开发网站的财务分析wordpress文章和博客的区别
天行健,君子以自强不息;地势坤,君子以厚德载物。
每个人都有惰性,但不断学习是好好生活的根本,共勉!
文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。
文章目录
- 一、准备表格数据
- 二、读取表格数据
- 1. 引入所需库
- 2. 读取文件数据
- 3. 打印模型数据
- 三、将多图画在一个平面上展示
- 1. 获取模型中的列字段数量
- 2. 遍历列字段并画图
- 3. 展示平面图
- 4. 保存图片
- 四、完整代码
- 六、执行后的输出展示
- 1. 控制带输出
- 2. 画图结果输出
- 3. 保存的视图查看
关于python读取Excel表格数据并并画图保存简单实现可参考:
Python读取Excel表格数据并画图保存(pandas读取、matplotlib画图)
如何将多个图画在同一个平面上展示,如下
文章所需excel表格文件和完整代码文件已打包上传到CSDN资源库,点击链接直接获取
Python matplotlib画图 pandas表格数据读取 将多个图画在同一个平面内
一、准备表格数据
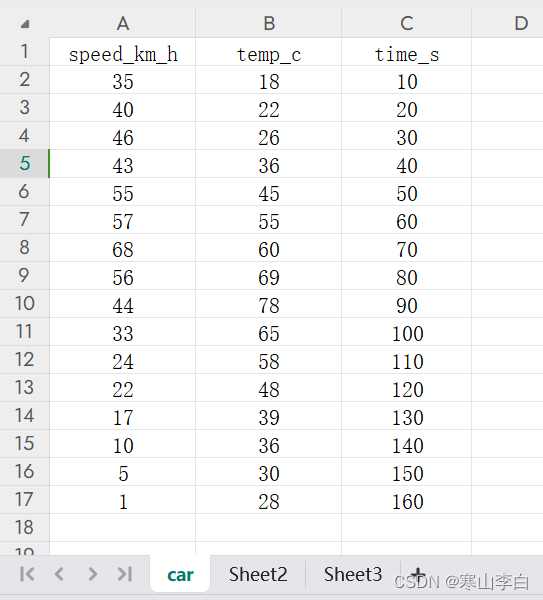
准备一个Excel文件,并填充数据
创建文件test01.xlsx
将sheet页名称该位car
填充三个字段speed_km_h、temp_c、time_s
填充数据,如下图
二、读取表格数据
读取表格中的数据,并将读取的模型数据打印输出到控制台
注:需提前下载对应的库信息,可参考文首文章链接
1. 引入所需库
引入pandas库用于读取表格文件
引入matplotlib库用于画图
#引入pandas用于读取
import pandas as pd
#引入matplotlib用于画图
import matplotlib.pyplot as plt
2. 读取文件数据
通过pandas库的函数读取表格文件数据
#使用pandas读取excel表,可指定sheet页的名字
df = pd.read_excel("./test01.xlsx",sheet_name="car")
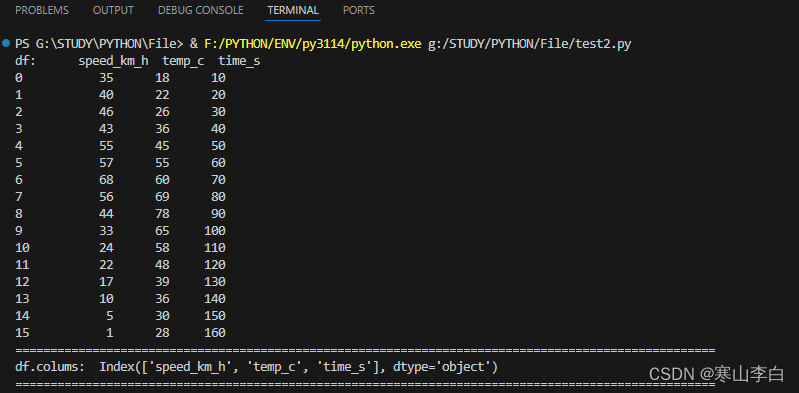
3. 打印模型数据
打印模型数据
#打印读取的模型
print("df: ",df)print("="*100)
输出如下
三、将多图画在一个平面上展示
1. 获取模型中的列字段数量
根据前面读取的数据模型,获取模型中列字段的个数,后续根据列的个数决定输出图的个数
#打印出新模型的列字段数量
field = df.columns.size
print(field)
2. 遍历列字段并画图
根据列字段进行画图,先选择一个字段作为横坐标,然后将所有字段当做纵坐标进行画图
#遍历模型的所有字段
for i, item in enumerate(list(df.columns)):#打印字段值print(i, item)print("="*100)# if item == "time_s":# continue#定义打印视图的参数,field表示线形图的数量,1表示将线形图放在一个图中,i+1表示遍历打印视图,该参数不能为0,所以需要加一plt.subplot(field, 1, i+1)#打印,以tims_s为横轴,三个字段speed_km_h、time_s、temp_c为纵轴画图plt.plot(df["time_s"], df[item])
3. 展示平面图
将整个平面图展示出来
#将整个视图展示
plt.show()
4. 保存图片
在展示的函数show()之前使用savefig()保存图片
# 保存图片到本地,保存在当前位置,以jpg格式存储
filename = "car"
plt.savefig(f"./{filename}.jpg")
四、完整代码
以下为完整代码
#引入pandas用于读取
import pandas as pd
#引入matplotlib用于画图
import matplotlib.pyplot as plt#需要下载openpyxl,pandas#使用pandas读取excel表,可指定sheet页的名字
df = pd.read_excel("./test01.xlsx",sheet_name="car")#打印读取的模型
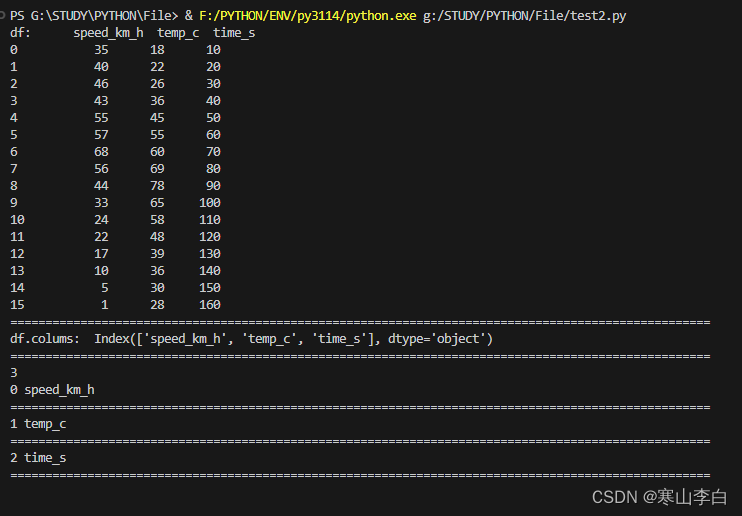
print("df: ",df)print("="*100)#打印表头字段
print("df.colums: ",df.columns)print("="*100)#打印出新模型的列字段数量
field = df.columns.size
print(field)#遍历模型的所有字段
for i, item in enumerate(list(df.columns)):#打印字段值print(i, item)print("="*100)# if item == "time_s":# continue#定义打印视图的参数,field表示线形图的数量,1表示将线形图放在一个图中,i+1表示遍历打印视图,该参数不能为0,所以需要加一plt.subplot(field, 1, i+1)#打印,以tims_s为横轴,三个字段speed_km_h、time_s、temp_c为纵轴画图plt.plot(df["time_s"], df[item])# 保存图片到本地,保存在当前位置,以jpg格式存储
filename = "car"
plt.savefig(f"./{filename}.jpg")#将整个视图展示
plt.show()
六、执行后的输出展示
执行完整代码,查看输出结果
1. 控制带输出
控制台输出如下
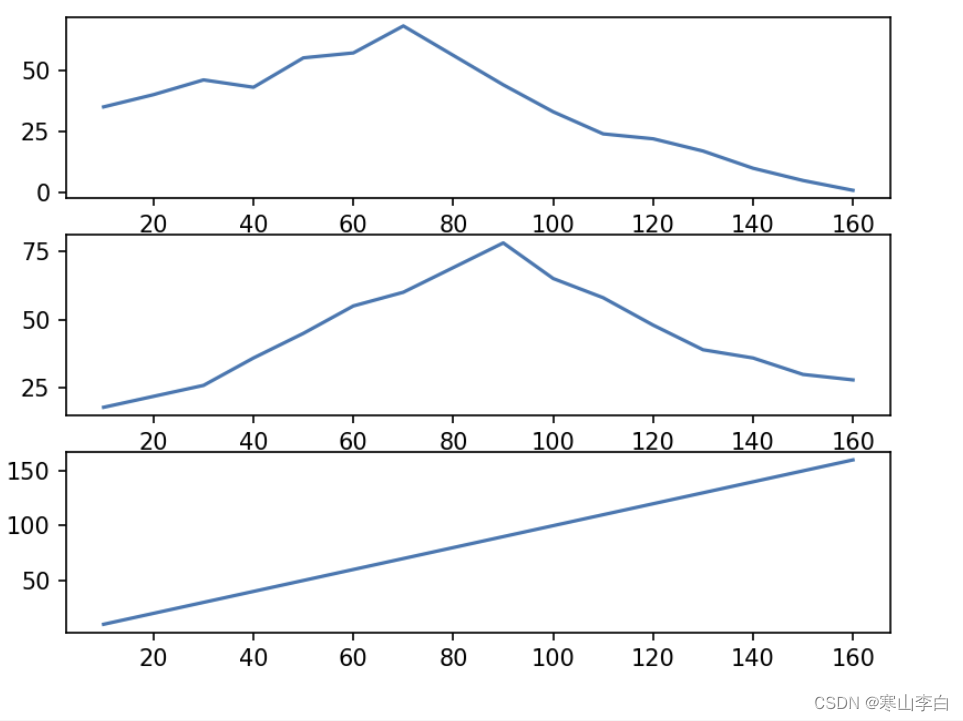
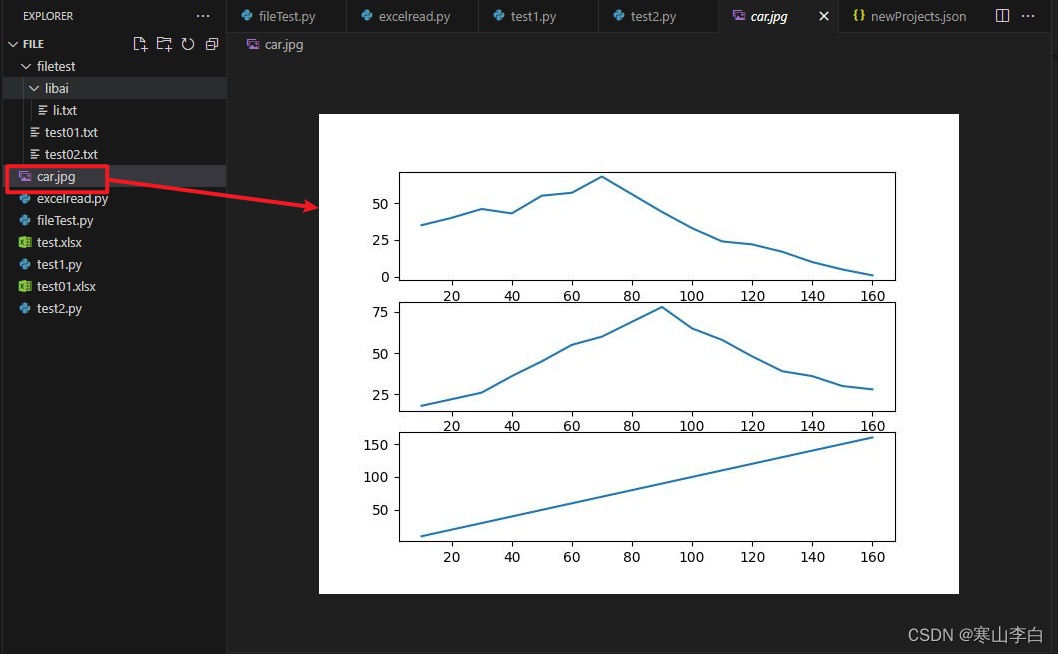
2. 画图结果输出
画图结果输出如下,横轴为时间,纵轴为三个字段,三个图在同一平面展示

3. 保存的视图查看
如图所示,保存位置为当前位置,名称为car.jpg,内容如下
感谢阅读,祝君暴富!