idea
jdk17
spring boot 3.0.7
mysql 8.0
orm 框架 是否支持xml 是否支持 Lambda 对比版本 mybatis ☑️ ☑️ 3.5.4 sqltoy ☑️ ☑️ 5.2.98 lazy ✖️ ☑️ 1.2.4-JDK17-SNAPSHOT mybatis-flex ☑️ ☑️ 1.8.0 easy-query ✖️ ☑️ 1.10.31
CREATE TABLE ` sys_user` ( ` column_name` varchar ( 255 ) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '额外字段' , ` create_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间' , ` id` bigint NOT NULL AUTO_INCREMENT COMMENT '用户ID' , ` is_deleted` tinyint ( 1 ) DEFAULT NULL COMMENT 'null' , ` password` varchar ( 255 ) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '密码' , ` scope` varchar ( 255 ) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 'null' , ` status` tinyint ( 1 ) DEFAULT NULL COMMENT '状态' , ` update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间' , ` username` varchar ( 255 ) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '用户名' , PRIMARY KEY ( ` id` ) USING BTREE , UNIQUE KEY ` s_u` ( ` scope` , ` username` )
) ENGINE = InnoDB AUTO_INCREMENT = 9223371632070323791 DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_general_ci;
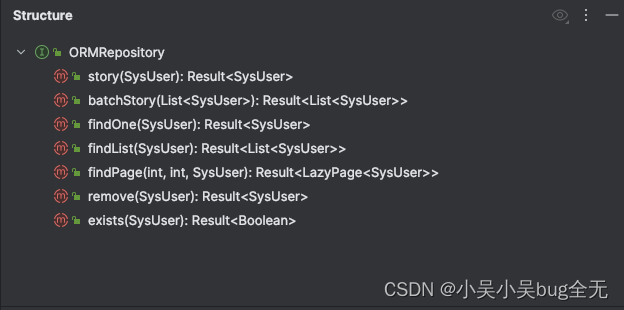
声明 ORMRepository 接口提供对应增删改查方法
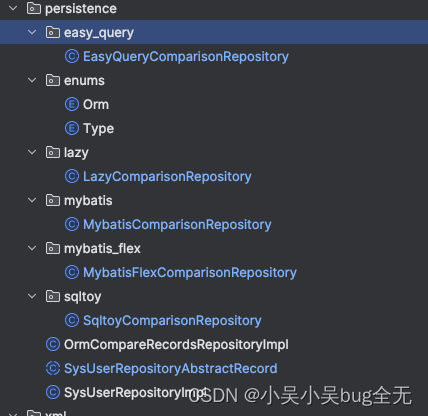
声明 ORMComparisonRepository接口 继承 ORMRepository 下游由不同ORM实现
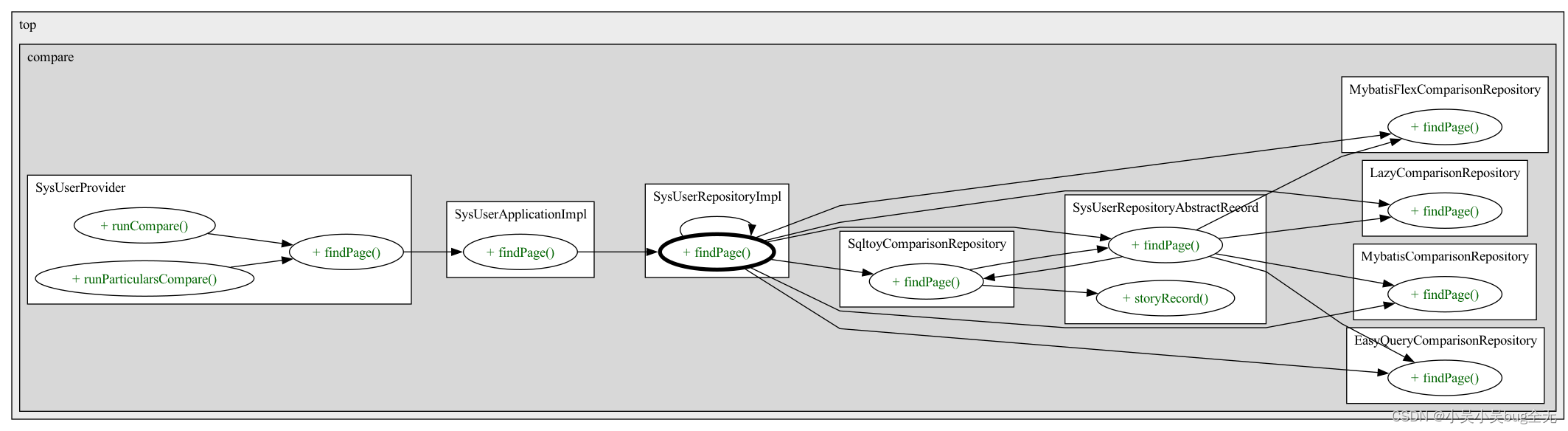
声明 SysUserRepository 接口 继承 ORMRepository 用于循环调用不同orm实现方法执行方法测试产生测试结果
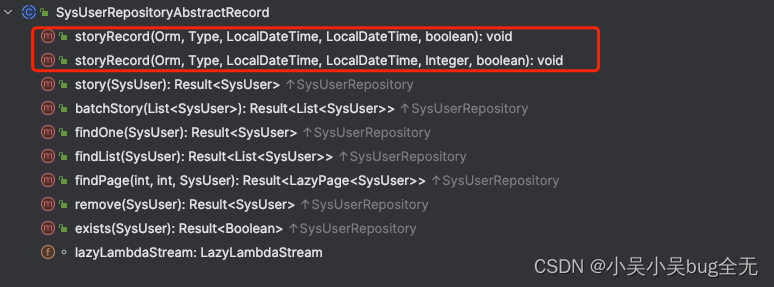
声明抽象类 SysUserRepositoryAbstractRecord 继承 ORMComparisonRepository 并且提供对应的框架执行结果存储
不同ORM框架mybatis、sqltoy、Lazy、easy-query 创建 ORMComparisonRepository 的实现
不同 ORM 操作数据的实现在 项目启动后使用浏览器打开 http://localhost:1003/sys/user/run-compare
项目启动后使用浏览器打开 http://localhost:1003/sys/user/run-particulars-compare
清空需要插入表中所有数据
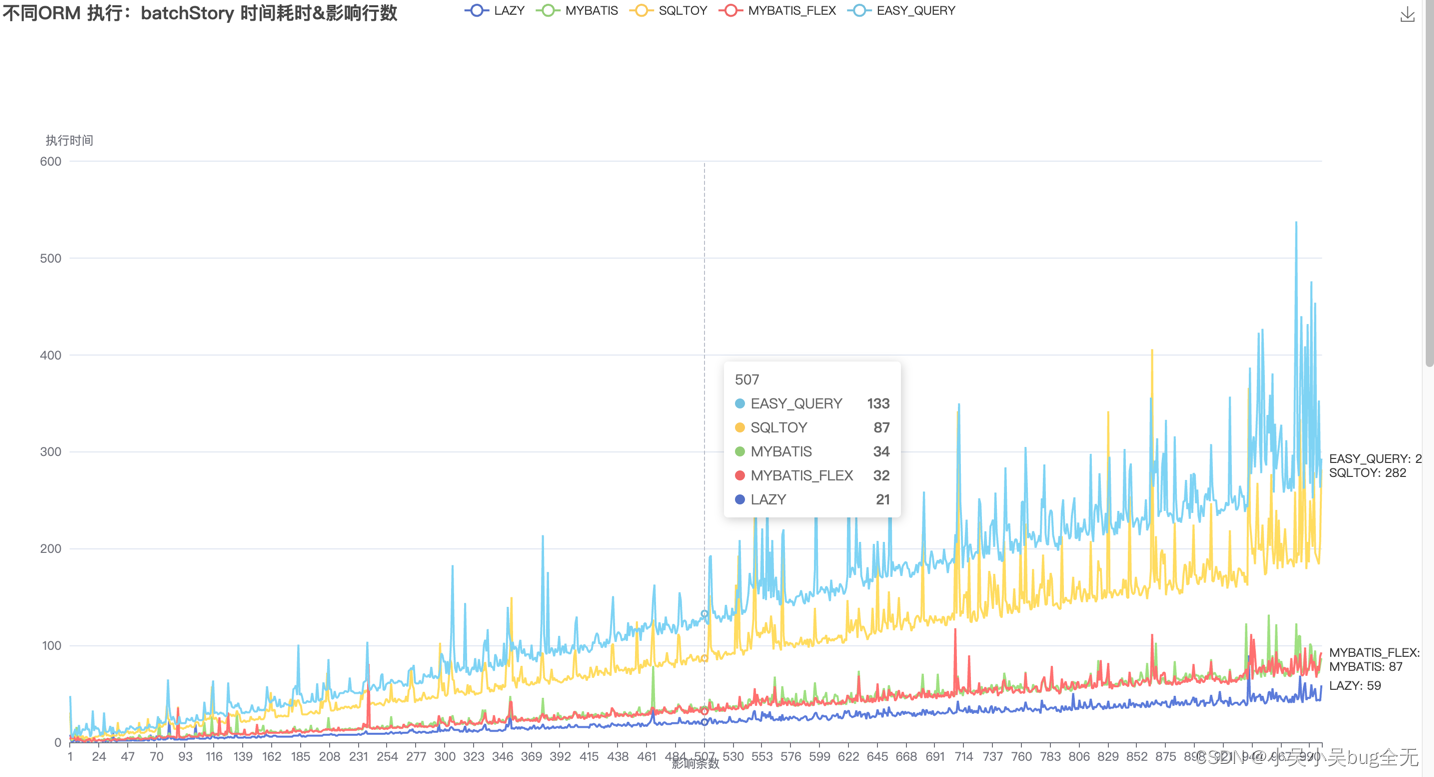
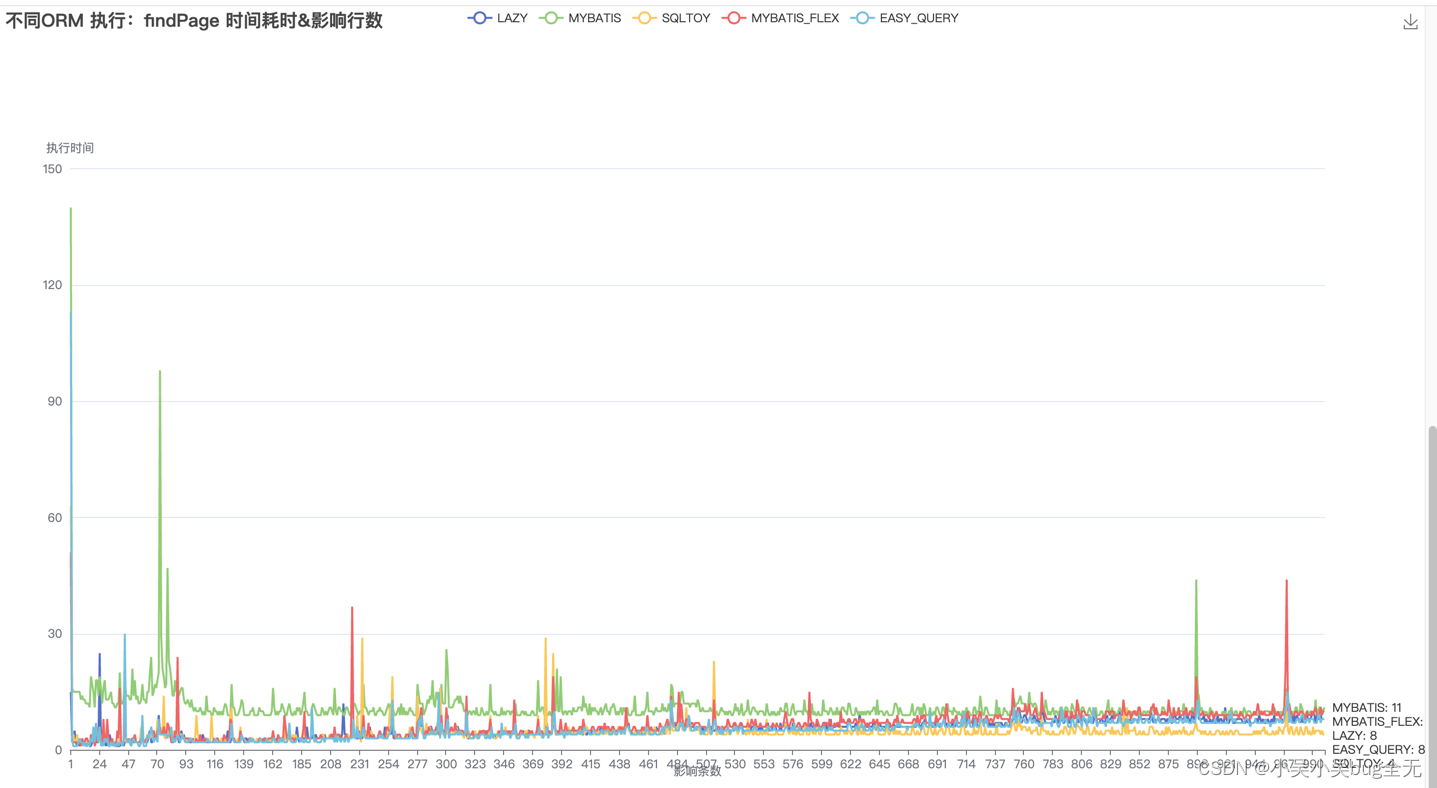
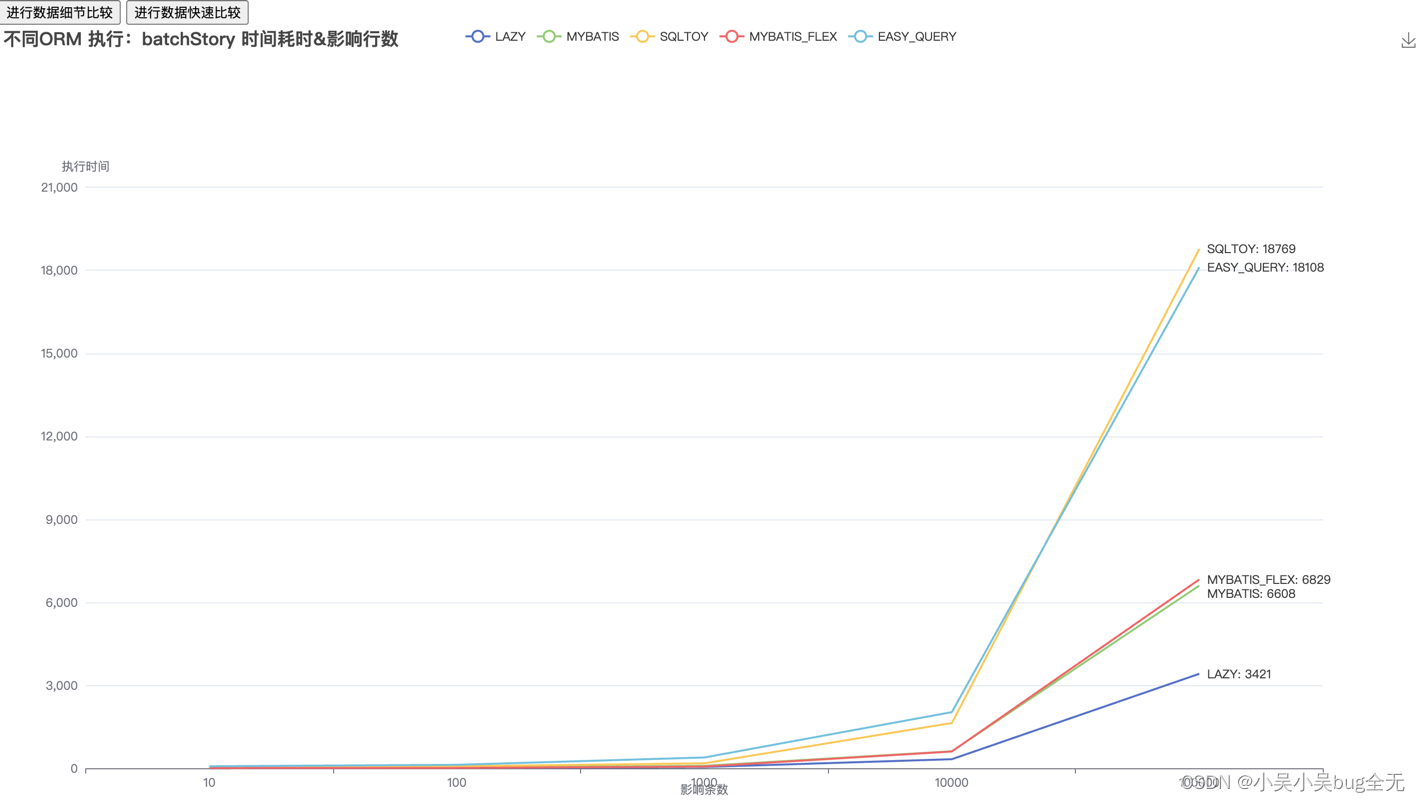
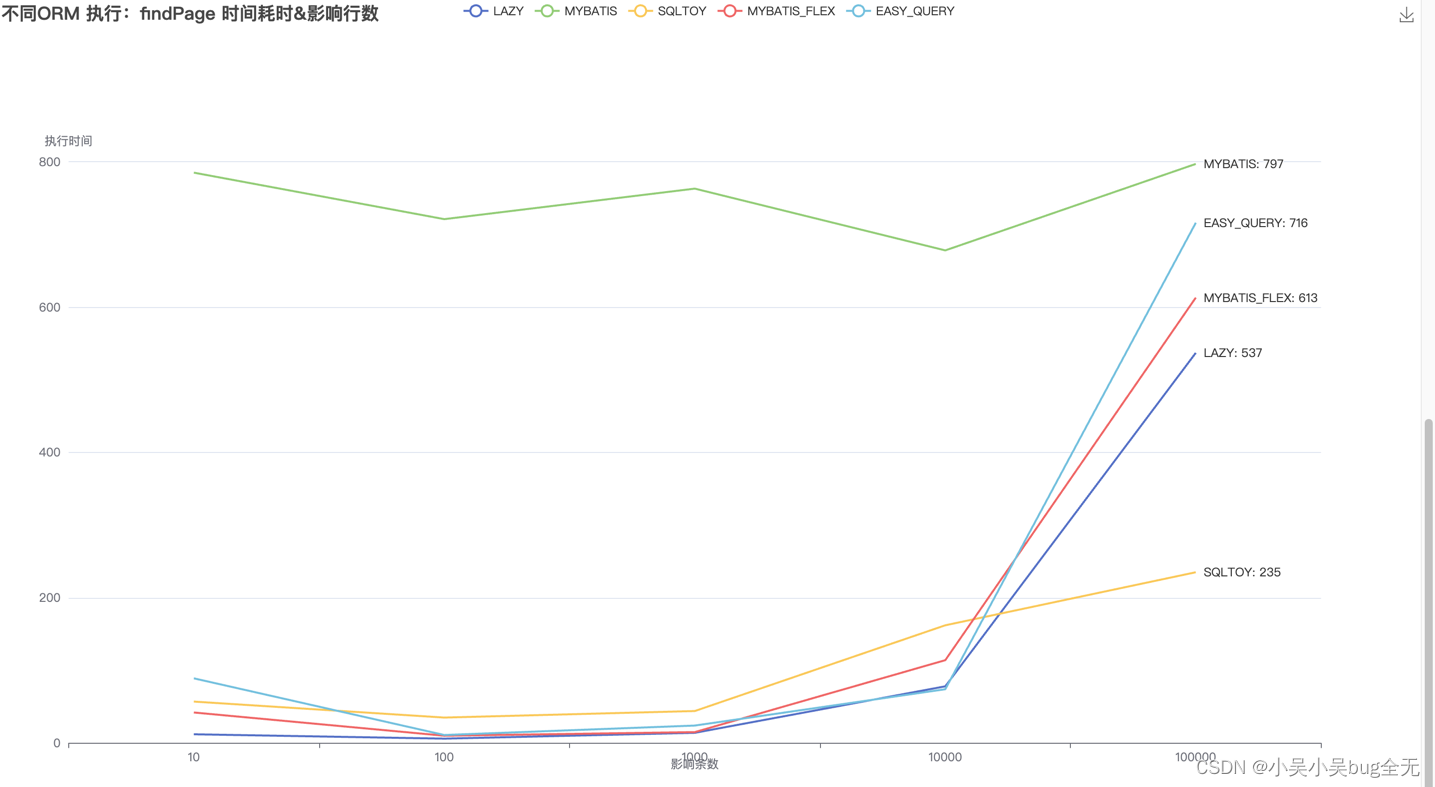
通过三种ORM框架进行数据批量新增、而后进行分页查询,记录消耗时间,输出md文档
MYBATIS_FLEX(batchStory) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 3毫秒 11毫秒 61毫秒 633毫秒 6985毫秒
MYBATIS(batchStory) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 6毫秒 8毫秒 59毫秒 733毫秒 7136毫秒
LAZY(batchStory) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 8毫秒 9毫秒 39毫秒 385毫秒 3987毫秒
EASY_QUERY(batchStory) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 31毫秒 57毫秒 311毫秒 1956毫秒 20898毫秒
SQLTOY(batchStory) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 8毫秒 26毫秒 183毫秒 1610毫秒 18832毫秒
MYBATIS_FLEX(findPage) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 10毫秒 19毫秒 30毫秒 100毫秒 668毫秒
MYBATIS(findPage) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 1231毫秒 888毫秒 1114毫秒 819毫秒 838毫秒
LAZY(findPage) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 8毫秒 7毫秒 17毫秒 196毫秒 675毫秒
EASY_QUERY(findPage) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 15毫秒 5毫秒 18毫秒 96毫秒 638毫秒
SQLTOY(findPage) 影响行数:10 影响行数:100 影响行数:1000 影响行数:10000 影响行数:100000 执行时间: 36毫秒 35毫秒 37毫秒 86毫秒 229毫秒
一万条数据以内 性能由高到低 mybatis-flex 、mybatis、lazy 性能趋于一致 sqltoy、easy-query 耗时出现明显起伏 十万数据时,处理时间由快到慢依次是: lazy、mybatis、mybatis-flex、easy-query、sqltoy 一万条数据以内 性能由高到低 lazy、mybatis-flex 、sqltoy、easy-query、mybatis 十万数据时,处理时间由快到慢依次是: sqltoy、lazy、mybatis-flex、easy-query、mybatis