福州 网站建设漂亮的学校网站模板下载
GNSS信号频段
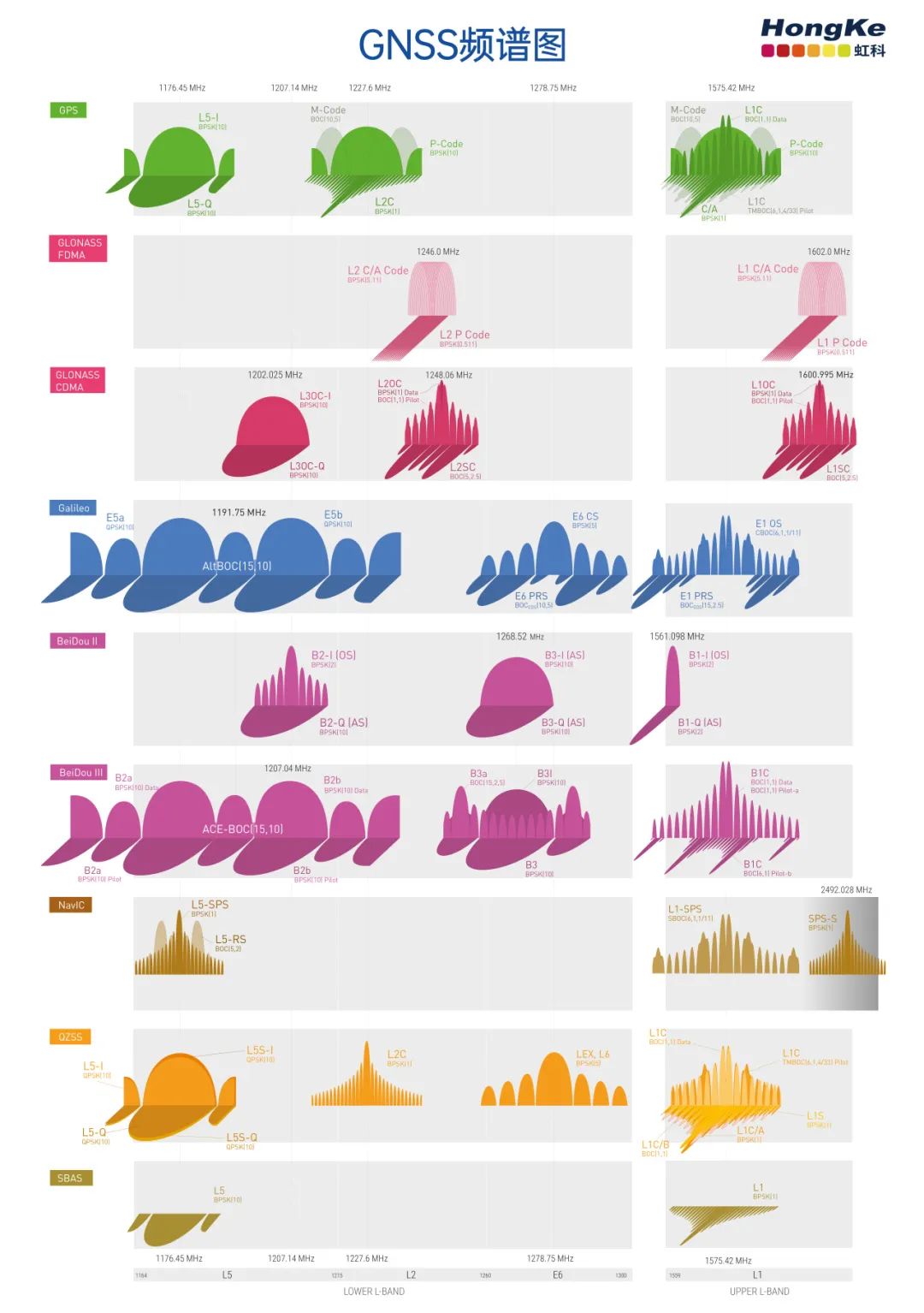
GNSS频谱图展示了不同的GNSS信号及其星座、载波频率、调制方案,以及所有这些信号在同一L波段频段内如何相互关联,是GNSS专业人员的必备工具,包括设计和开发GNSS系统的工程师,以及测试GNSS系统的工程师。
GNSS术语
星座(Constellation):构成特定系统的一组卫星。GPS、GLONASS、Galileo、BeiDou、IRNSS(NAViC)和QZSS都被认为是独立的星座。
信号(Signal):信号由载波频率、测距码和导航数据组成。一颗卫星通常会传输多个信号,例如,一颗GPS III卫星传输八种不同的GPS信号(L1C/A、L1C、L2C、L5、L1P(Y)、L1M、L2P(Y)、L2M)。
载波频率(Carrier Frequency):固定频率的传输,该频率经过更改或调制以“承载”数据。频率以赫兹(每秒循环数)为单位测量。在GNSS模拟器中指的是GNSS信号的精确载波频率。对于GPS L1C/A信号,载波频率为 1575.42MHz。
频段(Frequency Band):GNSS频率通常称为频段。所有GNSS频率都符合国际电信联盟(ITU)定义的L1、L2、L5或L6频段。这些所有的信号频段被规划得足够近,这样一个接收器就可以接收所有信号,但又不会靠得太近以至于它们相互干扰。尽管GPS L1C/A、GLONASS G1、伽利略E1和北斗B1信号可能具有不同的载波频率,但它们都位于L1频段。
PRN码(PRN Code):伪随机噪声码,也称为测距码或扩频码,是用于生成GNSS信号扩频的相移序列,接收机使用PRN码恢复原始信号并测量到卫星的距离。有多种类型的代码用于不同的星座和信号。
调制类型(Modulation Types):GNSS中使用相位调制将PRN代码和导航消息数据传送到接收器的载波频率上。GNSS信号最常用的调制技术是二进制相移键控(BPSK),而较新的信号使用二进制偏移载波(BOC)调制方案。
服务(Services):来自同一个星座的不同信号或信号组合可用于不同的服务。对于GPS,有标准定位服务(SPS)和精确定位服务(PPS)两种,SPS适用于所有用户,而PPS则用于军事应用。伽利略有四种服务:开放服务(OS)、高精度服务(HAS)、公共监管服务(PRS)和搜救(SAR)。其他星座也提供不同的服务,比如北斗目前提供七种服务:
- 定位导航授时服务:全球范围实测定位精度水平方向优于2.5米,垂直方向优于5.0米,测速精度优于0.2米/秒,授时精度优于20纳秒。
- 全球短报文服务:通过14颗MEO卫星为全球用户提供试用服务,最大单次报文长度560比特,约40个汉字。
- 国际搜救服务:6颗MEO卫星搭载搜救载荷,在符合国际标准的基础上,提供北斗特色B2b返向链路确认功能,为全球用户提供遇险报警服务。
- 区域短报文服务:最大单次报文长度14000比特,约1000个汉字,而具有区域短报文功能的智能手机将进入市场。
- 精密单点定位服务:通过3颗GEO卫星播发精密单点定位信号,定位精度实测水平方向优于20厘米,高程优于35厘米。
- 星基增强服务:支持单频及双频多星座两种增强服务模式,满足国际民航组织技术验证要求。目前星基增强系统服务平台已基本建成,正面向民航、海事、铁路等高完好性用户提供试运行服务。
- 地基增强服务:已在中国全境内建设框架网基准站和区域网基准站,面向行业和大众用户提供实时厘米级、事后毫米级定位增强服务。
GNSS模拟器是基于仿真的手段,结合软件定义的高级架构,在GNSS仿真的基础上更进一步,推出“依托软件引擎,开放硬件平台,高效开放的完成GNSS仿真”的Skydel GNSS仿真引擎方案,并借助该引擎推出适合于HIL测试的GSG-7与复杂场景与多实例测试的GSG-8。虹科Safran GSG-8提供最新定位、导航和计时测试解决方案,在一个易于使用、可升级和可扩展的平台上提供了最高标准的全球导航卫星系统(GNSS)信号测试和传感器模拟性能。它具有1000Hz的模拟迭代率、高动态性、实时同步,以及对所有卫星信号的模拟。
特征
- 灵活的软件定义平台
- 超高动态
- 强大的自动化
- 航空航天模拟
- 自定义波形