过 32G 可选择 fp16 版本)
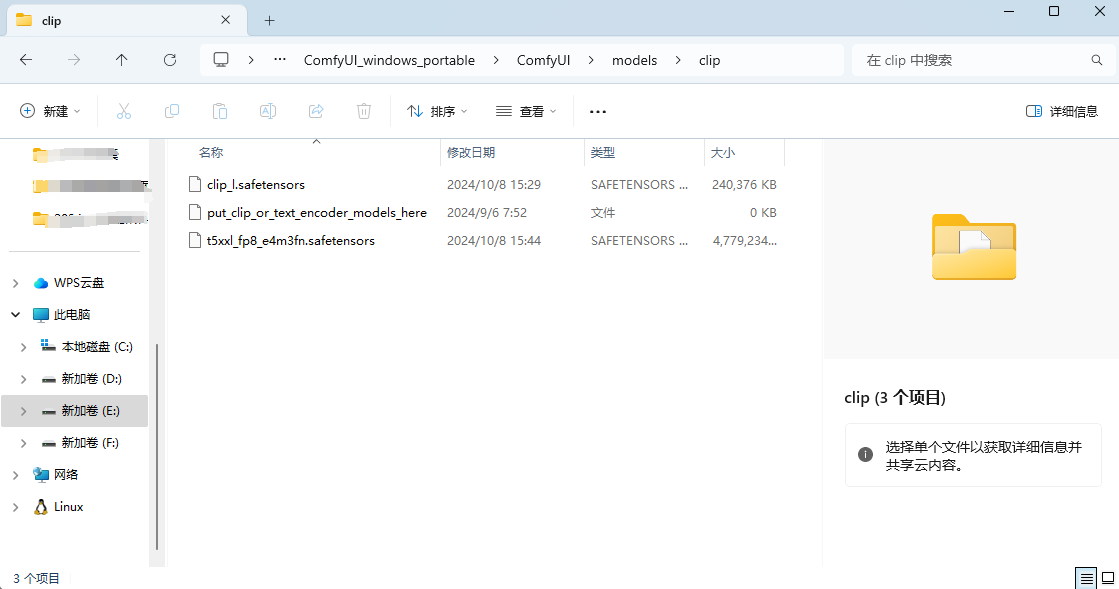
放入到ComfyUI/models/clip/ 目录中
4. 下载 VAE 模型
解压下载VAE模型
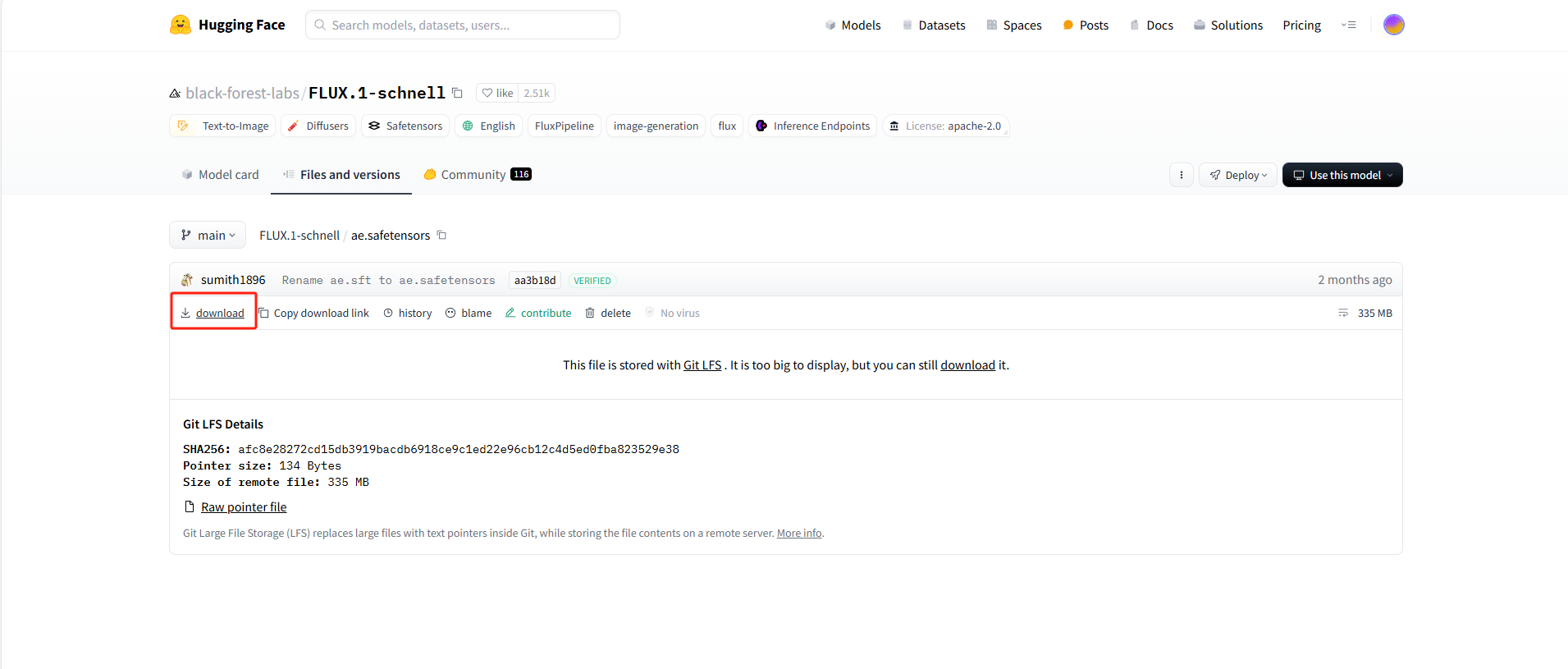
下载到本地后,存放至ComfyUI/models/vae/ 目录
最后回到 ComfyUI 目录,启动运行脚本
重新进入到浏览器当中 http://127.0.0.1:8188
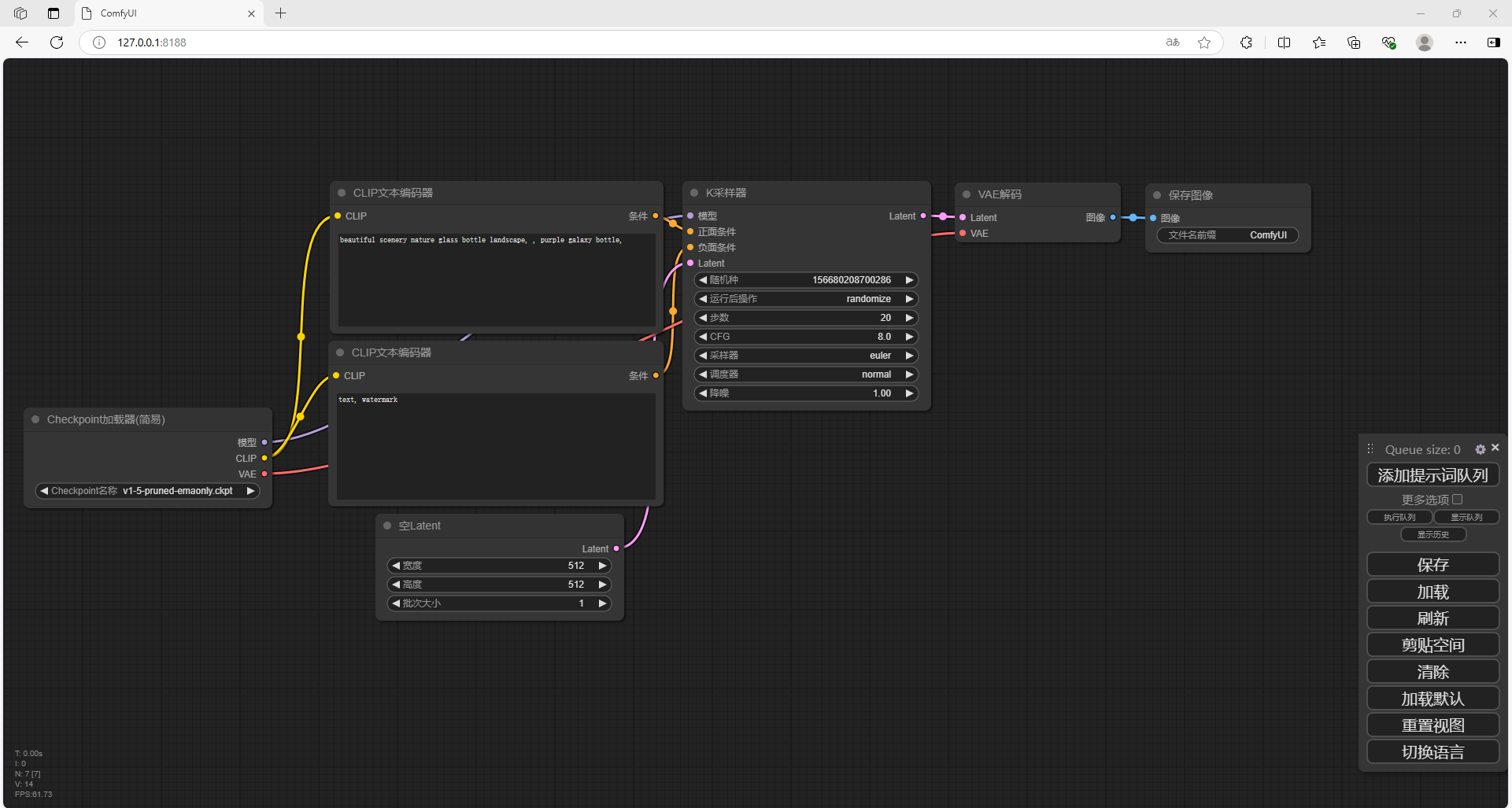
5. 演示文生图
接下来需要调用模型
点击链接:Flux Examples | ComfyUI_examples (comfyanonymous.github.io)
可以看到有Flux Dev版本和Flux Schnell版本,这里和开头一样,我使用的是Flux Schnell版本
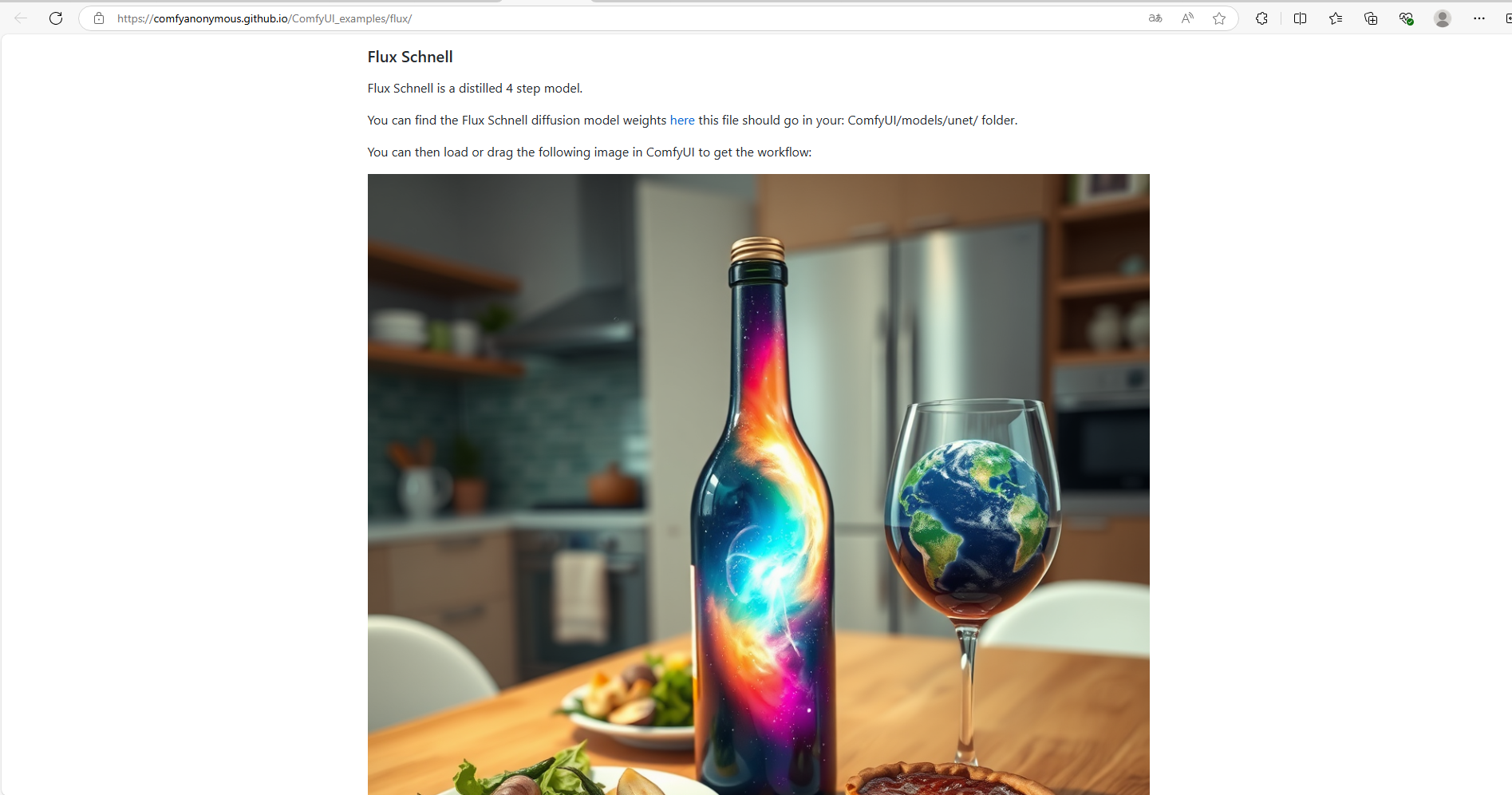
把图片保存到本地
回到 ComfyUI 当中,把图片直接拖入进去,可以看到自动加载模型
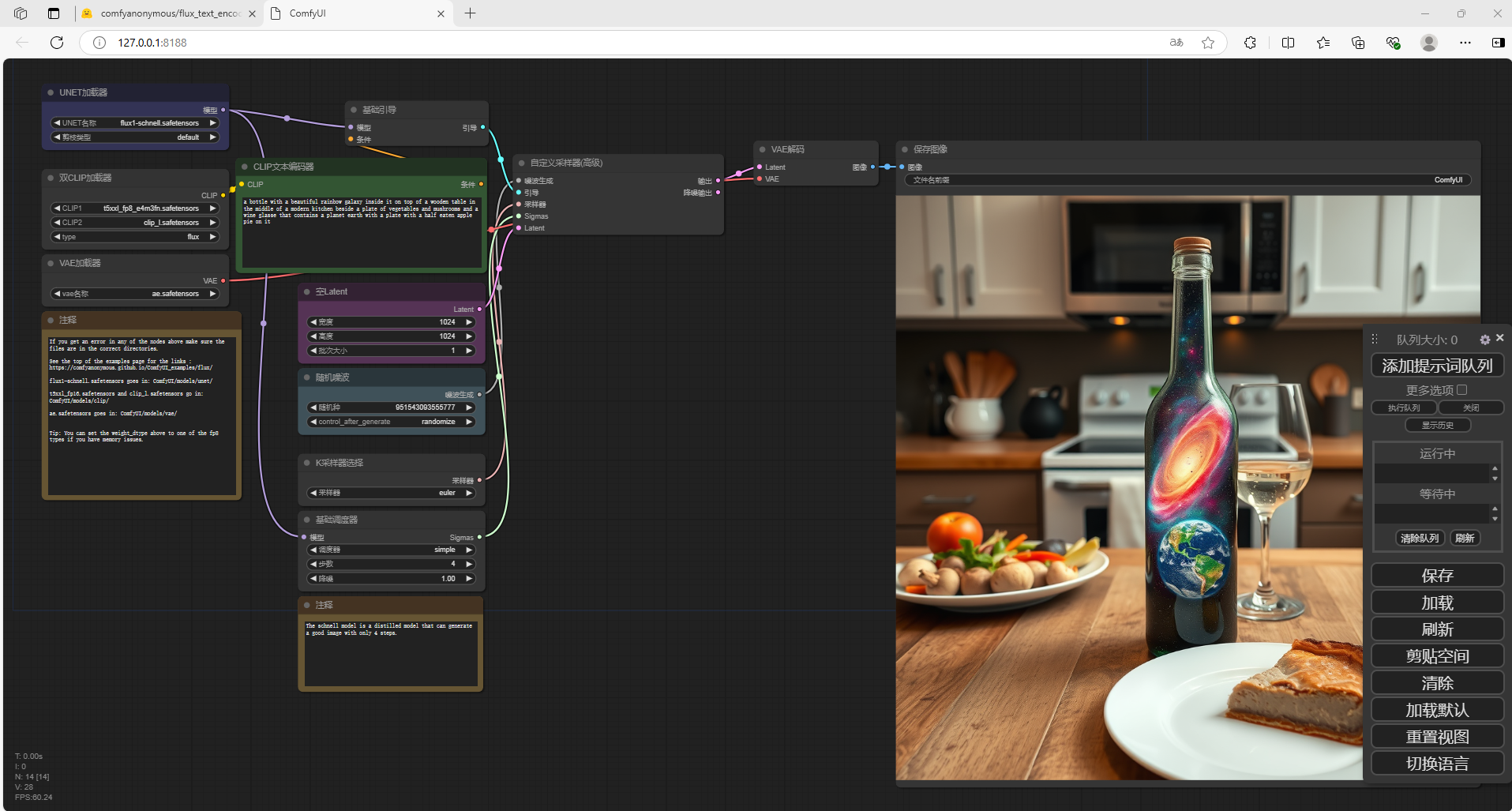
在CLIP文本编码器当中,修改提示词(输入翻译后的英文),点击右侧添加提示词队列
如果出现报错,需要把左侧的加载器修改为fp8
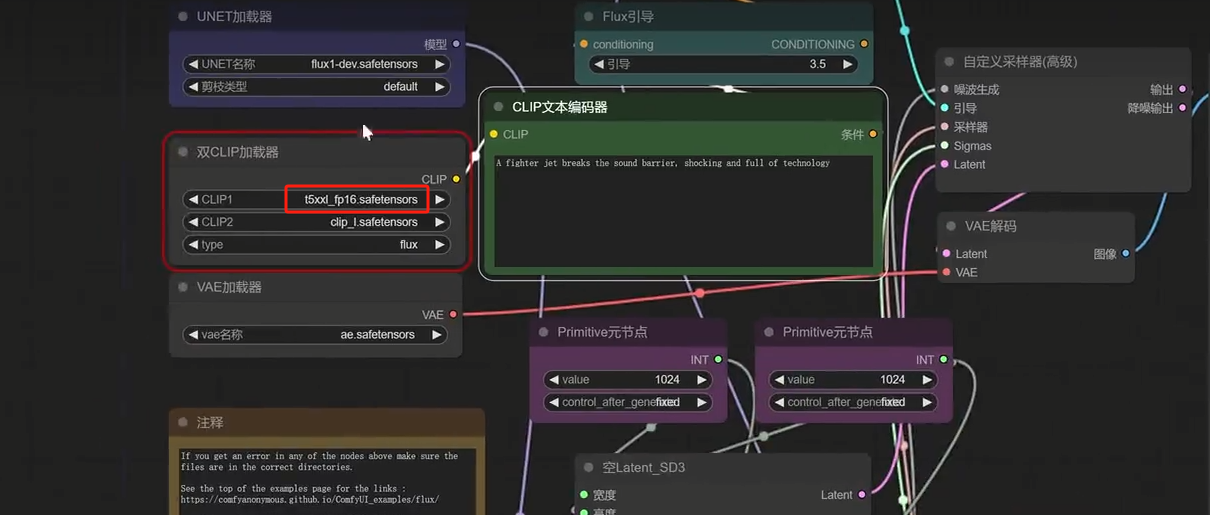
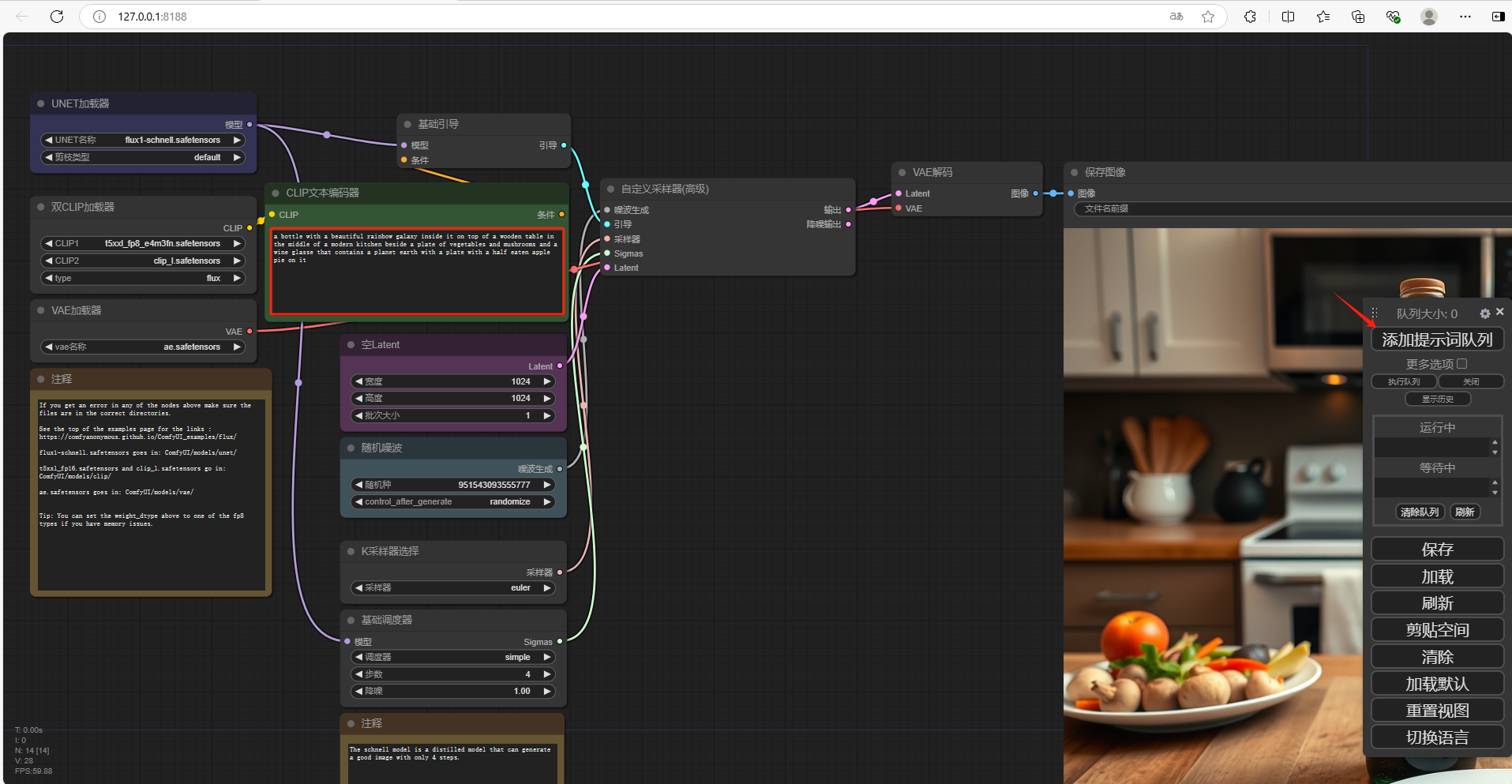
可以看到右侧已经生成了新的图片,我们在本地成功部署了ComfyUI并搭建了 Flux.1 大模型,如果想团队协作多人使用,或者在异地其他设备使用的话就需要结合Cpolar内网穿透实现公网访问,免去了复杂得本地部署过程,只需要一个公网地址直接就可以进入到ComfyUI中来使用 Flux.1文生图。
接下来教大家如何安装Cpolar并且将 Flux.1 实现公网使用。
6. 公网使用 Flux.1 大模型
下面我们在Linux安装Cpolar内网穿透工具,通过Cpolar 转发本地端口映射的http公网地址,我们可以很容易实现远程访问,而无需自己注册域名购买云服务器.下面是安装cpolar步骤
cpolar官网地址: https://www.cpolar.com
使用一键脚本安装命令
sudo curl https://get.cpolar.sh | sudo sh
安装完成后,执行下方命令查看cpolar服务状态:(如图所示即为正常启动)
sudo systemctl status cpolar

Cpolar安装和成功启动服务后,在浏览器上输入ubuntu主机IP加9200端口即:【http://localhost:9200】访问Cpolar管理界面,使用Cpolar官网注册的账号登录,登录后即可看到cpolar web 配置界面,接下来在web 界面配置即可:
6.1 创建远程连接公网地址
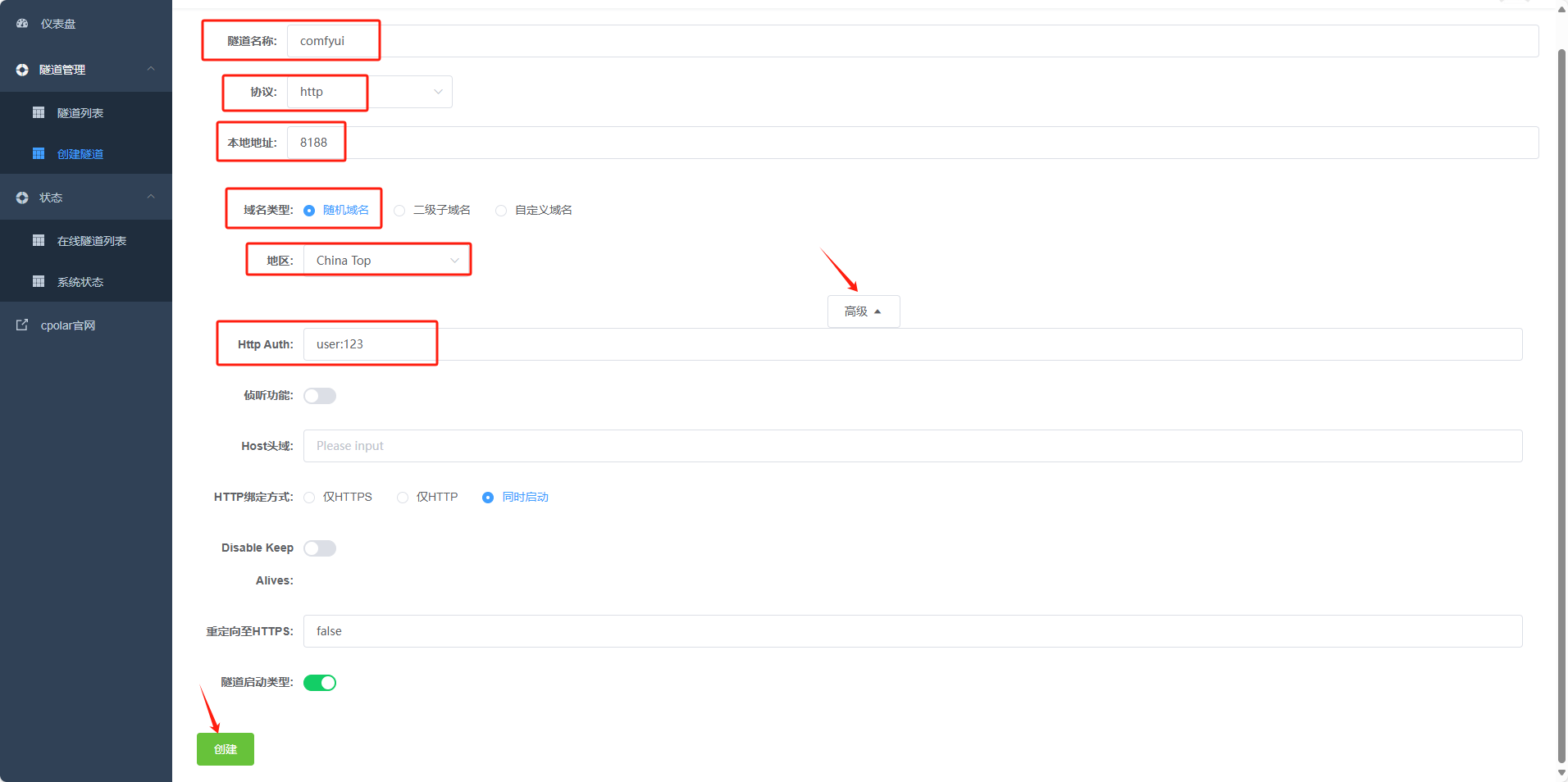
登录cpolar web UI管理界面后,点击左侧仪表盘的隧道管理——创建隧道:
-
隧道名称:可自定义,本例使用了: comfyui注意不要与已有的隧道名称重复
-
协议:http
-
本地地址:8188
-
域名类型:随机域名
-
地区:选择China Top
-
高级:Http Auth:user:123(本例中用户名user 密码123)
点击保存
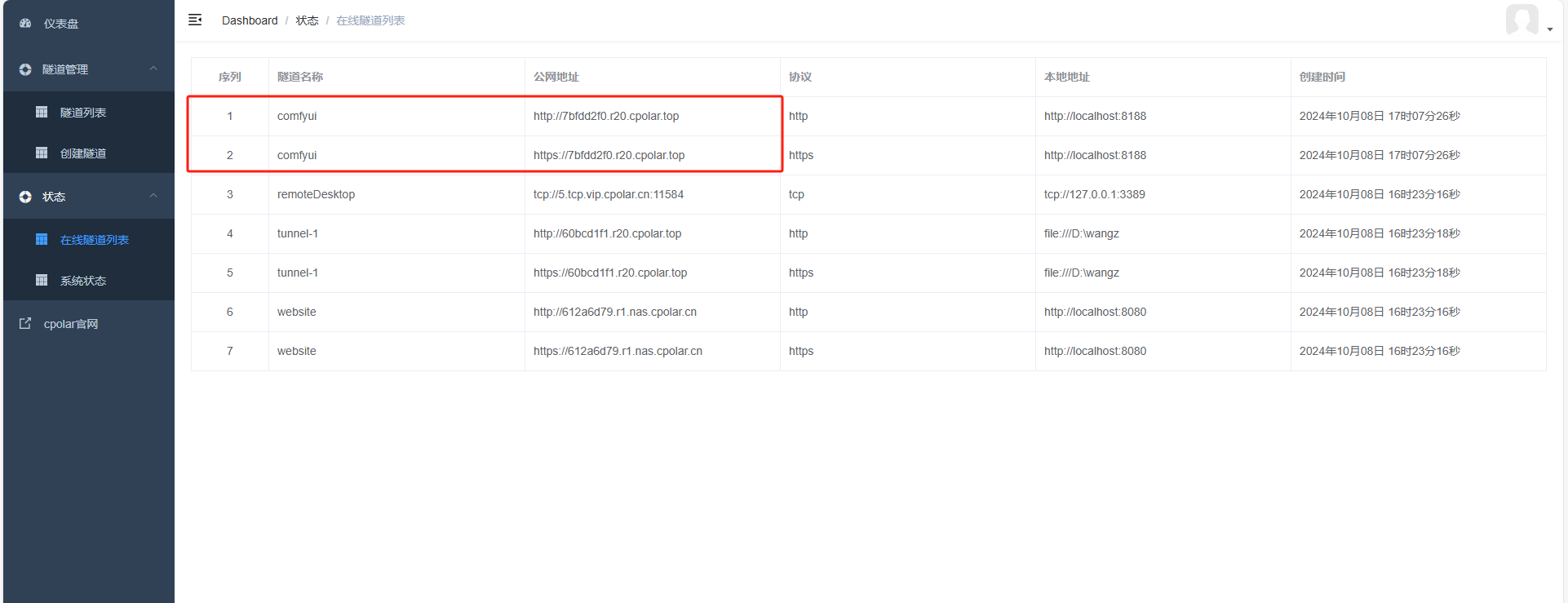
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了两个公网地址,接下来就可以在其他电脑(异地)上,使用任意一个地址在浏览器中访问即可。
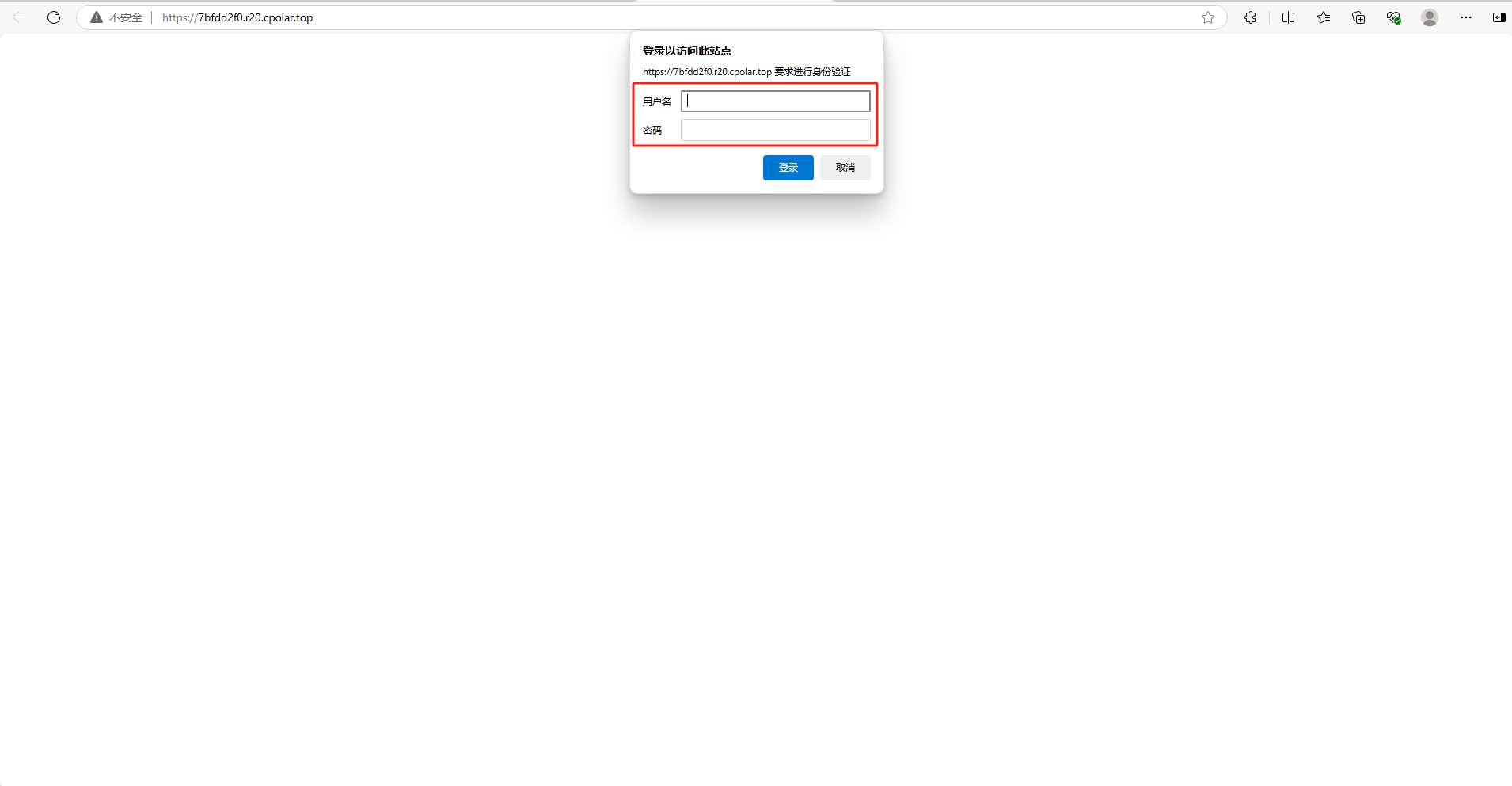
如下图所示,输入设置的用户名及密码(也可以不设置高级,就无需用户名密码直接登入,安全起见,建议配置高级)
可以看到成功实现使用公网地址异地远程访问本地部署的Flux.1大模型!
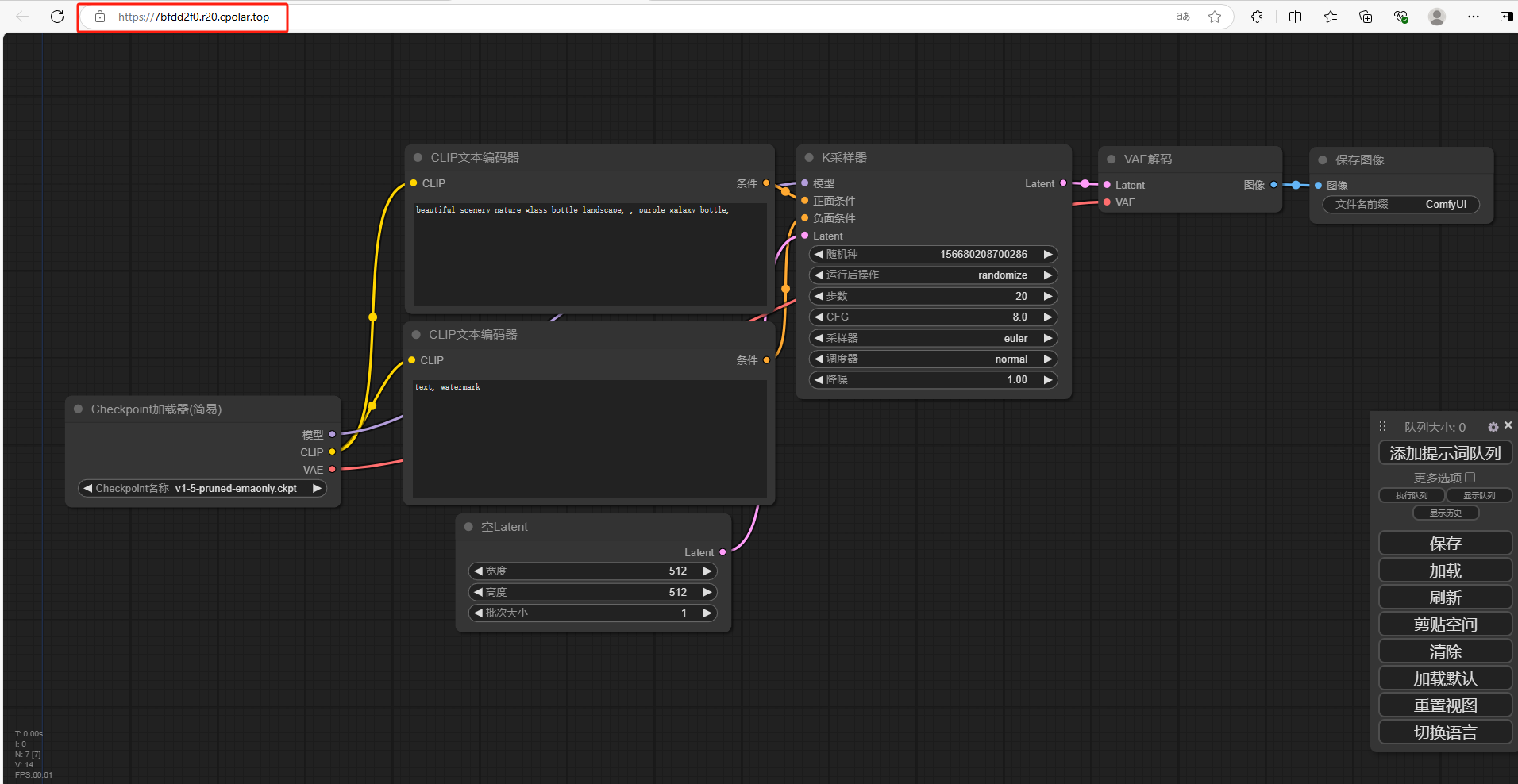
小结
为了方便演示,我们在上边的操作过程中使用了cpolar生成的HTTP公网地址隧道,其公网地址是随机生成的。这种随机地址的优势在于建立速度快,可以立即使用,然而,它的缺点是网址是随机生成,这个地址在24小时内会发生随机变化,更适合于临时使用。
如果有长期远程访问本地 Flux.1 或者其他本地部署的服务的需求,但又不想每天重新配置公网地址,还想地址好看又好记,那我推荐大家选择使用固定的二级子域名方式来远程访问,带宽会更快,使用cpolar在其他用途还可以保留多个子域名,支持多个cpolar在线进程。
7. 固定远程访问公网地址
由于以上使用cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化。
登录cpolar官网,点击左侧的预留,选择保留二级子域名,地区选择china vip top,然后设置一个二级子域名名称,填写备注信息,点击保留。
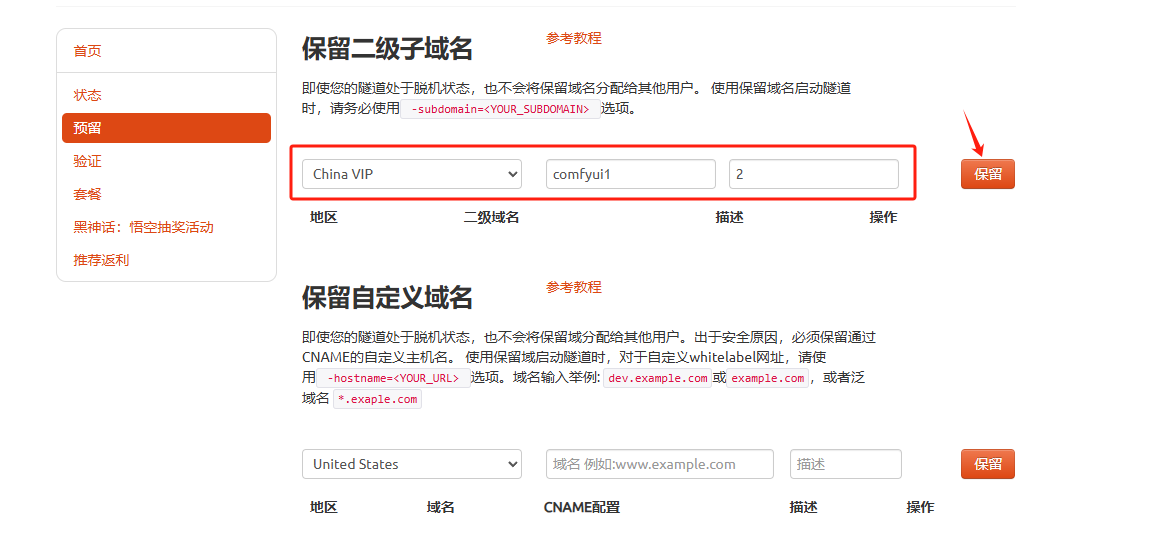
保留成功后复制保留的二级子域名地址:
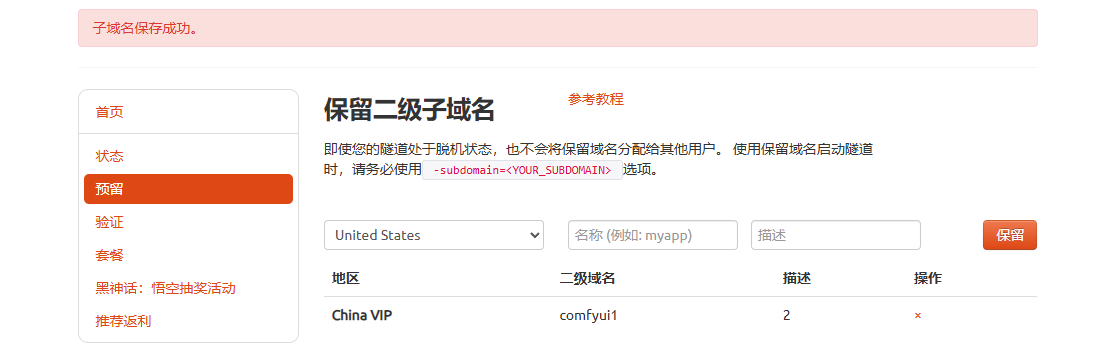
登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑。
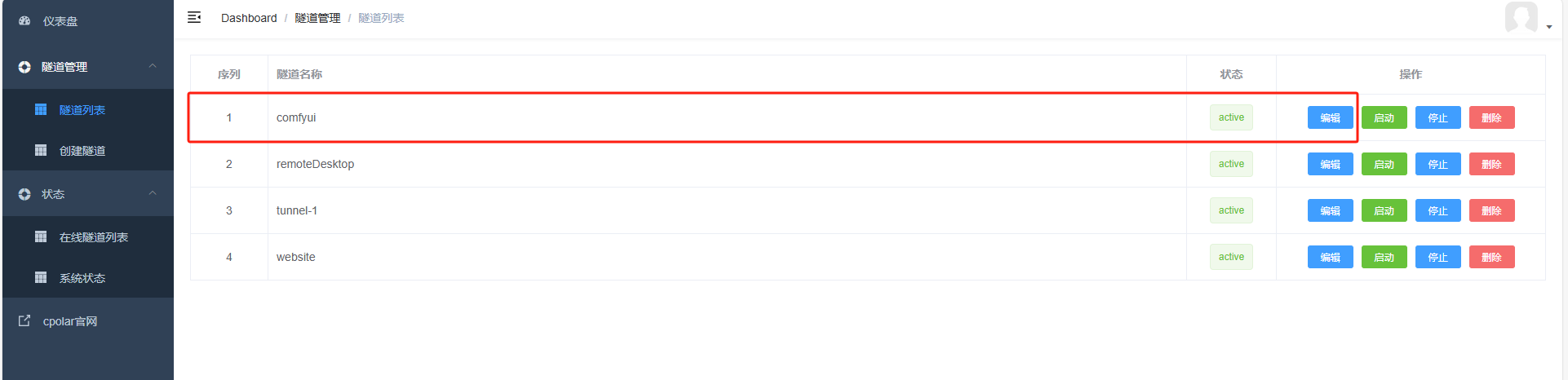
修改隧道信息,将保留成功的二级子域名配置到隧道中
-
域名类型:选择二级子域名
-
Sub Domain:填写保留成功的二级子域名
-
地区: China VIP
点击更新
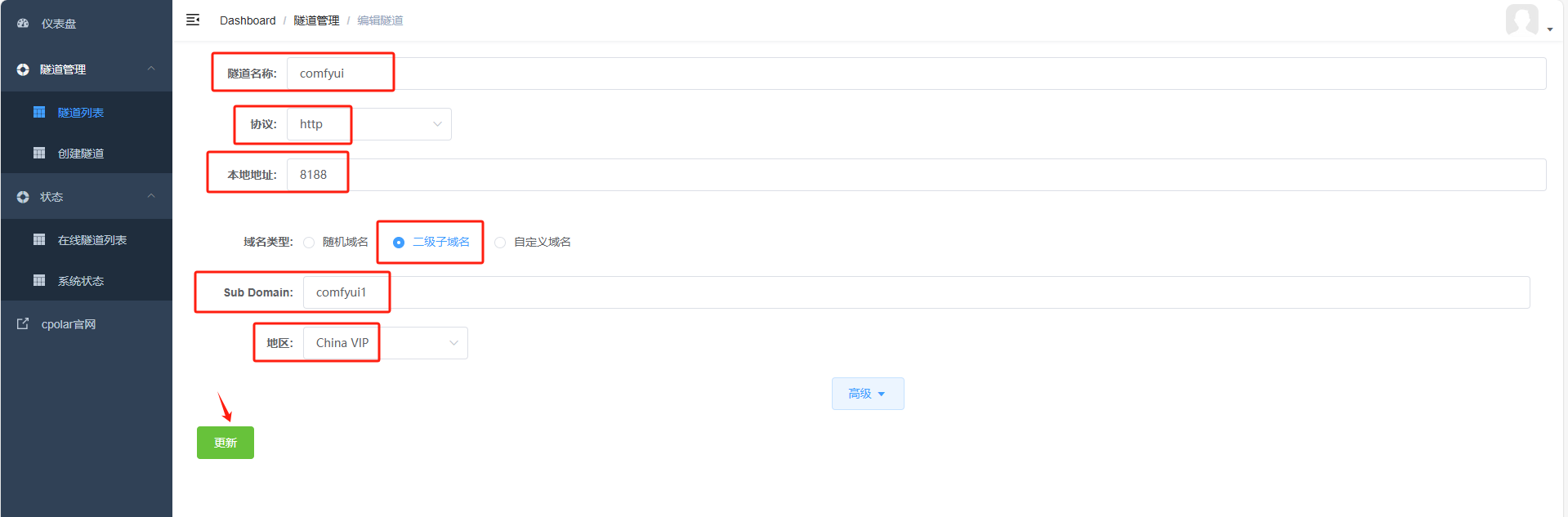
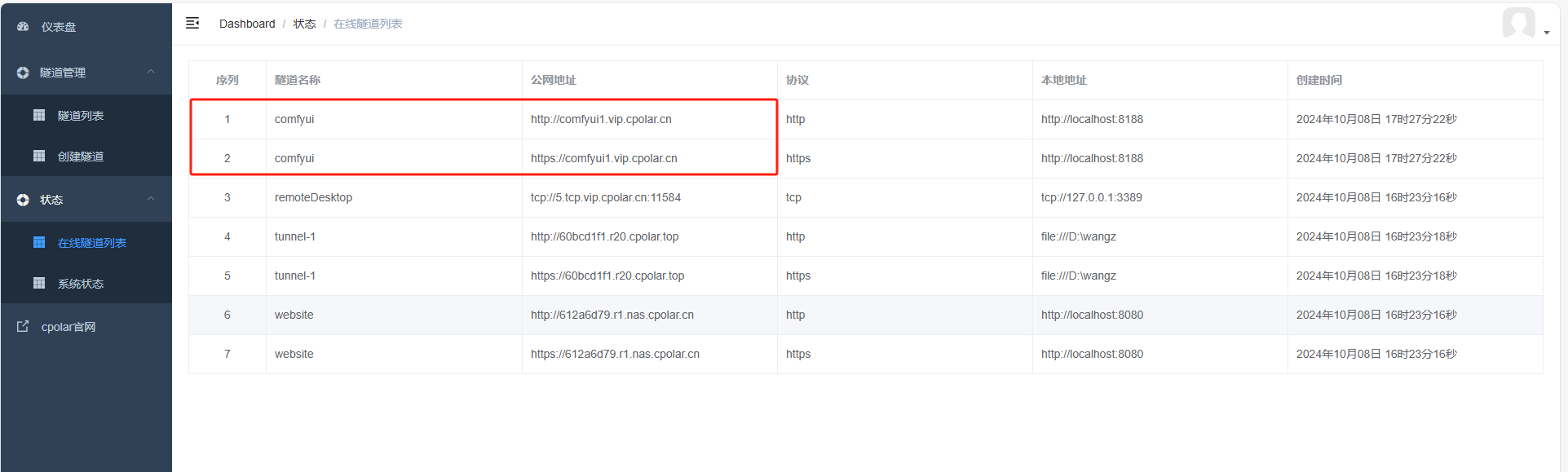
更新完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的二级子域名名称。
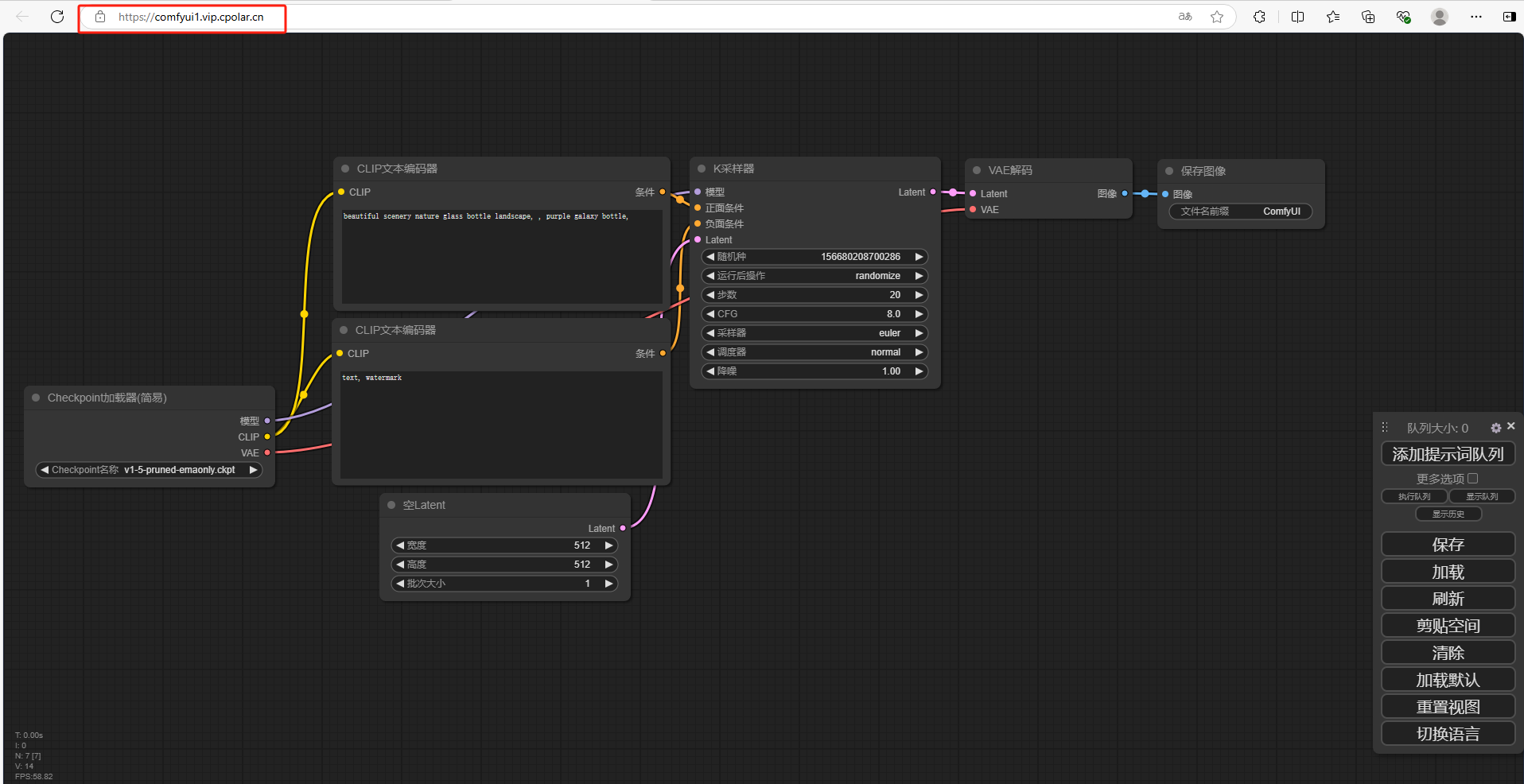
最后,我们使用固定的公网地址访问 ComfyUI 可以看到访问成功,一个永久不会变化的远程访问方式即设置好了.
通过本文的详细介绍和步骤指南,相信你已经掌握了如何在本地部署并使用 Flux.1 进行图像生成的方法。结合 Cpolar 的内网穿透功能,你可以在任何地方轻松实现远程生图操作。希望这些内容能让你在创意和技术领域更加得心应手!如果你有任何疑问或需要进一步的帮助,请随时留言交流,我们在这里等你哦!