重庆市住房和城乡建设厅网站首页如何用wd做网站设计
文章目录
- 前言
- 1.使用下划线开头忽略未使用的变量
- 2. 变量解构
- 3.常量
- 4.变量遮蔽(shadowing)
- 5. 类似println!("{}", x); 为啥加感叹号
- 6.单元类型
- 7. -> 运算符到哪去了?
- 总结
前言
Rust 学习系列,记录一些rust使用小技巧
1.使用下划线开头忽略未使用的变量
如果你创建了一个变量却不在任何地方使用它,Rust 通常会给你一个警告。这时你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头:
fn main() {let _x = 5;let y = 10;
}
在线运行一下;

使用了下划线作为变量名开头的不会警告;
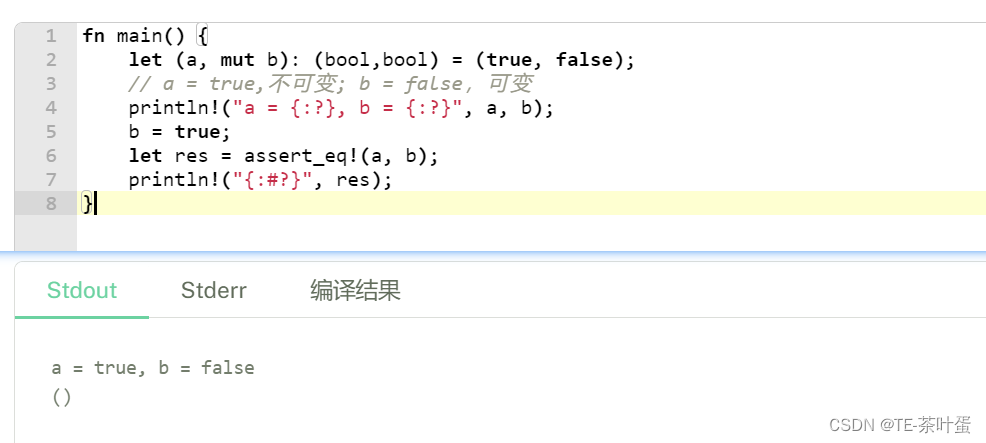
2. 变量解构
let 表达式不仅仅用于变量的绑定,还能进行复杂变量的解构.
3.常量
- 常量不允许使用 mut。常量不仅仅默认不可变,而且自始至终不可变,因为常量在编译完成后,已经确定它的值。
- 常量使用 const 关键字而不是 let 关键字来声明,并且值的类型必须标注。
- Rust 常量的命名约定是全部字母都使用大写,并使用下划线分隔单词,另外对数字字面量可插入下划线以提高可读性
4.变量遮蔽(shadowing)
在Rust中,变量遮蔽(shadowing)和mut关键字有一些区别。
变量遮蔽是指在同一个作用域中,使用相同的名称定义一个新的变量,从而遮蔽之前定义的同名变量。这意味着新定义的变量会覆盖之前的变量,并且可以改变变量的类型。例如:
let x = 5;
let x = "hello";
println!("{}", x); // 输出 "hello"
在上面的例子中,变量x被遮蔽了两次,首先定义为整数类型,然后定义为字符串类型。每次定义都创建一个新的变量,并且新变量的作用域覆盖了之前变量的作用域。
而mut关键字用于声明一个可变变量。在使用mut声明的变量中,可以改变变量的值,但是不能改变变量的类型。例如:
let mut x = 5;
x = 10;
println!("{}", x); // 输出 "10"
在这个例子中,变量x被声明为可变变量,并且可以通过赋值语句改变它的值。但是,由于变量的类型在声明时已经确定,所以不能改变其类型。
变量遮蔽(shadowing)允许在同一个作用域内使用相同名称的变量,并且可以改变变量的类型,而mut关键字只允许改变变量的值,但不能改变变量的类型。
5. 类似println!(“{}”, x); 为啥加感叹号
在Rust中,感叹号!通常用于调用宏(macro)。println!是一个宏的示例,它可以将文本打印到标准输出。
使用感叹号的目的是告诉编译器这是一个宏调用,而不是普通函数调用。这是为了区分宏和函数,因为它们在语法和执行方式上有很大的不同。
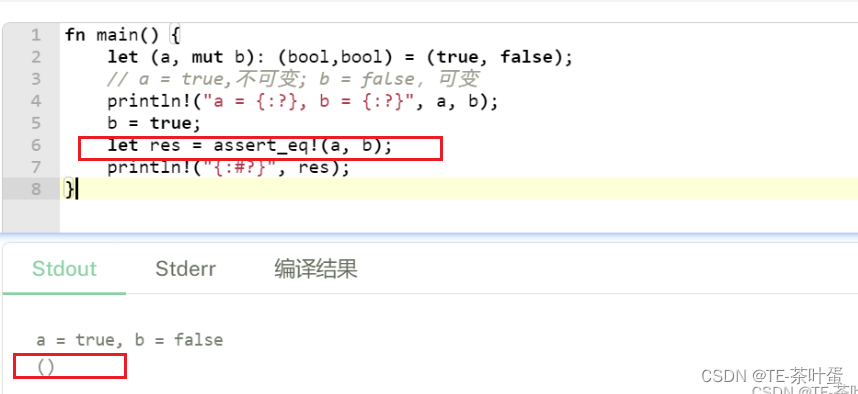
6.单元类型
单元类型就是 () ,对,你没看错,就是 () ,唯一的值也是 () ,大家已经看到过很多次 fn main() 函数的使用吧?那么这个函数返回什么呢?
没错, main 函数就返回这个单元类型 (),你不能说 main 函数无返回值,因为没有返回值的函数在 Rust 中是有单独的定义的:发散函数( diverge function ),顾名思义,无法收敛的函数。
例如常见的 println!() 的返回值也是单元类型 ()。
再比如,你可以用 () 作为 map 的值,表示我们不关注具体的值,只关注 key。 这种用法和 Go 语言的 struct{} 类似,可以作为一个值用来占位,但是完全不占用任何内存。
这里估计也是单元类型。
7. -> 运算符到哪去了?
-> 运算符到哪去了?
在 C/C++ 语言中,有两个不同的运算符来调用方法:. 直接在对象上调用方法,而 -> 在一个对象的指针上调用方法,这时需要先解引用指针。换句话说,如果 object 是一个指针,那么 object->something() 和 (*object).something() 是一样的。
Rust 并没有一个与 -> 等效的运算符;相反,Rust 有一个叫 自动引用和解引用的功能。方法调用是 Rust 中少数几个拥有这种行为的地方。
他是这样工作的:当使用 object.something() 调用方法时,Rust 会自动为 object 添加 &、&mut 或 * 以便使 object 与方法签名匹配。也就是说,这些代码是等价的:
p1.distance(&p2);
(&p1).distance(&p2);
第一行看起来简洁的多。这种自动引用的行为之所以有效,是因为方法有一个明确的接收者———— self 的类型。在给出接收者和方法名的前提下,Rust 可以明确地计算出方法是仅仅读取(&self),做出修改(&mut self)或者是获取所有权(self)。事实上,Rust 对方法接收者的隐式借用让所有权在实践中更友好。
总结
参考 :Rust 学习书籍