赶集网站建设多少钱学习网页制作的网站
谷歌gmail邮箱账号注册手机号无法进行验证怎么办?
使用手机号码注册谷歌gmail邮箱账号时会遇到:此电话号码无法用于进行验证 或 此电话号码验证次数太多。造成注册google谷歌gmail邮箱账号受阻,无法正常完成注册。


谷歌Gmail邮箱账号正确的注册方法与教程?
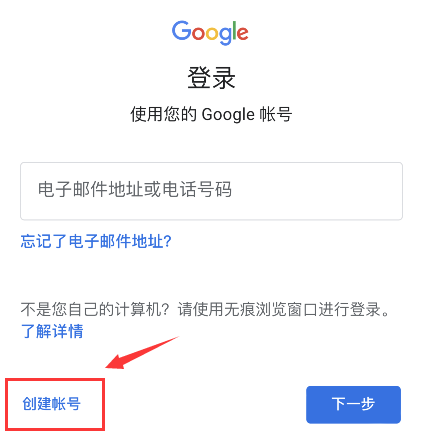
1、打开谷歌账号注册入口,点击“创建帐号”;
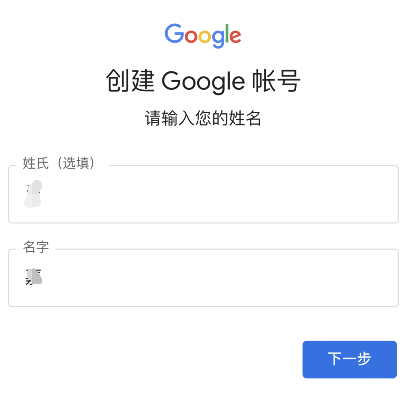
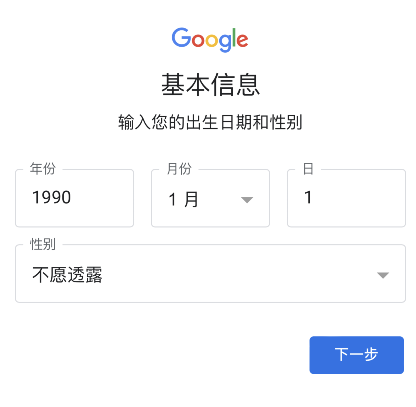
2、根据Google账号注册流程输入姓名、出生年月、性别、账号和密码等基本信息;
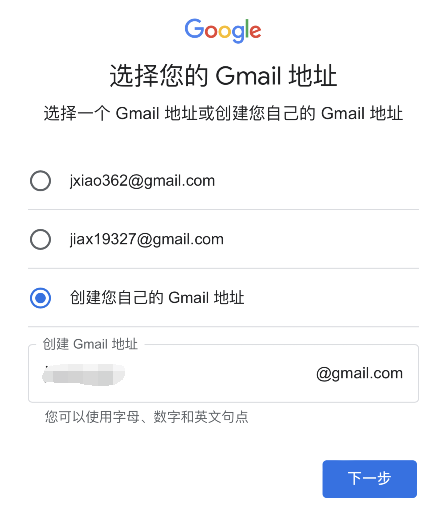

3、在电话号码输入框内,先输入+86,接着输入有效的手机号码,点击下一步就可以获得短信验证码;

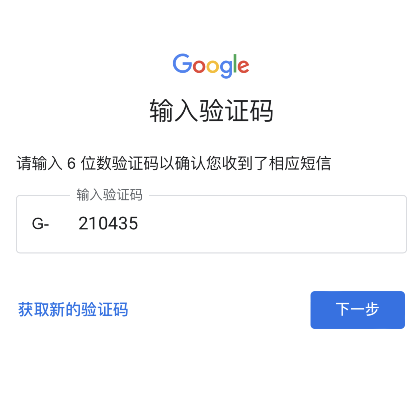
【重点】部分用户输入手机号码后无法接收验证码遇到提示如下:此电话号码无法用于进行验证 或 此电话号码验证次数太多。
如您无法继续完成谷歌gmail邮箱账号,请点击查看解决办法:https://www.caochai.com/article-538.html
4、完成短信验证,最后同意隐私权及条款就可以完成注册,获得有效的谷歌gmail邮箱账号;