wordpress 锚点定位公司网站关键词优化怎么做
1. 断点续传简介
在文件的下载中,特别是大文件的下载中,可能会出现各种原因导致的下载暂停情况,如果不做特殊处理,下次还需要从头开始下载,既浪费了时间,又浪费了流量。不过,HTTP协议通过Range首部提供了对文件分块下载的支持,也就是说可以指定服务器返回文件特定范围的数据,这就为我们实现文件的断点续传提供了基础。RCP也很好的封装了这一点,通过Request对象的transferRange属性,可以支持分块下载,transferRange可以是TransferRange或者TransferRange数组,TransferRange类型包括两个属性from和to:
from?: number; to?: number;
from用于设置传输数据的起始字节,to用于设置传输数据的结束字节。
有了RCP的支持,就比较容易实现文件的断点续传,本文将通过一个示例进行演示。
2.断点续传下载文件示例
本示例运行后的界面如图所示:

首选输入要下载文件的URL,这里默认是下载的百度网盘的安装文件,大概98M左右,然后单击“选择”按钮选择本地保存路径,如下图所示:
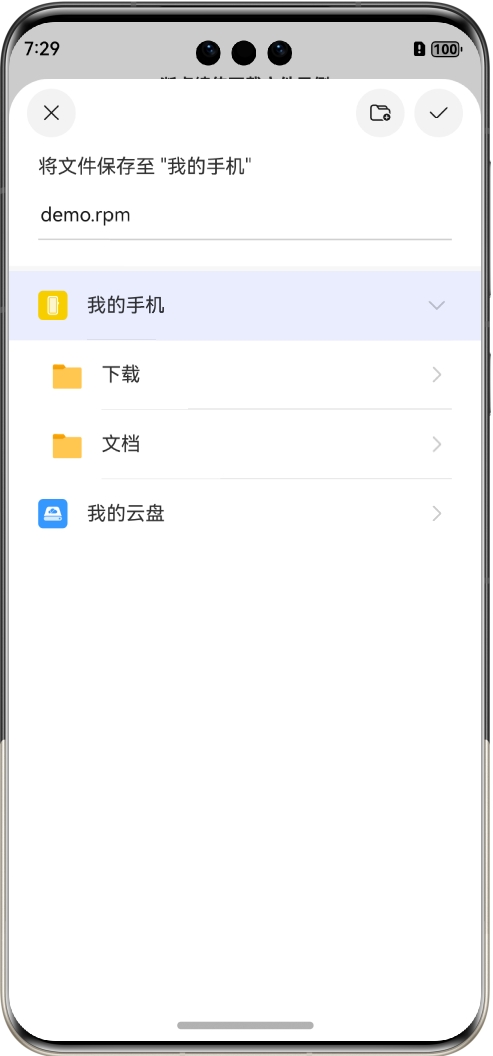
选择保存的文件名称为demo.rpm,然后回到主界面,单击“下载”按钮就行下载:
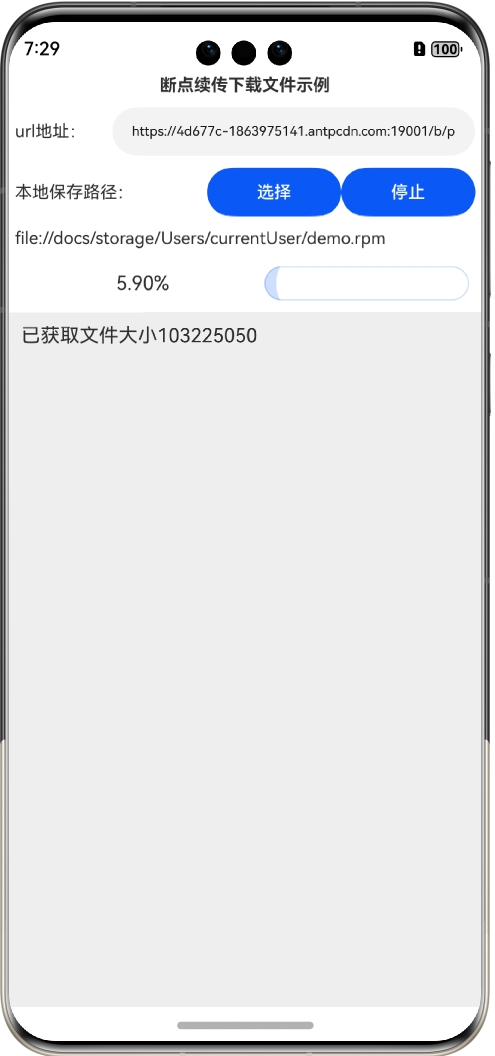
如果要停止就可以单击“停止”按钮:
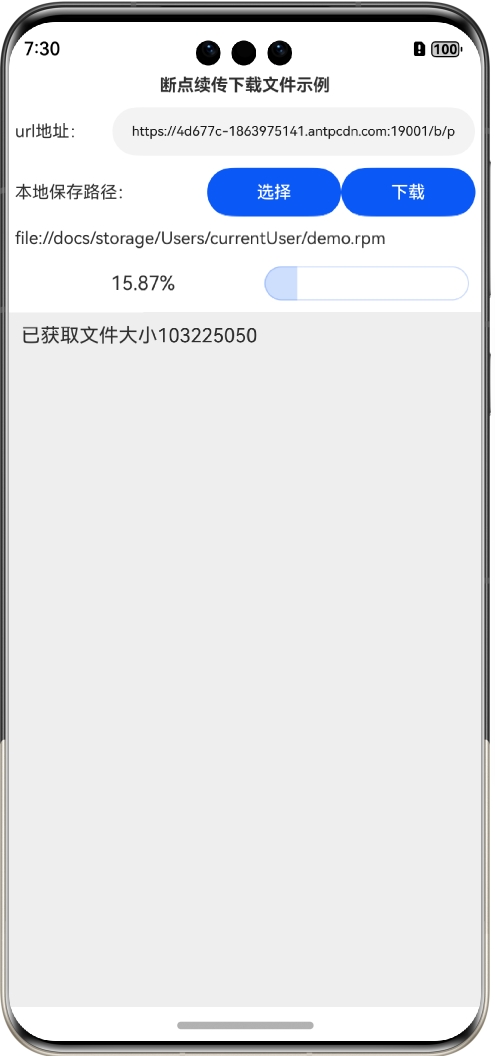
停止后可以单击“下载”按钮继续下载,或者也可以停止后退出应用:
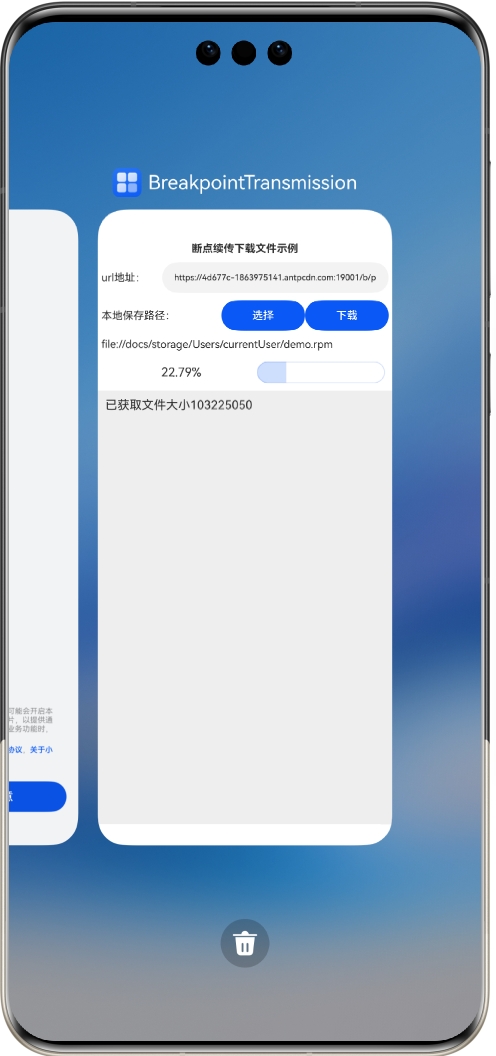
重启启动后还会保持上传退出时的状态:
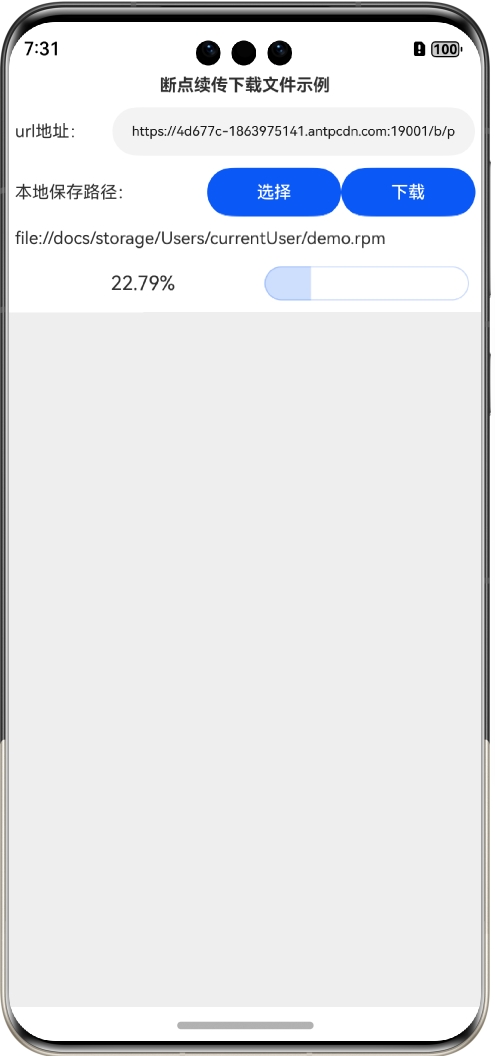
此时单击“下载”按钮还可以接着上次的进度继续下载,直到下载完成:
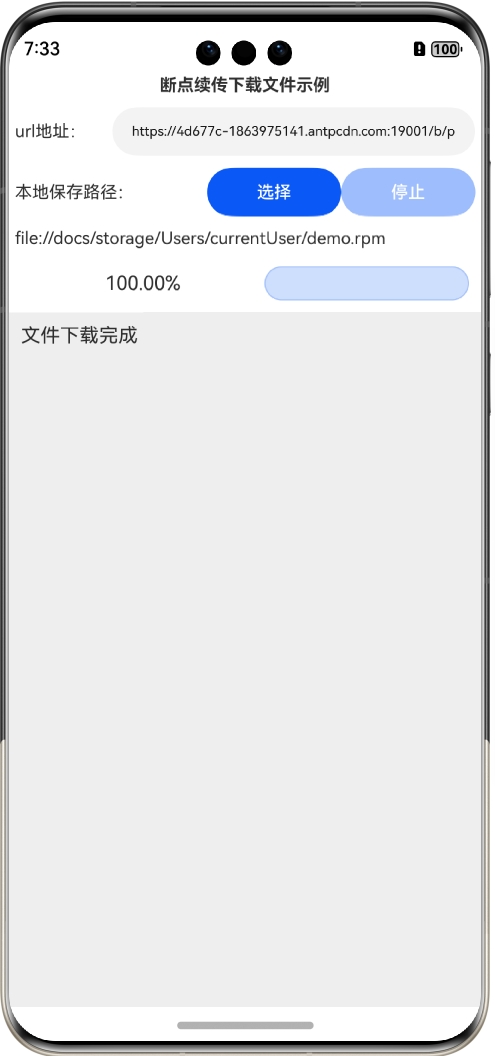
这样,就实现了任意时候中断下载或者退出应用都不影响已下载的部分,下次可以继续下载,实现了真正的断点续传。
3.断点续传下载文件示例编写
步骤1:创建Empty Ability项目。
步骤2:在module.json5配置文件加上对权限的声明
"requestPermissions": [{"name": "ohos.permission.INTERNET"}]
这里添加了访问互联网的权限。
步骤3:在Index.ets文件里添加如下的代码:
import fs from '@ohos.file.fs';
import { rcp } from '@kit.RemoteCommunicationKit';
import { getSaveFilePath} from './FileProcessHelper';
import { PersistenceV2 } from '@kit.ArkUI';
import { picker } from '@kit.CoreFileKit';
@ObservedV2//下载信息
class DownloadFileInfo {@Trace public url: string = "";@Trace public filePath: string = "";//任务状态//0:未开始 1:部分下载 2:下载完成@Trace public state: number = 0;@Trace public totalSize: number = 0;@Trace public downloadedSize: number = 0;
constructor(url: string, filePath: string) {this.url = urlthis.filePath = filePath}
}
@Entry
@ComponentV2
struct Index {@Local title: string = '断点续传下载文件示例';//连接、通讯历史记录@Local msgHistory: string = ''//每次下载的字节数downloadPerBatchSize: number = 64 * 1024defaultUrl ="https://4d677c-1863975141.antpcdn.com:19001/b/pkg-ant.baidu.com/issue/netdisk/LinuxGuanjia/4.17.7/baidunetdisk_4.17.7_x86_64.rpm"//是否正在下载@Local isRunning: boolean = false
//断点续传下载文件信息,使用PersistenceV2进行持久化存储@Local downloadFileInfo: DownloadFileInfo = PersistenceV2.connect(DownloadFileInfo,() => new DownloadFileInfo(this.defaultUrl, ""))!scroller: Scroller = new Scroller()
//当前会话currentSession: rcp.Session = rcp.createSession();//当前请求currentReq: rcp.Request | undefined = undefined
build() {Row() {Column() {Text(this.title).fontSize(14).fontWeight(FontWeight.Bold).width('100%').textAlign(TextAlign.Center).padding(5)
Flex({ justifyContent: FlexAlign.Start, alignItems: ItemAlign.Center }) {Text("url地址:").fontSize(14).width(80).flexGrow(0)
TextInput({ text: this.downloadFileInfo.url }).onChange((value) => {this.downloadFileInfo.url = value}).width(110).fontSize(11).flexGrow(1)}.width('100%').padding(5)
Flex({ justifyContent: FlexAlign.SpaceBetween, alignItems: ItemAlign.Center }) {Text("本地保存路径:").fontSize(14).width(80).flexGrow(1)
Button("选择").onClick(async () => {this.downloadFileInfo.filePath = await getSaveFilePath(getContext(this))if (fs.accessSync(this.downloadFileInfo.filePath)) {fs.unlinkSync(this.downloadFileInfo.filePath)}}).width(110).fontSize(14)
Button(this.isRunning ? "停止" : "下载").onClick(() => {if (this.isRunning) {this.isRunning = falsethis.currentSession.cancel(this.currentReq)} else {this.downloadFile()}
}).enabled(this.downloadFileInfo.filePath != "" && this.downloadFileInfo.state != 2).width(110).fontSize(14)}.width('100%').padding(5)
Text(this.downloadFileInfo.filePath).fontSize(14).width('100%').padding(5)
Flex({ justifyContent: FlexAlign.Start, alignItems: ItemAlign.Center }) {Column() {Text(`${(this.downloadFileInfo.totalSize == 0 ? 0 :((this.downloadFileInfo.downloadedSize / this.downloadFileInfo.totalSize) * 100).toFixed(2))}%`)}.width(200)
Column() {Progress({value: this.downloadFileInfo.downloadedSize,total: this.downloadFileInfo.totalSize,type: ProgressType.Capsule})}.width(150).flexGrow(1)}.visibility(this.downloadFileInfo.state != 0 ? Visibility.Visible : Visibility.None).width('100%').padding(10)
Scroll(this.scroller) {Text(this.msgHistory).textAlign(TextAlign.Start).padding(10).width('100%').backgroundColor(0xeeeeee)}.align(Alignment.Top).backgroundColor(0xeeeeee).height(300).flexGrow(1).scrollable(ScrollDirection.Vertical).scrollBar(BarState.On).scrollBarWidth(20)}.width('100%').justifyContent(FlexAlign.Start).height('100%')}.height('100%')}
//获取要下载的文件大小async getDownloadFileSize() {let size = 0const session = rcp.createSession();let resp = await session.head(this.downloadFileInfo.url)if (resp.statusCode != 200) {return 0;}if (resp.headers["content-length"] != undefined) {size = Number.parseInt(resp.headers["content-length"].toString())}this.msgHistory += `已获取文件大小${size}\r\n`return size;}
//下载到文件async downloadFile() {//如果文件大小为0,就获取文件大小if (this.downloadFileInfo.totalSize == 0) {this.downloadFileInfo.totalSize = await this.getDownloadFileSize()if (this.downloadFileInfo.totalSize == 0) {this.msgHistory += "获取文件大小失败\r\n"return}}
this.isRunning = truethis.downloadFileInfo.state = 1//每次下载的开始位置和结束位置let startIndex = this.downloadFileInfo.downloadedSizelet endIndex = startIndex + this.downloadPerBatchSizelet localFile = fs.openSync(this.downloadFileInfo.filePath, fs.OpenMode.READ_WRITE)fs.lseek(localFile.fd, 0, fs.WhenceType.SEEK_END)
//循环下载, 直到文件下载完成while (this.downloadFileInfo.downloadedSize < this.downloadFileInfo.totalSize && this.isRunning) {if (endIndex >= this.downloadFileInfo.totalSize) {endIndex = this.downloadFileInfo.totalSize - 1}let partDownloadResult = await this.downloadPartFile(startIndex, endIndex, localFile)if (!partDownloadResult) {return}
this.downloadFileInfo.downloadedSize += endIndex - startIndex + 1startIndex = endIndex + 1endIndex = startIndex + this.downloadPerBatchSize}
if (this.downloadFileInfo.downloadedSize == this.downloadFileInfo.totalSize) {this.downloadFileInfo.state = 2this.msgHistory += "文件下载完成\r\n"}fs.closeSync(localFile.fd)}
//下载指定范围的文件并追加写入到本地文件async downloadPartFile(from: number, to: number, localFile: fs.File): Promise<boolean> {this.currentReq = new rcp.Request(this.downloadFileInfo.url, "GET");this.currentReq.transferRange = { from: from, to: to }let resp = await this.currentSession.fetch(this.currentReq)
if (resp.statusCode != 200 && resp.statusCode != 206) {this.msgHistory += `服务器状态响应异常,状态码${resp.statusCode}\r\n`return false}
if (resp.body == undefined) {this.msgHistory += "服务器响应数据异常\r\n"return false}
if (resp.body.byteLength != to - from + 1) {this.msgHistory += "服务器响应的数据长度异常\r\n"return false}
fs.writeSync(localFile.fd, resp.body)fs.fsyncSync(localFile.fd)return true}
//选择文件保存位置async getSaveFilePath(): Promise<string> {let selectedSaveFilePath: string = ""let documentSaveOptions = new picker.DocumentSaveOptions();let documentPicker = new picker.DocumentViewPicker(getContext(this));await documentPicker.save(documentSaveOptions).then((result: Array<string>) => {selectedSaveFilePath = result[0]})return selectedSaveFilePath}
}步骤4:编译运行,可以使用模拟器或者真机。
步骤5:按照本节第2部分“断点续传下载文件示例”操作即可。
4. 断点续传功能分析
要实现断点续传功能,关键点在于事先获取文件的大小以及每次请求时获取文件的一部分数据,获取文件大小是通过函数getDownloadFileSize实现的,在这个函数里通过http的head方法可以只获取响应的首部,其中包括文件的大小;获取文件部分数据是通过设置请求的transferRange属性实现的:
this.currentReq = new rcp.Request(this.downloadFileInfo.url, "GET");this.currentReq.transferRange = { from: from, to: to }let resp = await this.currentSession.fetch(this.currentReq)
另外,示例支持应用退出以及重启后的断点续传,这一点是通过PersistenceV2实现的,把断点续传下载文件信息自动进行持久化存储,下次启动时还可以自动加载,从而实现了完全的文件断点续传。
当然,这个示例还有很多需要完善的地方,比如,可以在重启后的断点续传前重新获取文件大小,并且和本地进行比较,防止服务端文件发生变化。
(本文作者原创,除非明确授权禁止转载)
本文源码地址:
https://gitee.com/zl3624/harmonyos_network_samples/tree/master/code/rcp/RCPDownloadFileDemo
本系列源码地址:
https://gitee.com/zl3624/harmonyos_network_samples