枣阳建设局网站快速建站官网
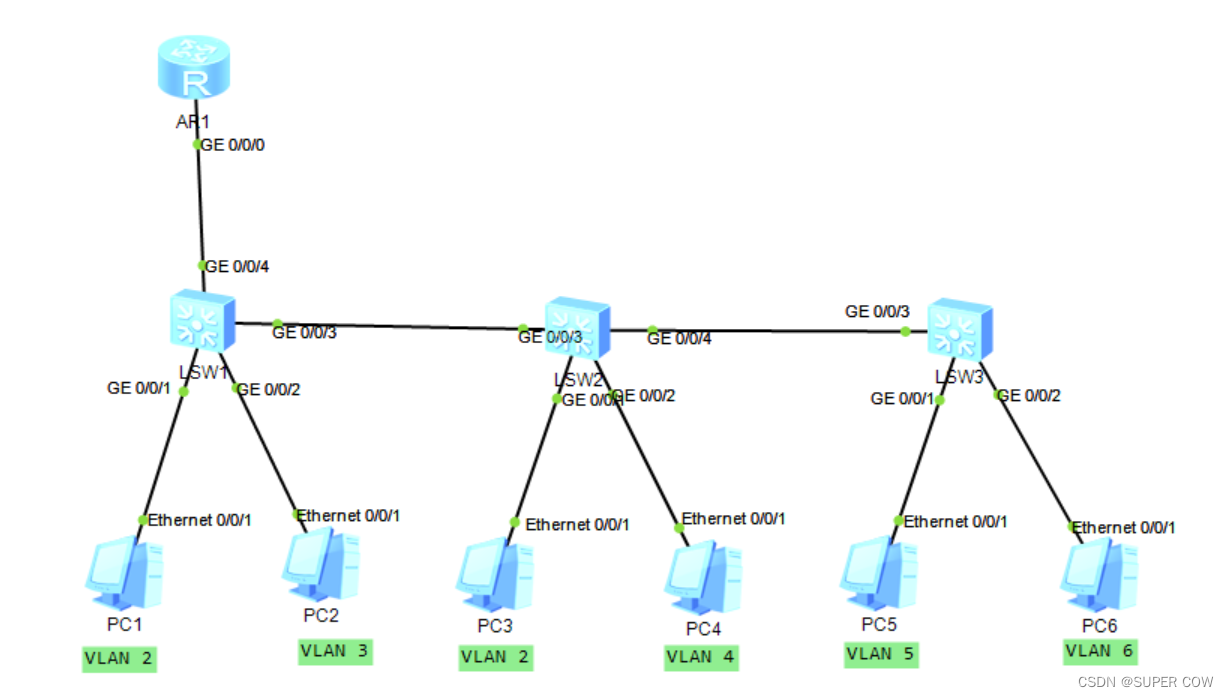
一、实验拓扑图
二、实验需求
1、PC1和PC3所在接口为access,属于vlan2;PC2/4/5/6处于同一网段,其中PC2可以访问PC4/5/6;但PC4可以访问PC5,不能访问PC6
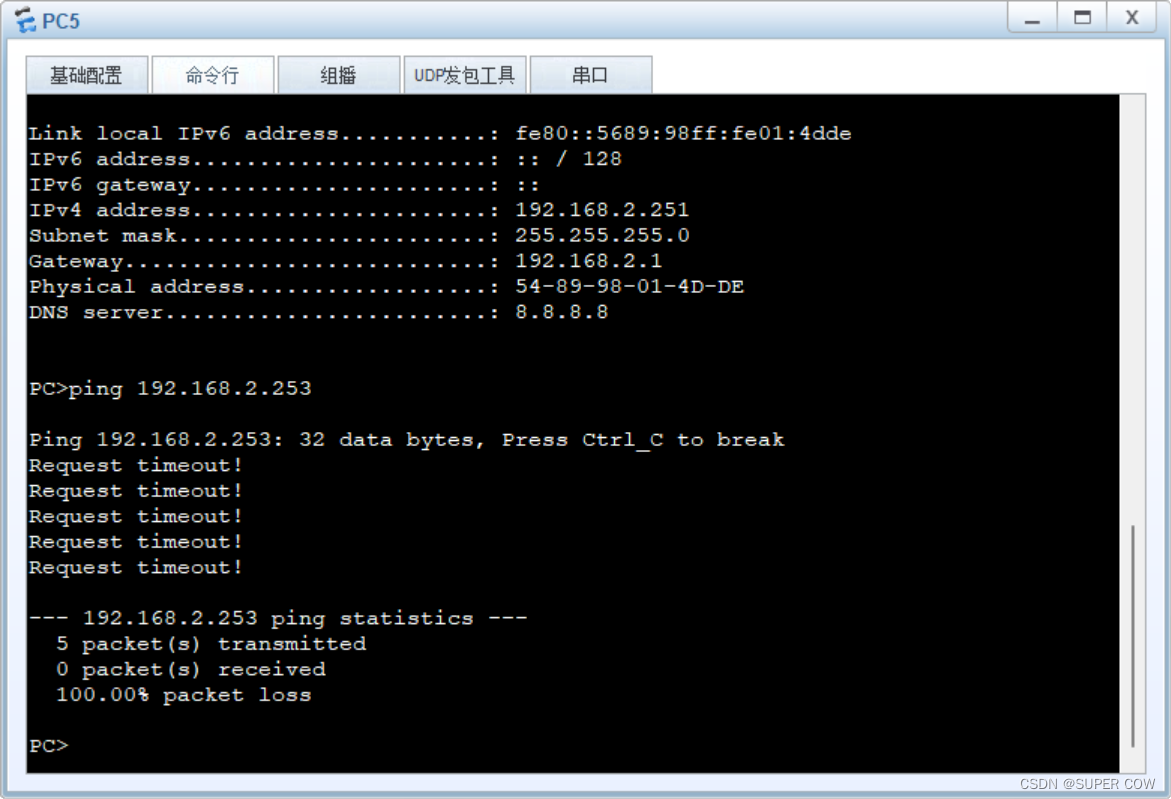
2、PC5不能访问PC6
3、PC1/3与PC2/4/5/6/不在同一网段
4、所有PC通过DHCP获取IP地址,且PC1/3可以正常访问PC2/4/5/6
三、实验配置
1、创建VLAN
#SW1
[SW1]vlan batch 2 to 6
[SW1]int g 0/0/1
[SW1-GigabitEthernet0/0/1]port link-type access
[SW1-GigabitEthernet0/0/1]port default vlan 2
[SW1-GigabitEthernet0/0/1]int g 0/0/2
[SW1-GigabitEthernet0/0/2]port hybrid pvid vlan 3
[SW1-GigabitEthernet0/0/2]port hybrid untagged vlan 3 to 6#SW2
[SW2]vlan batch 2 to 6
[SW2]int g 0/0/1
[SW2-GigabitEthernet0/0/1]port link-type access
[SW2-GigabitEthernet0/0/1]port default vlan 2
[SW2-GigabitEthernet0/0/1]int g 0/0/2
[SW2-GigabitEthernet0/0/2]port hybrid pvid vlan 4
[SW2-GigabitEthernet0/0/2]port hybrid untagged vlan 3 to 5#SW3
[SW3]vlan batch 2 to 6
[SW3]int g 0/0/1
[SW3-GigabitEthernet0/0/1]port hybrid pvid vlan 5
[SW3-GigabitEthernet0/0/1]port hybrid untagged vlan 2 to 5
[SW3-GigabitEthernet0/0/1]int g 0/0/2
[SW3-GigabitEthernet0/0/2]port hybrid pvid vlan 6
[SW3-GigabitEthernet0/0/2]port hybrid untagged vlan 1 to 3
[SW3-GigabitEthernet0/0/2]port hybrid untagged vlan 62、配置trunk
#SW1
[SW1]int g 0/0/3
[SW1-GigabitEthernet0/0/3]port link-type trunk
[SW1-GigabitEthernet0/0/3]port trunk allow-pass vlan all#SW2
[SW2-GigabitEthernet0/0/2]int g 0/0/3
[SW2-GigabitEthernet0/0/3]port link-type trunk
[SW2-GigabitEthernet0/0/3]port trunk allow-pass vlan all
[SW2-GigabitEthernet0/0/3]int g 0/0/4
[SW2-GigabitEthernet0/0/4]port link-type trunk
[SW2-GigabitEthernet0/0/4]port trunk allow-pass vlan all#SW3
[SW3-GigabitEthernet0/0/2]int g 0/0/3
[SW3-GigabitEthernet0/0/3]port link-type trunk
[SW3-GigabitEthernet0/0/3]port trunk allow-pass vlan all3、在交换机和路由器之间配置hybird
[SW1-GigabitEthernet0/0/3]int g 0/0/4
[SW1-GigabitEthernet0/0/4]port hybrid tagged vlan 2
[SW1-GigabitEthernet0/0/4]port hybrid untagged vlan 3 to 64、配置DHCP
[R1]int g 0/0/0.1
[R1-GigabitEthernet0/0/0.1]dot1q termination vid 2
[R1-GigabitEthernet0/0/0.1]ip address 192.168.1.1 24
[R1-GigabitEthernet0/0/0.1]arp broadcast enable[R1]int g 0/0/0
[R1-GigabitEthernet0/0/0]ip address 192.168.2.1 24[R1]dhcp enable
[R1]ip policy-based-route refresh-time [R1]ip pool aaa
[R1-ip-pool-aaa]network 192.168.1.0 mask 24
[R1-ip-pool-aaa]gateway-list 192.168.1.1[R1]ip pool bbb
[R1-ip-pool-bbb]network 192.168.2.0 mask 24
[R1-ip-pool-bbb]gateway-list 192.168.2.1 [R1]int g 0/0/0.1
[R1-GigabitEthernet0/0/0.1]dhcp select global
[R1-GigabitEthernet0/0/0.1]int g 0/0/0
[R1-GigabitEthernet0/0/0]dhcp select global5、在PC上用DHCP获取地址
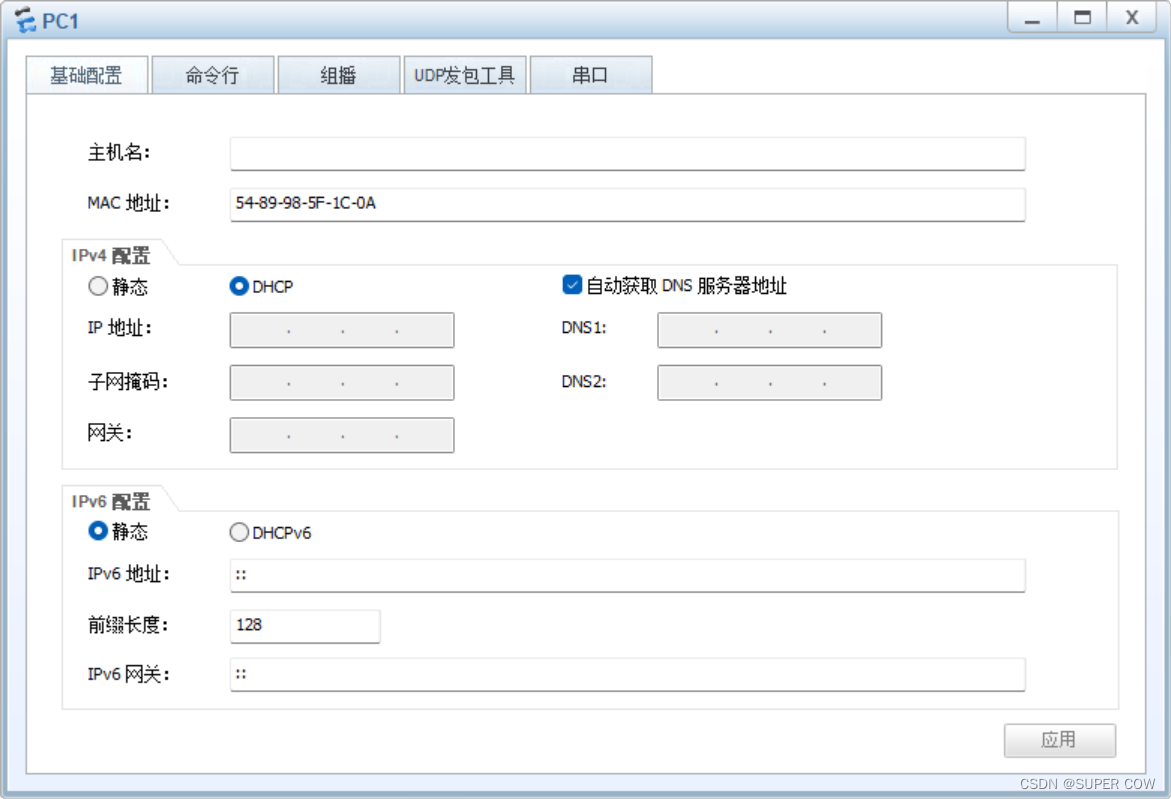
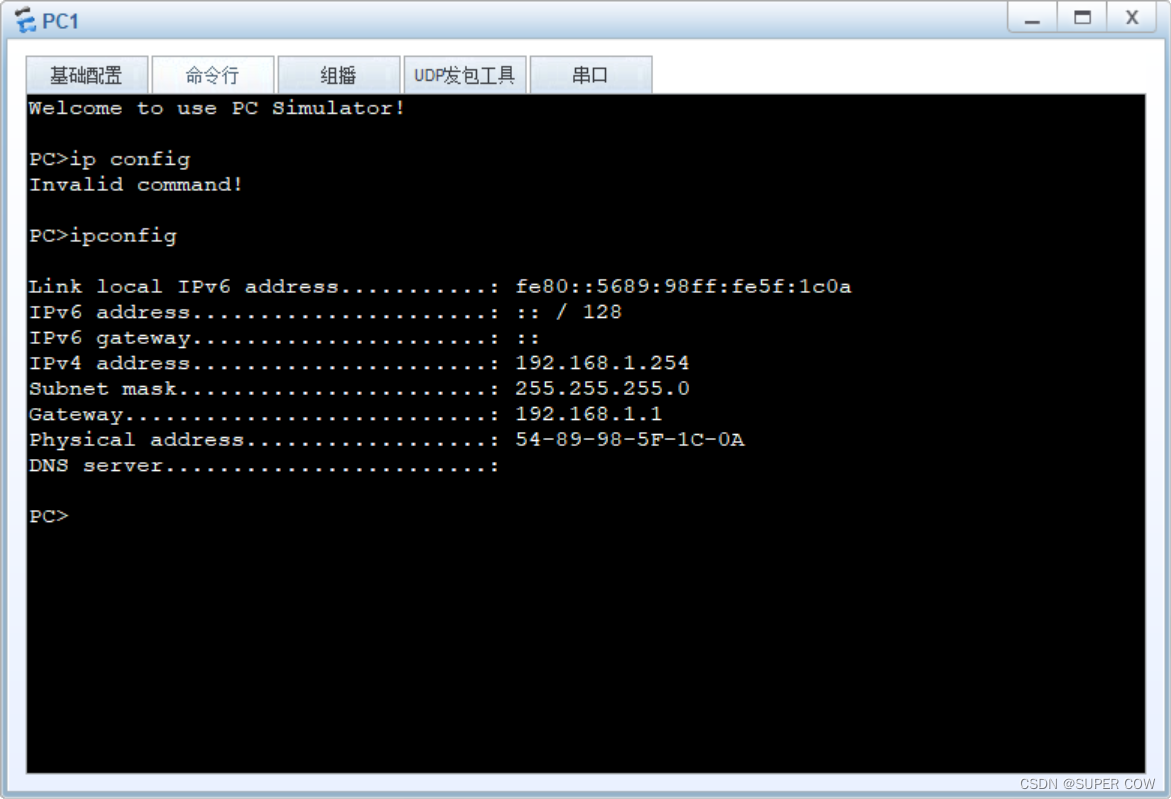
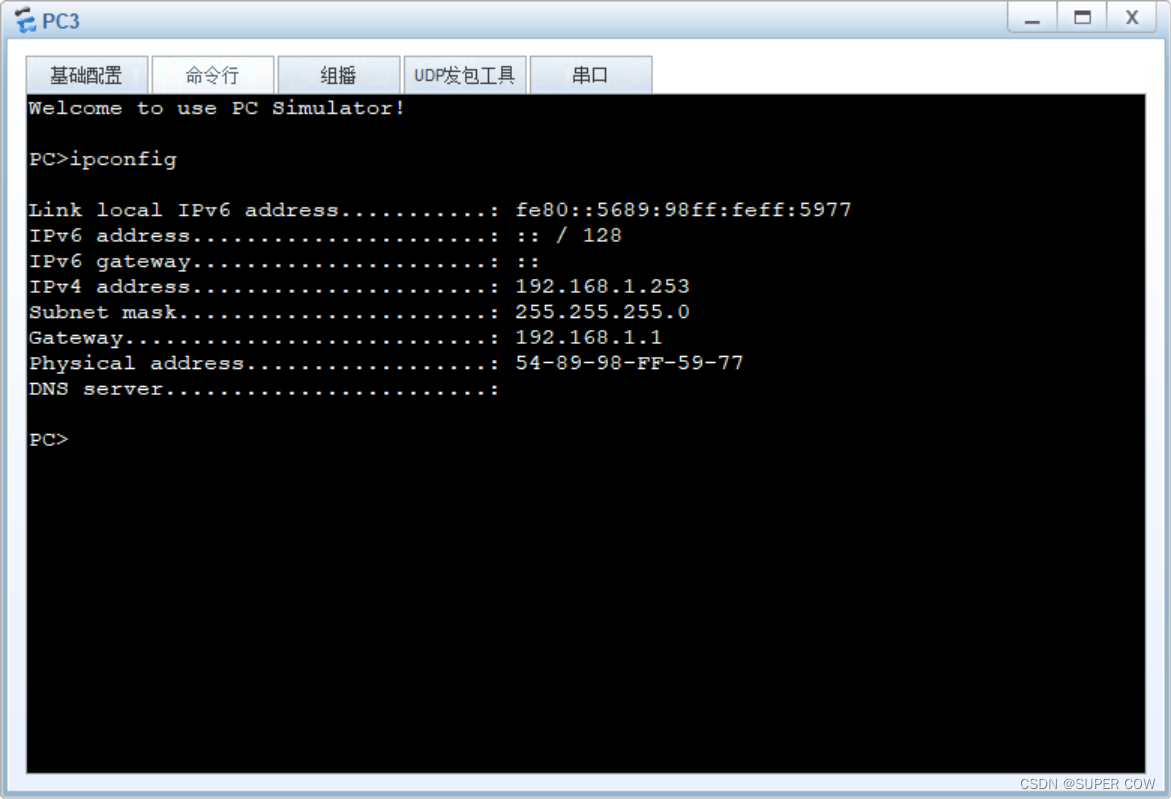
……
剩余PC均使用此方法进行DHCP地址获取, 不一一展示
5、验证