商派商城网站建设公司织梦动漫网站模板
文章目录
- 前言
- 具体实现截图
- 论文参考
- 详细视频演示
- 为什么选择我
- 自己的网站
- 自己的小程序(小蔡coding)
- 代码参考
- 数据库参考
- 源码获取
前言
💗博主介绍:✌全网粉丝10W+,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗
👇🏻 精彩专栏 推荐订阅👇🏻
2023-2024年最值得选的微信小程序毕业设计选题大全:100个热门选题推荐✅2023-2024年最值得选的Java毕业设计选题大全:500个热门选题推荐✅
Java精品实战案例《500套》
微信小程序项目精品案例《500套》
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
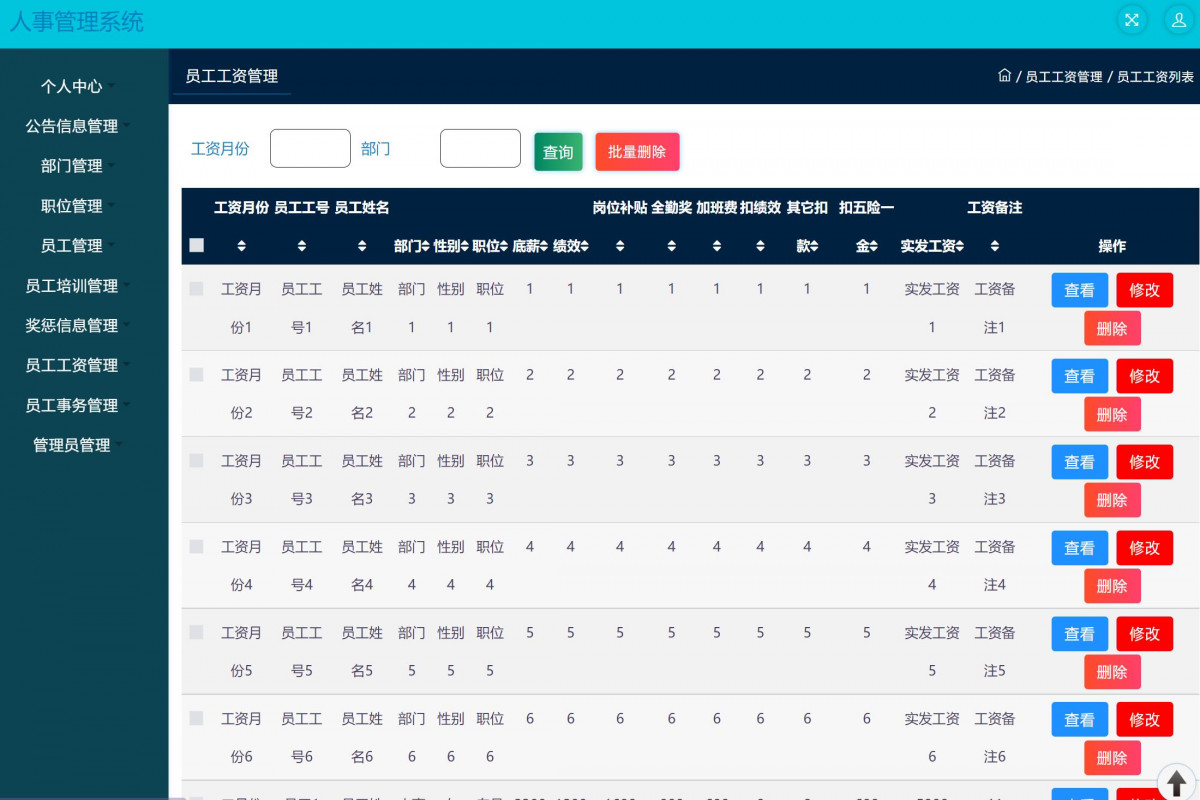
具体实现截图
主要功能:
基于java(ssm)人事管理系统
系统分为员工和管理员两个角色
员工的主要功能有:
1.员工登陆系统
2.个人中心:修改密码和个信息
3.公告查看:员工查看公司的公告信息
4.员工培训:员工查看公司的员工培训信息
5.奖惩信息: 员工查看公司的奖惩信息列表
6.员工工资:员工查看工资信息
7.员工事务管理:员工查询,添加,修改个人的公司事务信息
8.退出登陆
管理员的主要功能有:
1.管理员输入账户登陆后台
2.个人中心:管理员修改密码和个人信息
3.公告信息:管理员对公告信息进行添加,修改,删除,查询
4.部门管理:管理员对公司部门进行添加,修改,删除,查询
5.职位管理:管理员对公司职位进行添加,修改,查询,删除
6.员工管理:管理员对公司的员工信息进行添加,修改,删除,查询,发放工资
7.员工培训:管理员对公司员工培训进行添加,修改,删除,查询
8.奖惩管理: 管理员对公司员工的奖惩进行查询,添加,修改,删除
9.工资管理:管理员对公司员工的工资进行查询,修改,删除
10.员工事务管理:管理员对公司员工的事务审核,查看,修改,删除
11.管理员管理,可以添加,修改,删除管理员信息
12.退出登陆

论文参考



详细视频演示
请联系我获取更详细的演示视频
为什么选择我
自己的网站

网站上传的项目均为博主自己收集和开发的,质量都可以得到保障,适合自己懂一点程序开发的同学使用!
自己的小程序(小蔡coding)
为了方便同学们使用,我开发了小程序版的,名字叫小蔡coding。同学们可以通过小程序快速搜索和定位到自己想要的程序
代码参考
@IgnoreAuth
@PostMapping(value = "/login")
public R login(String username, String password, String captcha, HttpServletRequest request) {UsersEntity user = userService.selectOne(new EntityWrapper<UsersEntity>().eq("username", username));if(user==null || !user.getPassword().equals(password)) {return R.error("账号或密码不正确");}String token = tokenService.generateToken(user.getId(),username, "users", user.getRole());return R.ok().put("token", token);
}@Overridepublic String generateToken(Long userid,String username, String tableName, String role) {TokenEntity tokenEntity = this.selectOne(new EntityWrapper<TokenEntity>().eq("userid", userid).eq("role", role));String token = CommonUtil.getRandomString(32);Calendar cal = Calendar.getInstance(); cal.setTime(new Date()); cal.add(Calendar.HOUR_OF_DAY, 1);if(tokenEntity!=null) {tokenEntity.setToken(token);tokenEntity.setExpiratedtime(cal.getTime());this.updateById(tokenEntity);} else {this.insert(new TokenEntity(userid,username, tableName, role, token, cal.getTime()));}return token;}/*** 权限(Token)验证*/
@Component
public class AuthorizationInterceptor implements HandlerInterceptor {public static final String LOGIN_TOKEN_KEY = "Token";@Autowiredprivate TokenService tokenService;@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {//支持跨域请求response.setHeader("Access-Control-Allow-Methods", "POST, GET, OPTIONS, DELETE");response.setHeader("Access-Control-Max-Age", "3600");response.setHeader("Access-Control-Allow-Credentials", "true");response.setHeader("Access-Control-Allow-Headers", "x-requested-with,request-source,Token, Origin,imgType, Content-Type, cache-control,postman-token,Cookie, Accept,authorization");response.setHeader("Access-Control-Allow-Origin", request.getHeader("Origin"));// 跨域时会首先发送一个OPTIONS请求,这里我们给OPTIONS请求直接返回正常状态if (request.getMethod().equals(RequestMethod.OPTIONS.name())) {response.setStatus(HttpStatus.OK.value());return false;}IgnoreAuth annotation;if (handler instanceof HandlerMethod) {annotation = ((HandlerMethod) handler).getMethodAnnotation(IgnoreAuth.class);} else {return true;}//从header中获取tokenString token = request.getHeader(LOGIN_TOKEN_KEY);/*** 不需要验证权限的方法直接放过*/if(annotation!=null) {return true;}TokenEntity tokenEntity = null;if(StringUtils.isNotBlank(token)) {tokenEntity = tokenService.getTokenEntity(token);}if(tokenEntity != null) {request.getSession().setAttribute("userId", tokenEntity.getUserid());request.getSession().setAttribute("role", tokenEntity.getRole());request.getSession().setAttribute("tableName", tokenEntity.getTablename());request.getSession().setAttribute("username", tokenEntity.getUsername());return true;}PrintWriter writer = null;response.setCharacterEncoding("UTF-8");response.setContentType("application/json; charset=utf-8");try {writer = response.getWriter();writer.print(JSONObject.toJSONString(R.error(401, "请先登录")));} finally {if(writer != null){writer.close();}}
// throw new EIException("请先登录", 401);return false;}
}
数据库参考
-- ----------------------------
-- Table structure for token
-- ----------------------------
DROP TABLE IF EXISTS `token`;
CREATE TABLE `token` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`userid` bigint(20) NOT NULL COMMENT '用户id',`username` varchar(100) NOT NULL COMMENT '用户名',`tablename` varchar(100) DEFAULT NULL COMMENT '表名',`role` varchar(100) DEFAULT NULL COMMENT '角色',`token` varchar(200) NOT NULL COMMENT '密码',`addtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '新增时间',`expiratedtime` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '过期时间',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=27 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='token表';-- ----------------------------
-- Records of token
-- ----------------------------
INSERT INTO `token` VALUES ('9', '23', 'cd01', 'xuesheng', '学生', 'al6svx5qkei1wljry5o1npswhdpqcpcg', '2023-02-23 21:46:45', '2023-03-15 14:01:36');
INSERT INTO `token` VALUES ('10', '11', 'xh01', 'xuesheng', '学生', 'fahmrd9bkhqy04sq0fzrl4h9m86cu6kx', '2023-02-27 18:33:52', '2023-03-17 18:27:42');
INSERT INTO `token` VALUES ('11', '17', 'ch01', 'xuesheng', '学生', 'u5km44scxvzuv5yumdah2lhva0gp4393', '2023-02-27 18:46:19', '2023-02-27 19:48:58');
INSERT INTO `token` VALUES ('12', '1', 'admin', 'users', '管理员', 'h1pqzsb9bldh93m92j9m2sljy9bt1wdh', '2023-02-27 19:37:01', '2023-03-17 18:23:02');
INSERT INTO `token` VALUES ('13', '21', 'xiaohao', 'shezhang', '社长', 'zdm7j8h1wnfe27pkxyiuzvxxy27ykl2a', '2023-02-27 19:38:07', '2023-03-17 18:25:20');
INSERT INTO `token` VALUES ('14', '27', 'djy01', 'xuesheng', '学生', 'g3teq4335pe21nwuwj2sqkrpqoabqomm', '2023-03-15 12:56:17', '2023-03-15 14:00:16');
INSERT INTO `token` VALUES ('15', '29', 'dajiyue', 'shezhang', '社长', '0vb1x9xn7riewlp5ddma5ro7lp4u8m9j', '2023-03-15 12:58:08', '2023-03-15 14:03:48');
源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏👇🏻
Java精品实战案例《500套》
微信小程序项目精品案例《500套》