wordpress做管理网站网页设计师培训班大连
介绍
概述
Spring Boot Admin是一个监控工具,旨在以一种漂亮且易于访问的方式可视化Spring Boot Actuators提供的信息。
主要功能点
- 显示应用程序的监控状态
- 应用程序上下线监控
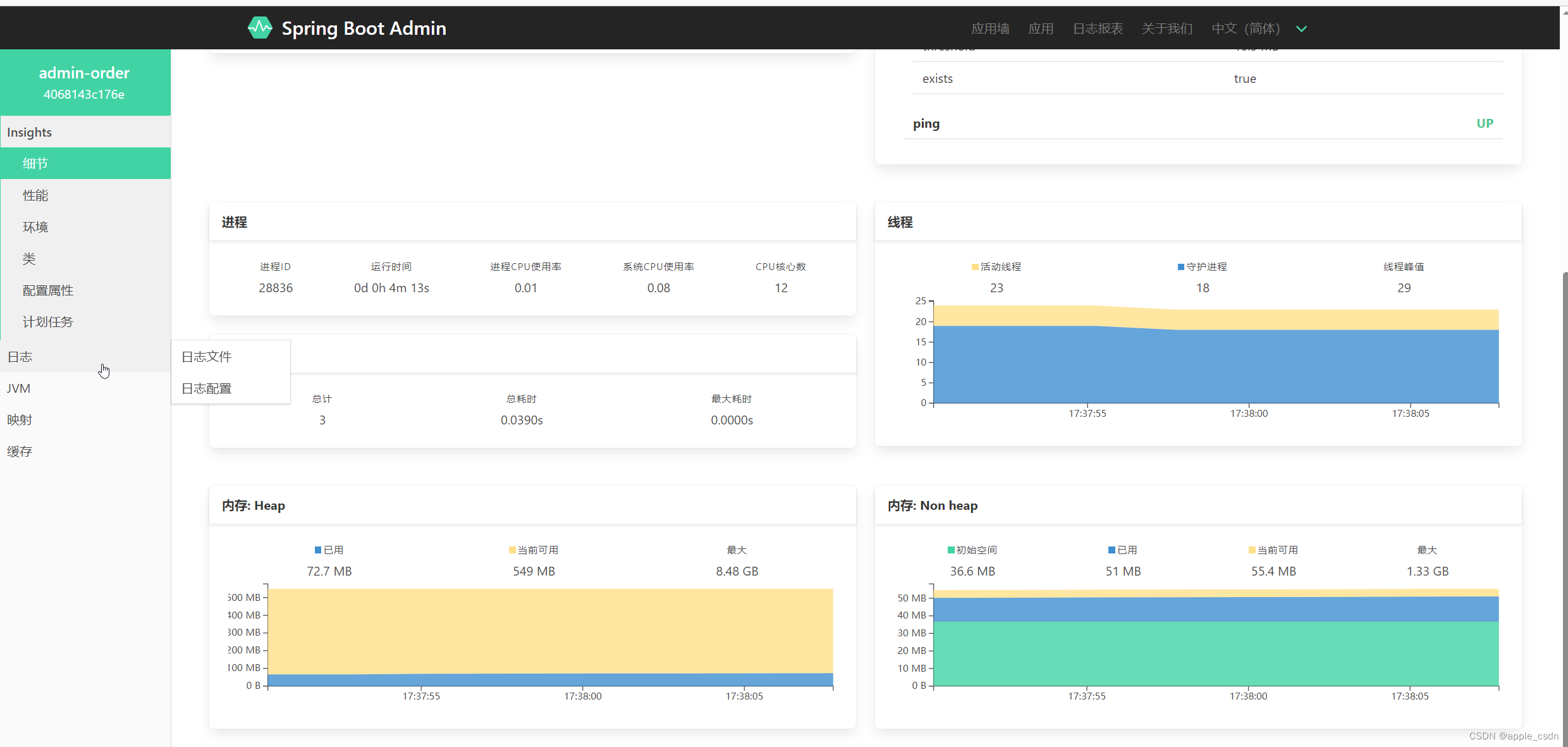
- 查看 JVM,线程信息
- 可视化的查看日志以及下载日志文件
- 动态切换日志级别
- Http 请求信息跟踪
- 其他功能点……
相关网址推荐:GitHub仓库、官方文档
创建Spring Boot Admin监控平台和客户端服务
Spring Boot Admin 监控平台服务
pom依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>de.codecentric</groupId><artifactId>spring-boot-admin-starter-server</artifactId><version>2.6.11</version></dependency></dependencies><dependencyManagement><dependencies><!--Spring Boot 相关依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.3</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
yml配置
server:port: 18000spring:application:name: admin-server
启动类@EnableAdminServer
package com.admin;import de.codecentric.boot.admin.server.config.EnableAdminServer;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@EnableAdminServer
@SpringBootApplication
public class AdminServerApplication {public static void main(String[] args) {SpringApplication.run(AdminServerApplication.class,args);}
}
服务启动成功后,访问链接:http://127.0.0.1:18000,查看监控平台。
客户端服务
pom依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>de.codecentric</groupId><artifactId>spring-boot-admin-starter-client</artifactId><version>2.6.11</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.14</version><scope>provided</scope></dependency></dependencies><dependencyManagement><dependencies><!--Spring Boot 相关依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.3</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
yml配置
spring:application:name: admin-order# spring boot adminboot:admin:client:url: http://127.0.0.1:18000instance:prefer-ip: truename: ${spring.application.name}server:port: 18001# endpoints config
management:endpoints:web:exposure:include: "*"endpoint:health:show-details: alwayslogging:# 只有配置了日志文件,才能被监控收集file:name: logs/${spring.application.name}/${spring.application.name}.log
启动类
package com.admin;import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@Slf4j
@SpringBootApplication
public class AdminOrderApp {public static void main(String[] args) {SpringApplication.run(AdminOrderApp.class, args);}
}
服务启动成功后,访问监控平台,就能监控admin-order服务了。
注意:如果监控平台上没有看见客户端服务,则需要重启Spring Boot Admin 监控服务
控制台展示
其他功能(专栏中其他文档)
【Spring Boot Admin】使用(整合Spring Cloud服务)
【Spring Boot Admin】使用(整合Spring Security服务,添加鉴权)
参考连接:Spring Boot Admin 介绍及使用